
 Bo Bi, data engineer at Mafengwo
Bo Bi, data engineer at Mafengwo
During the joint Apache SeaTunnel & IoTDB Meetup on October 15, Bo Bi, the data engineer at a leading Chinese travel-social e-commerce platform Mafengwo, introduced the basic principles of SeaTunnel and related enterprise practice thinking, the pain points and optimization thinking in typical scenarios of Mafengwo’s big data development and scheduling platform, and shared his experience of participating in community contributions. We hope to help you understand SeaTunnel and the paths and skills of community building at the same time.
Introduction to the technical principle of SeaTunnel
SeaTunnel is a distributed, high-performance data integration platform for the synchronization and transformation of large volumes of data (offline and real-time)
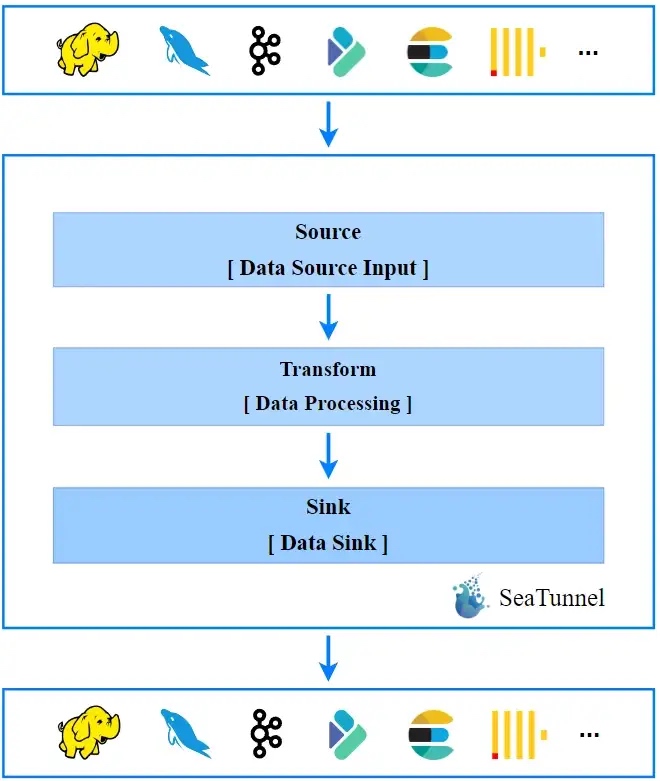
The diagram above shows the workflow of SeaTunnel, which in simple terms consists of 3 parts: input, transformation, and output; more complex data processing is just a combination of several actions.
In a synchronization scenario, such as importing Kafka to Elasticsearch, Kafka is the Source of the process and Elasticsearch is the Sink of the process.
If, during the import process, the field columns do not match the external data columns to be written and some column or type conversion is required, or if you need to join multiple data sources and then do some data widening, field expansion, etc., then you need to add some Transform in the process, corresponding to the middle part of the picture.
 This shows that the core of SeaTunnel is the Source, Transform and Sink process definitions.
This shows that the core of SeaTunnel is the Source, Transform and Sink process definitions.
In Source we can define the data sources we need to read, in Sink, we can define the data pipeline and eventually write the external storage, and we can transform the data in between, either using SQL or custom functions.
SeaTunnel Connector API Version V1 Architecture Breakdown
For a mature component framework, there must be something unique about the design pattern of the API design implementation that makes the framework scalable.
The SeaTunnel architecture consists of three main parts.
1、SeaTunnel Basic API.
the implementation of the SeaTunnel base API.
SeaTunnel’s plug-in system.
SeaTunnel Basic API
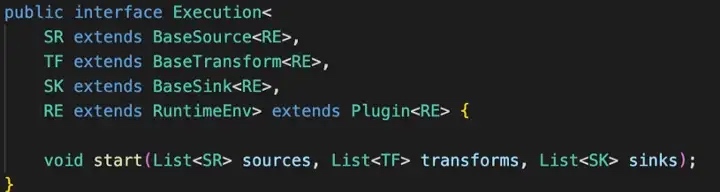
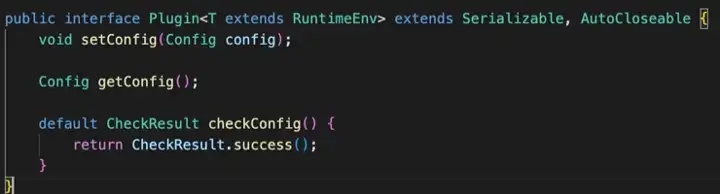 The above diagram shows the definition of the interface, the Plugin interface in SeaTunnel abstracts the various actions of data processing into a Plugin.
The above diagram shows the definition of the interface, the Plugin interface in SeaTunnel abstracts the various actions of data processing into a Plugin.
The five parts of the diagram below, Basesource, Basetransfform, Basesink, Runtimeenv, and Execution, all inherit from the Plugin interface.
As a process definition plug-in, Source is responsible for reading data, Transform is responsible for transforming, Sink is responsible for writing and Runtimeenv is setting the base environment variables.
The overall SeaTunnel base API is shown below
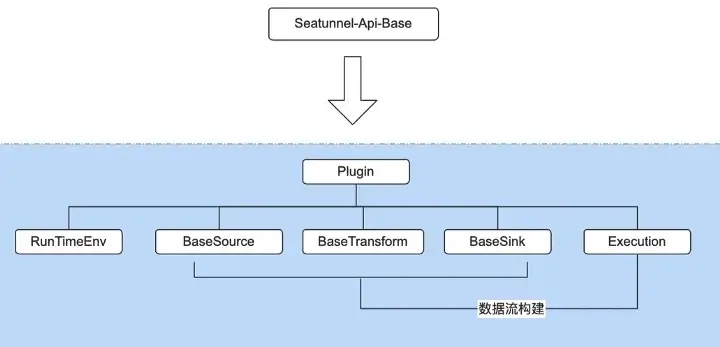 Execution, the data flow builder used to build the entire data flow based on the first three, is also part of the base API
Execution, the data flow builder used to build the entire data flow based on the first three, is also part of the base API
SeaTunnel Base API Implementation
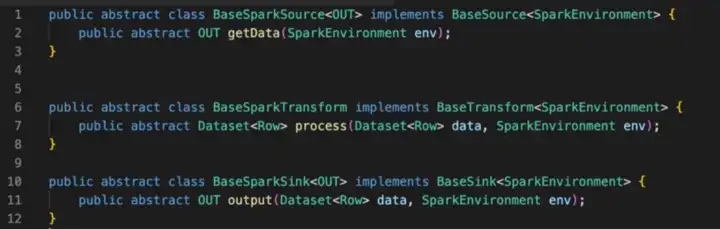
Based on the previous basic APIs, SeaTunnel has been implemented in separate packages for different computing engines, currently the Spark API abstraction and the Flink API abstraction, which logically completes the process of building the data pipeline.
Due to space constraints, we will focus on Spark batch processing. Based on the wrapped implementation of the previous base Api, the first is that Base spark source implements Base source, base Spark transform implements Base transform and Base Spark sink implements Base sink.
The method definition uses Spark’s Dataset as the carrier of the data, and all data processing is based on the Dataset, including reading, processing and exporting.
The SparkEnvironment, which internally encapsulates Spark’s Sparksession in an Env, makes it easy for individual plugins to use.
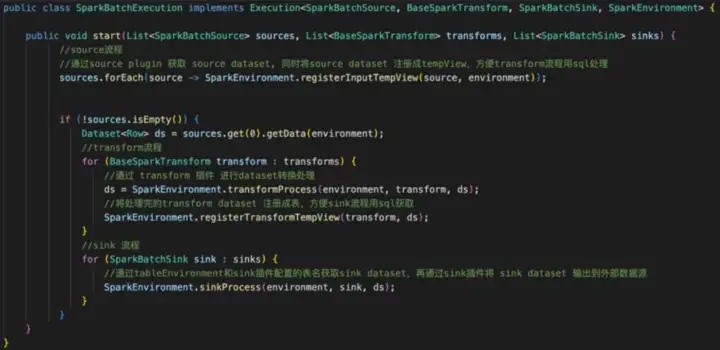
The Spark batch process ends with SparkBatchExecution (the data stream builder), which is the core code snippet used to functionally build our data stream Pipeline, the most basic data stream on the left in the diagram below.
The user-based definition of each process component is also the configuration of Source Sink, Transform. More complex data flow logic can be implemented, such as multi-source Join, multi-pipeline processing, etc., all of which can be built through Execution.

SeaTunnel Connector V1 API Architecture Summary
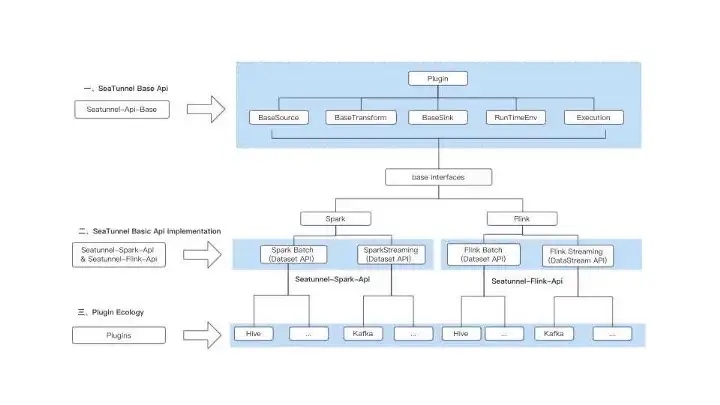 SeaTunnel’s API consists of three main parts.
SeaTunnel’s API consists of three main parts.
The first part is the SeaTunnel base API, which provides the basic abstract interfaces such as Source, Sink, Transform, and Plugin.
The second part is based on a set of interfaces Transform, Sink, Source, Runtime, and Execution provided by the SeaTunnel base API, which is wrapped and implemented on the Flink and Spark engines respectively, i.e. Spark engine API layer abstraction and Flink engine API layer abstraction.
Both Flink and Spark engines support stream and batch processing, so there are different ways to use streams/batches under the Flink API abstraction and Spark abstraction APIs, such as Flinkstream and Flinkbatch under the Flink abstraction API, and Sparkbatch and Sparkstreaming under the Spark abstraction API.
The third part is the plug-in system, based on Spark abstraction and Flink API abstraction, SeaTunnel engine implements rich connectors and processing plug-ins, while developers can also be based on different engine API abstractions, and extensions to achieve their own Plugin.
SeaTunnel Implementation Principle Currently, SeaTunnel offers a variety of ways to use Flink, Spark, and FlinkSQL. Due to space limitations, we will introduce the execution principles of the Spark method.
First, the entry starts the command Start-seatunnel-spark.sh via the shell, which internally calls Sparkstarter’s Class, which parses the parameters passed by the shell script, and also parses the Config file to determine which Connectors are defined in the Config file, such as Fake, Console, etc.
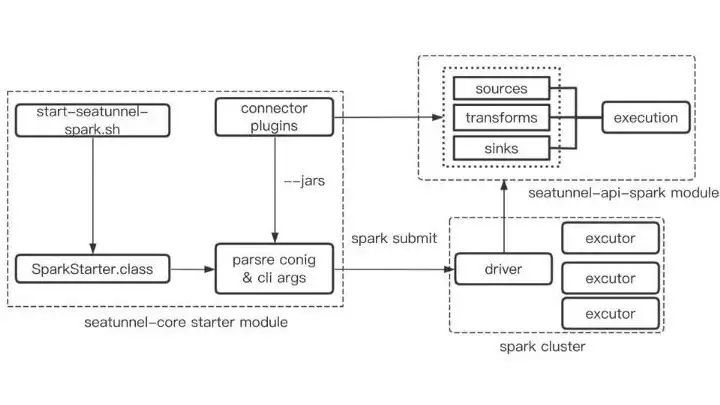 Then find the Connector path from the Connector plugin directory and stitch it into the Spark-submit launch command with — jar, so that the found Plugin jar package can be passed to the Spark cluster as a dependency.
Then find the Connector path from the Connector plugin directory and stitch it into the Spark-submit launch command with — jar, so that the found Plugin jar package can be passed to the Spark cluster as a dependency.
For Connector plugins, all Spark Connectors are packaged in the plugin directory of the distribution (this directory is managed centrally).
After Spark-submit is executed, the task is submitted to the Spark cluster, and the Main class of the Spark job’s Driver builds the data flow Pipeline through the data flow builder Execution, combined with Souce, Sink, and Transform so that the whole chain is connected.
SeaTunnel Connector V2 API Architecture
In the latest community release of SeaTunnel 2.2.0-beta, the refactoring of the Connectorapi, now known as the SeaTurnelV2 API, has been completed!
Why do we need to reconfigure?
As the Container is currently a strongly coupled engine, i.e. Flink and Spark API, if the Flink or Spark engine is upgraded, the Connector will also have to be adjusted, possibly with changes to parameters or interfaces.
This can lead to multiple implementations for different engines and inconsistent parameters to develop a new Connector. Therefore, the community has designed and implemented the V2 version of the API based on these pain points.
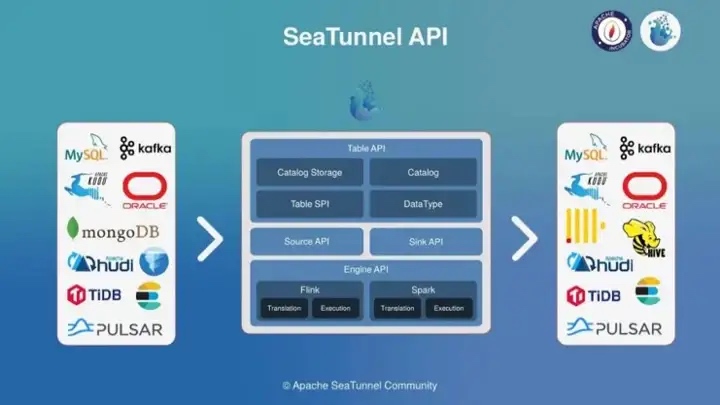
SeaTunnel V2 API Architecture
SeaTunnel V2 API Architecture
1.Table API
·DataType: defines SeaTunnel’s data structure SeaTunnelRow, which is used to isolate the engine
·Catalog: used to obtain Table Scheme, Options, etc..
·Catalog Storage: used to store user-defined Table Schemes etc. for unstructured engines such as Kafka.
·Table SPI: mainly used to expose the Source and Sink interfaces as an SPI
2. Source & Sink API
Define the Connector’s core programming interface for implementing the Connector
3.Engine API
·Translation: The translation layer, which translates the Source and Sink APIs implemented by the Connector into a runnable API inside the engine.
·Execution: Execution logic, used to define the execution logic of Source, Transform, Sink and other operations within the engine.
The Source & Sink API is the basis for the implementation of the connector and is very important for developers.
The design of the v2 Source & Sink API is highlighted below
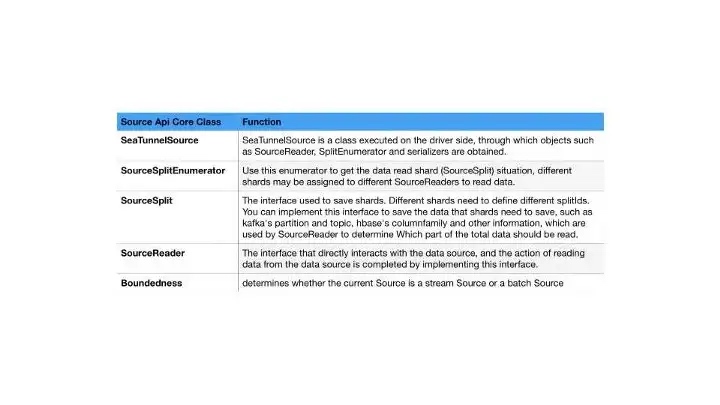
SeaTunnel Connector V2 Source API
The current version of SeaTunnel’s API design draws on some of Flink’s design concepts, and the more core classes of the Source API are shown below.
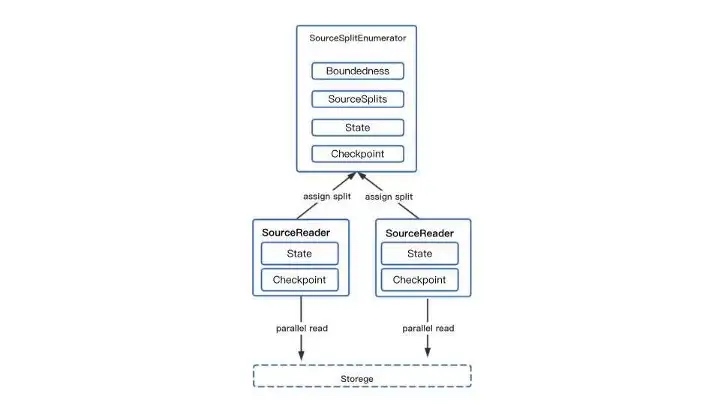 The core Source API interaction flow is shown above. In the case of concurrent reads, the enumerator SourceSplitEnumerator is required to split the task and send the SourceSplit down to the SourceReader, which receives the split and uses it to read the external data source.
The core Source API interaction flow is shown above. In the case of concurrent reads, the enumerator SourceSplitEnumerator is required to split the task and send the SourceSplit down to the SourceReader, which receives the split and uses it to read the external data source.
In order to support breakpoints and Eos semantics, it is necessary to preserve and restore the state, for example by preserving the current Reader’s Split consumption state and restoring it after a failure in each Reader through the Checkpoint state and Checkpoint mechanism, so that the data can be read from the place where it failed.
SeaTunnel Connector V2 Sink API
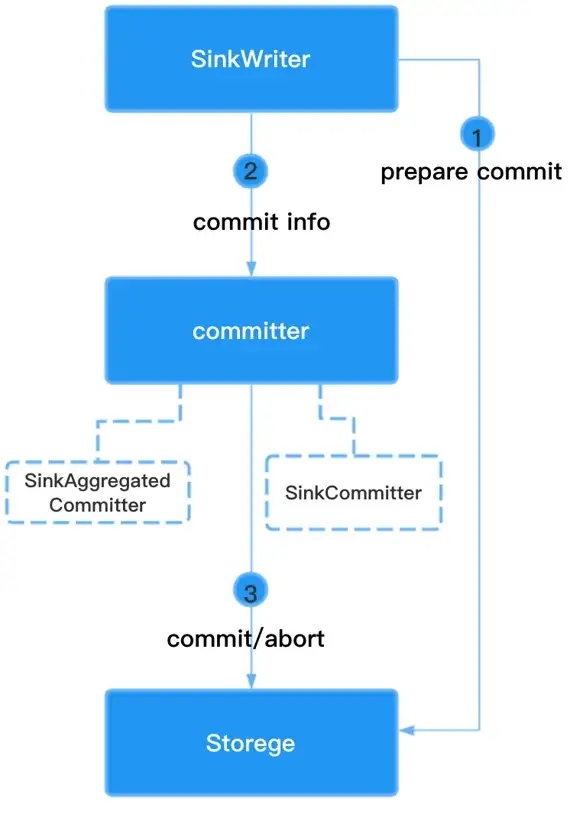
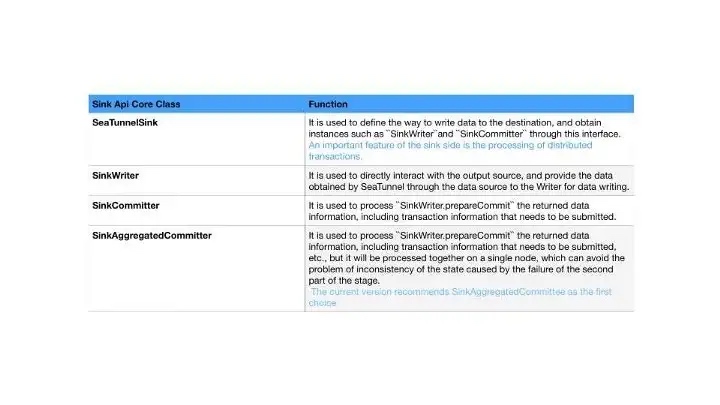 The overall Sink API interaction flow is shown in the diagram below. The SeaTunnel sink is currently designed to support distributed transactions, based on a two-stage transaction commit.
The overall Sink API interaction flow is shown in the diagram below. The SeaTunnel sink is currently designed to support distributed transactions, based on a two-stage transaction commit.
First SinkWriter continuously writes data to an external data source, then when the engine does a checkpoint, it triggers a first-stage commit.
SinkWriter needs to do a Prepare commit, which is the first stage of the commit.
The engine will determine if all the Writer's first stage succeeds, and if they all succeed, the engine will combine the Subtask’s Commit info with the Commit method of the Committer to do the actual commit of the transaction and operate the database for the Commit, i.e. the second stage of the commit. This is the second stage of commit.
 For the Kafka sink connector implementation, the first stage is to do a pre-commit by calling KafkaProducerSender.prepareCommit().
For the Kafka sink connector implementation, the first stage is to do a pre-commit by calling KafkaProducerSender.prepareCommit().
The second commit is performed via Producer.commitTransaction();.
flush(); flushes the data from the Broker’s system cache to disk.
Finally, it is worth noting!
Both SinkCommitter and SinkAggregatedCommitter can perform a second stage commit to replace the Committer in the diagram. The difference is that SinkCommitter can only do a partial commit of a single Subtask’s CommitInfo, which may be partially successful and partially unsuccessful, and cannot be handled globally. The difference is that the SinkCommitter can only do partial commits of a single Subtask’s CommitInfo, which may be partially successful and partially unsuccessful.
SinkAggregatedCommitter is a single parallel, aggregating the CommitInfo of all Subtask, and can do the second stage commit as a whole, either all succeed or all fail, avoiding the problem of inconsistent status due to partial failure of the second stage.
It is therefore recommended that the SinkAggregatedCommitter be used in preference.
Comparison of SeaTunnel V1 and V2 API processing flows
We can look at the changes before and after the V1 V2 upgrade from a data processing perspective, which is more intuitive, Spark batch processing as an example: SeaTunnel V1: The entire data processing process is based on the Spark dataset API, and the Connector and the compute engine are strongly coupled.
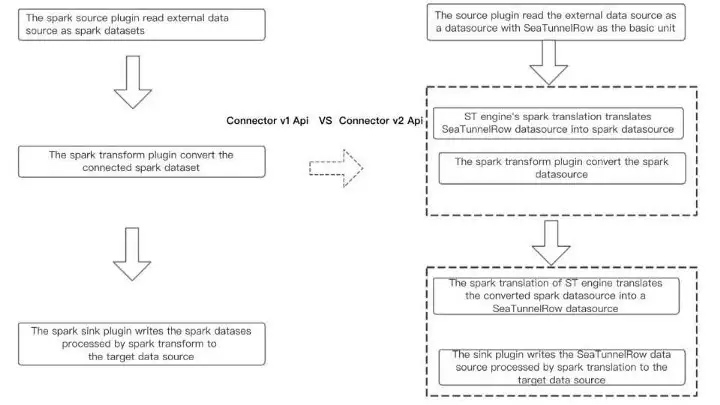 SeaTunnel V2: Thanks to the work of the engine translator, the Connector API, and the SeaTunnelRow, the data source of the SeaTunnel internal data structures accessed through the Connector, are translated by the translation layer into a runnable Spark API and spark dataset that is recognized inside the engine during data transformation.
SeaTunnel V2: Thanks to the work of the engine translator, the Connector API, and the SeaTunnelRow, the data source of the SeaTunnel internal data structures accessed through the Connector, are translated by the translation layer into a runnable Spark API and spark dataset that is recognized inside the engine during data transformation.
As data is written out, the Spark API and Spark dataset are translated through the translation layer into an executable connector API inside the SeaTunnel connector and a data source of internal SeaTunnel structures that can be used.
Overall, the addition of a translation layer at the API and compute engine layers decouples the Connector API from the engine, and the Connector implementation no longer depends on the compute engine, making the extension and implementation more flexible.
In terms of community planning, the V2 API will be the main focus of development, and more features will be supported in V2, while V1 will be stabilized and no longer maintained.
Practice and reflections on our off-line development scheduling platform
Practice and reflections on our off-line development scheduling platform
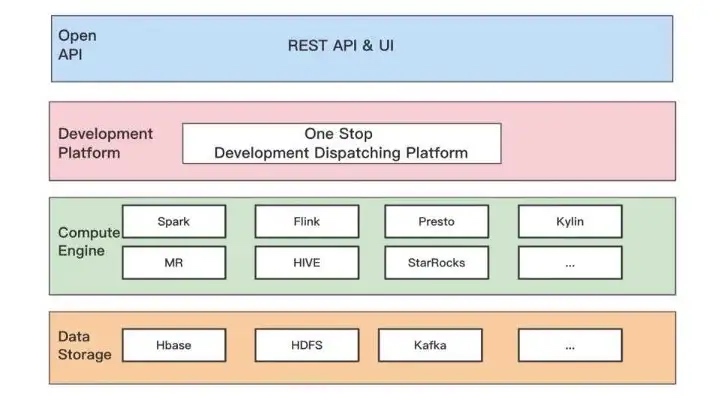 Hornet’s Nest Big Data Development Platform, which focuses on providing one-stop big data development and scheduling services, helps businesses solve complex problems such as data development management, task scheduling and task monitoring in offline scenarios.
Hornet’s Nest Big Data Development Platform, which focuses on providing one-stop big data development and scheduling services, helps businesses solve complex problems such as data development management, task scheduling and task monitoring in offline scenarios.
The offline development and scheduling platform plays the role of the top and the bottom. The top is to provide open interface API and UI to connect with various data application platforms and businesses, and the bottom is to drive various computations and storage, and then run in an orderly manner according to the task dependency and scheduling time.
Platform Capabilities
Data development
Task configuration, quality testing, release live
·Data synchronisation
Data access, data processing, data distribution
·Scheduling capabilities
Supports timed scheduling, triggered scheduling
·Operations and Maintenance Centre Job Diagnosis, Task O&M, Instance O&M
·Management
Library table management, permission management, API management, script management
In summary, the core capabilities of the offline development scheduling platform are openness, versatility, and one-stop shopping. Through standardized processes, the entire task development cycle is managed and a one-stop service experience is provided.
The architecture of the platform
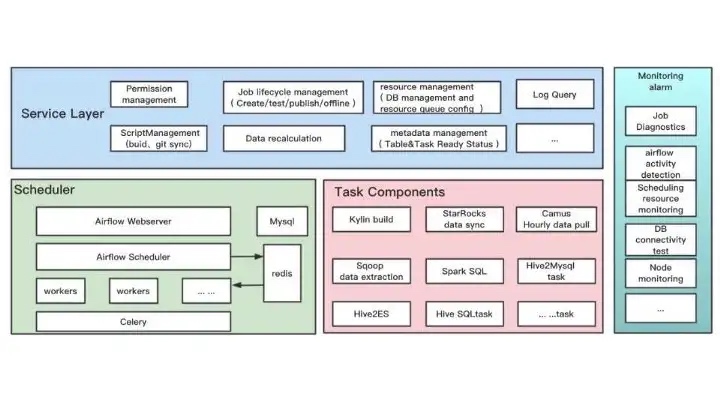 The Hornet’s Nest Big Data Development and Scheduling Platform consists of four main modules: the task component layer, the scheduling layer, the service layer, and the monitoring layer.
The Hornet’s Nest Big Data Development and Scheduling Platform consists of four main modules: the task component layer, the scheduling layer, the service layer, and the monitoring layer.
The service layer is mainly responsible for job lifecycle management (e.g. job creation, testing, release, offline); Airflow dagphthon file building and generating, task bloodline dependency management, permission management, API (providing data readiness, querying of task execution status).
The scheduling layer is based on Airflow and is responsible for the scheduling of all offline tasks.
A task component layer that enables users to develop data through supported components that include tools such as SparkSQL/, HiveSQ, LMR), StarRocks import, etc., directly interfacing with underlying HDFS, MySQL, and other storage systems.
The monitoring layer is responsible for all aspects of monitoring and alerting on scheduling resources, computing resources, task execution, etc.
Open Data Sync Capability Scenarios
Challenges with open capabilities: Need to support multiple business scenarios and meet flexible data pipeline requirements (i.e. extend to support more task components such as hive2clickhourse, clickhourse2mysql, etc.)
Extending task components based on Airflow: higher maintenance costs for extensions, need to reduce costs and increase efficiency (based on the limited provider's Airflow offers, less applicable in terms of usage requirements, Airflow is a Python technology stack, while our team is mainly based on the Java technology stack, so the technology stack difference brings higher iteration costs)
Self-developed task components: the high cost of platform integration, long development cycle, high cost of the configuration of task components. (Research or implement task components by yourself, different ways of adapting the parameters of the components in the service layer, no uniform way of parameter configuration)
We wanted to investigate a data integration tool that, firstly, supported a rich set of components, provided out-of-the-box capabilities, was easy to extend, and offered a uniform configuration of parameters and a uniform way of using them to facilitate platform integration and maintenance.
- Selection of data integration tools
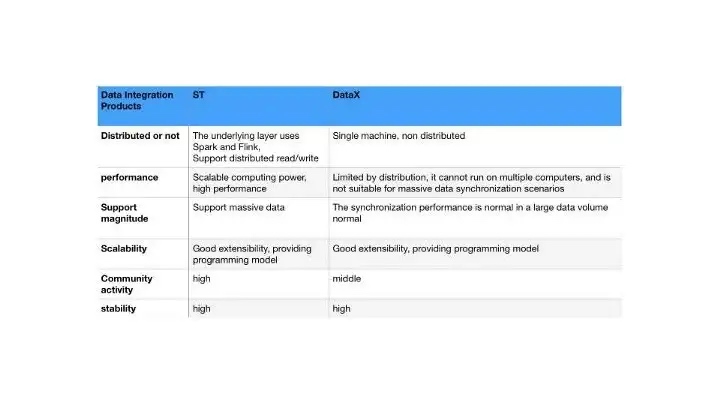 To address the pain points mentioned above, we actively explored solutions and conducted a selection analysis of several mainstream data integration products in the industry. As you can see from the comparison above, Datax and SeaTunnel both offer good scalability, and high stability, support rich connector plugins, provide scripted, uniformly configurable usage, and have active communities.
To address the pain points mentioned above, we actively explored solutions and conducted a selection analysis of several mainstream data integration products in the industry. As you can see from the comparison above, Datax and SeaTunnel both offer good scalability, and high stability, support rich connector plugins, provide scripted, uniformly configurable usage, and have active communities.
However, Datax is limited by being distributed and is not well suited to massive data scenarios.
In contrast, SeaTunnel offers the ability to provide distributed execution, distributed transactions, scalable levels of data handling, and the ability to provide a unified technical solution in data synchronization scenarios.
In addition to the advantages and features described above and the applicable scenarios, more importantly, the current offline computing resources for big data are unified and managed by yarn, and for the subsequently extended tasks we also wish to execute on Yarn, we finally prefer SeaTunnel for our usage scenarios.
Further performance testing of SeaTunnel and the development of an open data scheduling platform to integrate SeaTunnel may be carried out at a later stage, and its use will be rolled out gradually.
Outbound scenario: Hive data sync to StarRocks
To briefly introduce the background, the Big Data platform has now completed the unification of the OLAP engine layer, using the StarRocks engine to replace the previous Kylin engine as the main query engine in OLAP scenarios.
In the data processing process, after the data is modelled in the data warehouse, the upper model needs to be imported into the OLAP engine for query acceleration, so there are a lot of tasks to push data from Hive to StarRocks every day. task (based on a wrapper for the StarRocks Broker Load import method) to a StarRocks-based table.
The current pain points are twofold.
·Long data synchronization links: Hive2StarRocks processing links, which require at least two tasks, are relatively redundant.
·Outbound efficiency: From the perspective of outbound efficiency, many Hive models themselves are processed by Spark SQL, and based on the processing the Spark Dataset in memory can be pushed directly to StarRocks without dropping the disk, improving the model’s regional time.
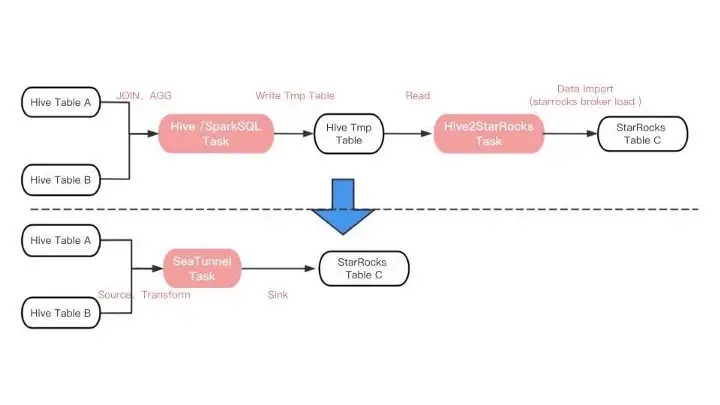 StarRocks currently also supports Spark Load, based on the Spark bulk data import method, but our ETL is more complex, needs to support data conversion multi-table Join, data aggregation operations, etc., so temporarily can not meet.
StarRocks currently also supports Spark Load, based on the Spark bulk data import method, but our ETL is more complex, needs to support data conversion multi-table Join, data aggregation operations, etc., so temporarily can not meet.
We know from the SeaTunnel community that there are plans to support the StarRocks Sink Connector, and we are working on that part as well, so we will continue to communicate with the community to build it together later.
How to get involved in community building
SeaTunnel Community Contribution
As mentioned earlier, the community has completed the refactoring of the V1 to V2 API and needs to implement more connector plug-ins based on the V2 version of the connector API, which I was lucky enough to contribute to.
I am currently responsible for big data infrastructure work, which many mainstream big data components big data also use, so when the community proposed a connector issue, I was also very interested in it.
As the platform is also investigating SeaTunnel, learning and being able to contribute pr to the community is a great way to learn about SeaTunnel.
I remember at first I proposed a less difficult pr to implement the WeChat sink connector, but in the process of contributing I encountered many problems, bad coding style, code style did not take into account the rich output format supported by the extension, etc. Although the process was not so smooth, I was really excited and accomplished when the pr was merged. Although the process was not so smooth, it was very exciting and rewarding when the pr was merged.
As I became more familiar with the process, I became much more efficient at submitting pr and was confident enough to attempt difficult issues.
How to get involved in community contributions quickly
- Good first issue Good first issue #3018 #2828
If you are a first-time community contributor, it is advisable to focus on the Good first issue first, as it is basically a relatively simple and newcomer-friendly issue.
Through Good first issue, you can get familiar with the whole process of participating in the GitHub open source community contribution, for example, first fork the project, then submit the changes, and finally submit the pull request, waiting for the community to review, the community will target to you to put forward some suggestions for improvement, directly will leave a comment below, until when your pr is merged in, this will have completed a comp
- Subscribe to community mailings Once you’re familiar with the pr contribution process, you can subscribe to community emails to keep up to date with what’s happening in the community, such as what features are currently being worked on and what’s planned for future iterations. If you’re interested in a feature, you can contribute to it in your own situation!
- Familiarity with git use The main git commands used in development are git clone, git pull, git rebase and git merge. git rebase is recommended in the community development specification and does not generate additional commits compared to git merge.
- Familiarity with GitHub project collaboration process Open source projects are developed collaboratively by multiple people, and the collaboration method on GitHub is at its core outlined in fork For example, the apache st project, which is under the apache space, is first forked to our own space on GitHub
Then modify the implementation, mention a pull request, and submit the pull request to be associated with the issue, in the commit, if we change a long time, in the upward commit, then the target branch has a lot of new commits exhausted this time we need to do a pull& merge or rebase.
- Source code compilation project It is important to be familiar with source compilation, as local source compilation can prove that the code added to a project can be compiled, and can be used as a preliminary check before committing to pr. Source compilation is generally slow and can be speeded up by using mvn -T for multi-threaded parallel compilation.
- Compilation checks Pre-compilation checks, including Licence header, Code checkstyle, and Document checkstyle, will be checked during Maven compilation, and if they fail, the CI will not be passed. So it is recommended to use some plug-in tools in the idea to improve the efficiency, such as Code checkstyle has a plug-in to automatically check the code specification, Licence header can add code templates in the idea, these have been shared by the community before how to do!
- Add full E2E
Add full E2E testing and ensure that the E2E is passed before the Pull request.
Finally, I hope more students will join the SeaTunnel community, where you can not only feel the open-source spirit and culture of Apache but also understand the management process of Apache projects and learn good code design ideas.
We hope that by working together and growing together, we can build SeaTunnel into a top-notch data integration platform.