
Translator | Critina
In the May joint Meetup between Apache SeaTunnel and Apache Inlong, Li Zongwen, a senior engineer at WhaleOps, shared his experiences about finding and refactoring of the the four major problems with Apache SeaTunnel (Incubating).i.e. the connectors of SeaTunnel have to be implemented many times,the inconsistent parameters, SeaTunnel is not supportive of multiple versions of the engine, and it’s difficult to upgrade the engine. In order to solve these problems, Li Zongwen aimed to decouple Apache SeaTunnel (Incubating) from thw computing engines, and re-factor the Source and Sink apis to improve the development experience.
This speech mainly consists of five parts.The first part is about Apache SeaTunnel (Incubator) refactoring background and motivation. The second part introduces Apache SeaTunnel (Incubating) Target for refactoring.The third part discusses Apache SeaTunnel (Incubating) overall design for refactoring. The last two parts is about Apache SeaTunnel (Incubating) Source API design and Apache SeaTunnel (Incubating) Sink API design.
01 Background and motivation for refactoring
Those of you who have used Apache SeaTunnel (Incubator) or developers should know that Apache SeaTunnel (Incubator) is now fully coupled with the engine, which is entirely based on Spark or Flink, and so are the configuration file parameters. From the perspective of contributors and users, we can find they face some problems.
In the view of the contributors, repeated implementing connector is meaningless and it is unable for potential contributors to contribute to the community due to inconsistent engine versions.
At present, many companies use Lambda architecture, Spark is used for offline operations and Flink is used for real-time operations. In the view of the users, it can be found that Spark may have the Connector of SeaTunnel, but Flink does not, and the parameters of the two engines for the Connector of the same storage engine are not unified, thus resulting a high cost of and deviating from its original intention of being easy to use. And some users question that Flink version 1.14 is not supported nowadays. While with the current SeaTunnel architecture, we must discard the previous version in order to support Flink version 1.14, which will bring great trouble for early version users.
As a result, it was difficult for us to either upgrade engine or support more versions.
In addition, Spark and Flink both adopt the Checkpoint fault-tolerant mechanism implemented by Chandy-Lamport algorithm and internally unify DataSet and DataStream. On this premise, we believe decoupling is feasible.
02 Apache SeaTunnel (Incubating) decouples with computing engine
Therefore, in order to solve the problems raised above, we set the following goals.
Connector is only implemented once. To solve the problems that parameters are not unified and Connector is implemented for too many times, we hope to achieve a unified Source and Sink API;
Multiple versions of Spark and Flink engines are supported. A translation layer above the Source and Sink API is added to support multiple versions of Spark and Flink engines.
The logic for parallel shard of Source and the Sink submission should be clarified. We must provide a good API to support Connector development.
The full database synchronization in real-time scenarios should be supported. This is a derivative requirement that many users have mentioned for CDC support. I once participated the Flink CDC community before and many users pointed out that in the CDC scenario, if you wanted to use the Flink CDC directly, each table would have a link and there would be thousands of links for thousands of tables when you need to synchronize the whole library, which was unacceptable for both the database and the DBA. To solve this problem, the simplest way was to introduce Canal、Debezium or other components, which were used to pull incremental data to Kafka or other MQ for intermediate storage, and then we could use Flink SQL for synchronization. This actually contradicted the original idea of the Flink CDC to reduce links. However, the Flink CDC aimed only a Connector and was unable to deal with the whole link, so the proposal was not seen in the SeaTunnel community. By the chance of the reconstruction, we submitted the proposal to the SeaTunnel community.
Automatic discovery and storage of meta information are realized. The users should have awful experience due to the storage engines such as Kafka lacking of record of the data structure, when we need to read structured data, the user must define the topic of structured data types before read one topic at a time . We hope once the configuration is completed, there is no need to do any redundant work again.
Some people may wonder why we don’t use Apache Beam directly. That is because Beam sources are divided into BOUNDED and UNBOUNDED sources, which means it needs to be implemented twice. Moreover, some features of Source and Sink are not supported, which will be mentioned later.
03 Apache SeaTunnel(Incubating) overall design for refactoring
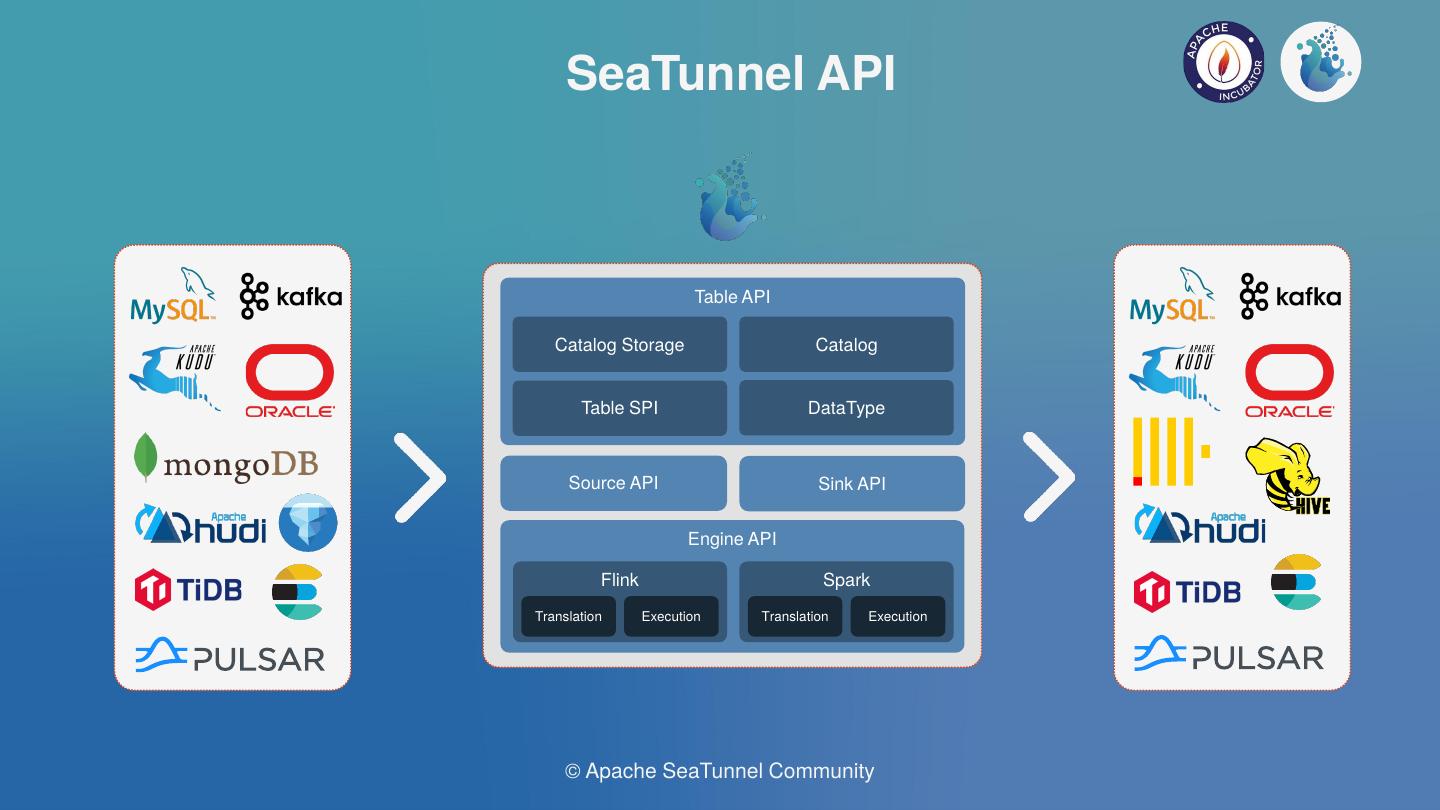
The Apache SeaTunnel(Incubating) API architecture is described in the picture above.
The Source & Sink API is one of the core APIS of data integration, which defines the logic for parallel shard of Source and the commitment of Sink to realize the Connector.
The Engine API includes the translation and the execution layers. The translation is used to translate Souce and Sink API of SeaTunnel into connectors that can be run inside the engine.
The execution defines the execution logic of Source, Transform, Sink and other operations in the engine.
The Table SPI is mainly used to expose the interface of Source and Sink in SPI mode, and to specify mandatory and optional parameters of Connector etc.
The DataType includes SeaTunnel data structure used to isolate engines and declare Table schema.
The Catalog is Used to obtain Table schemes and Options, etc. The Catalog Storage is used to store Table Schemes defined by unstructured engines such as Kafka.
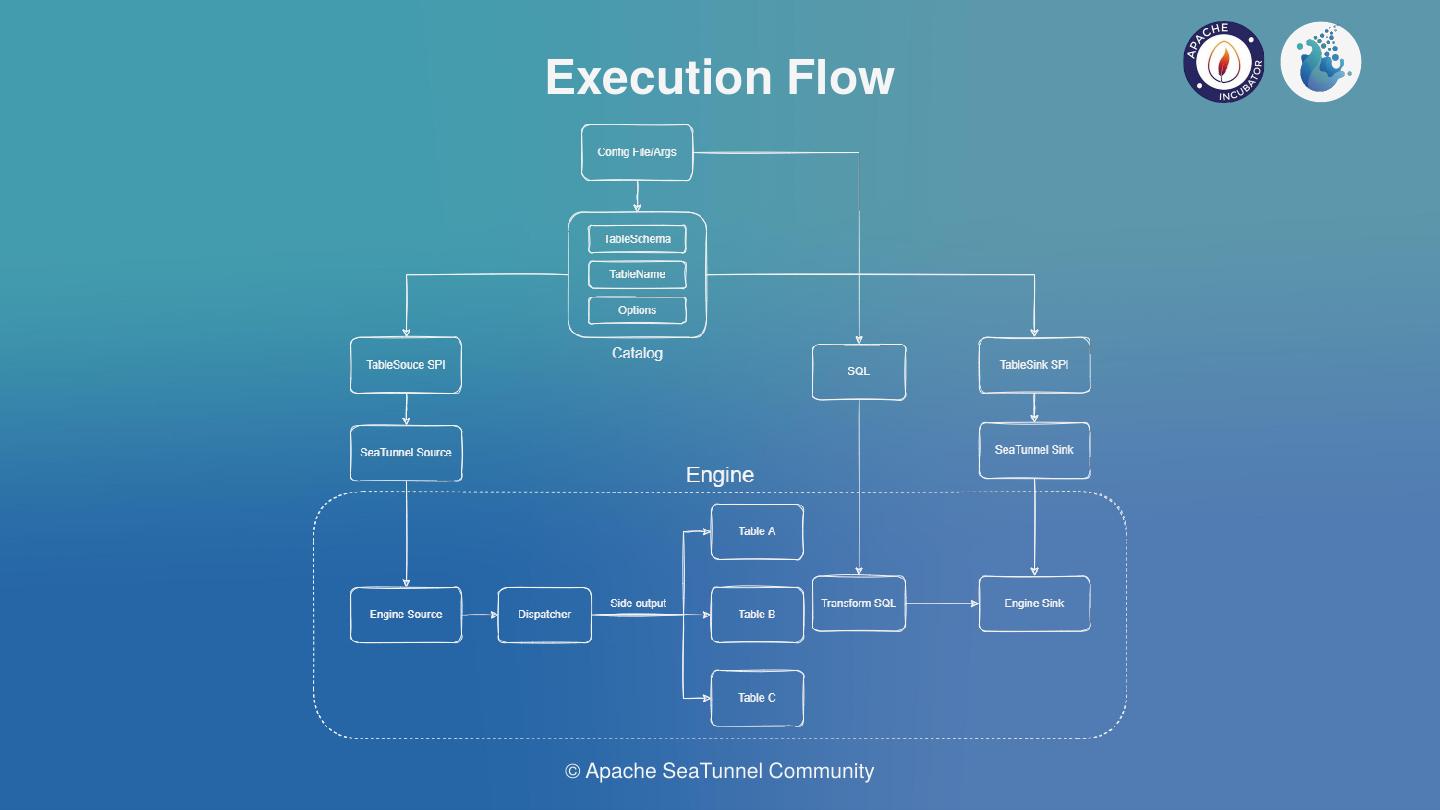
The execution flow we assumed nowadays can be see in the above picture.
Obtain task parameters from configuration files or UI.
Obtain the Table Schema, Option and other information by analyzing the parameters from Catalog.
Pull up the Connector of SeaTunnel in SPI mode and inject Table information.
Translate the Connector from SeaTunnel into the Connector within the engine.
Execute the operation logic of the engine. The multi-table distribution in the picture only exists in the synchronization of the whole database of CDC, while other connectors are single tables and do not need the distribution logic.
It can be seen that the hardest part of the plan is to translate Source and Sink into an internal Source and Sink in the engine.
Many users today use Apache SeaTunnel (Incubating) not only as a data integration tool but also as a data storage tool, and use a lot of Spark and Flink SQLs. We want to preserve that SQL capability for users to upgrade seamlessly.
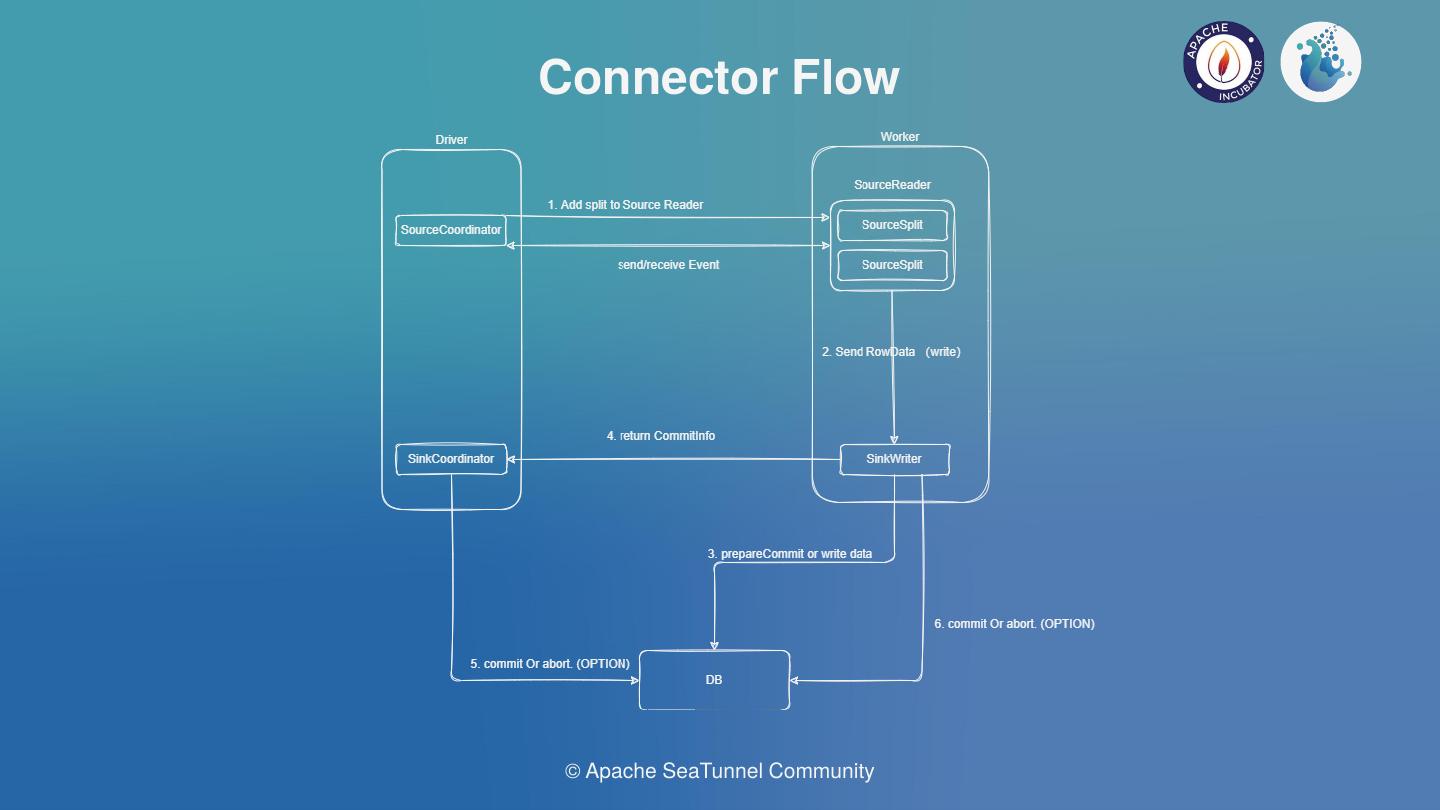
According to our research, the feature above shows the ideal execution logic of Source and Sink. Since SeaTunnel is incubated as WaterDrop, the terms in the figure are tended towards Spark.
Ideally, the Source and Sink coordinators can be run on the Driver, and the Source Reader and Sink Writer will run on the Worker. In terms of the Source Coordinator, we expect it to support several features.
The first capability is that the slicing logic of data can be dynamically added to the Reader.
The second is that the coordination of Reader can be supported. Source Reader is used to read data, and then send the data to the engine, and finally to the Source Writer for data writing. Meanwhile, Writer can support the two-phase transaction submission, and the coordinator of Sink supports the aggregation submission requirements of Connector such as Iceberg.
04 Source API
After research, we found the following features that are required by Source.
Unified offline and real-time API , which supports that source is implemented only once and supports both offline and real-time API;
Supportive of parallel reading. For example that Kafka generates a reader for each partition and execute in parallel.
Supporting dynamic slice-adding. For example, Kafka defines a regular topic, when a new topic needs to be added due to the volume of business, the Source API allows to dynamically add the slice to the job.
Supporting the work of coordinating reader, which is currently only needed in the CDC Connector. CDC is currently supported by NetFilx’s DBlog parallel algorithms, which requires reader coordination between full synchronization and incremental synchronization.
Supporting a single reader to process multiple tables, i.e. to allows the whole database synchronization in the real-time scenario as mentioned above.

Based on the above requirements, we have created the basic API as shown in the figure above. And the code has been submitted to the API-Draft branch in the Apache SeaTunnel(Incubator) community. If you’re interested, you can view the code in detail.
How to adapt to Spark and Flink engines
Flink and Spark unify the API of DataSet and DataStream, and they can support the first two features. Then, for the remaining three features, how do we
- Support dynamic slice-adding?
- Support the work of coordinating reader?
- Support a single reader to process multiple tables?
Let's review the design with questions.
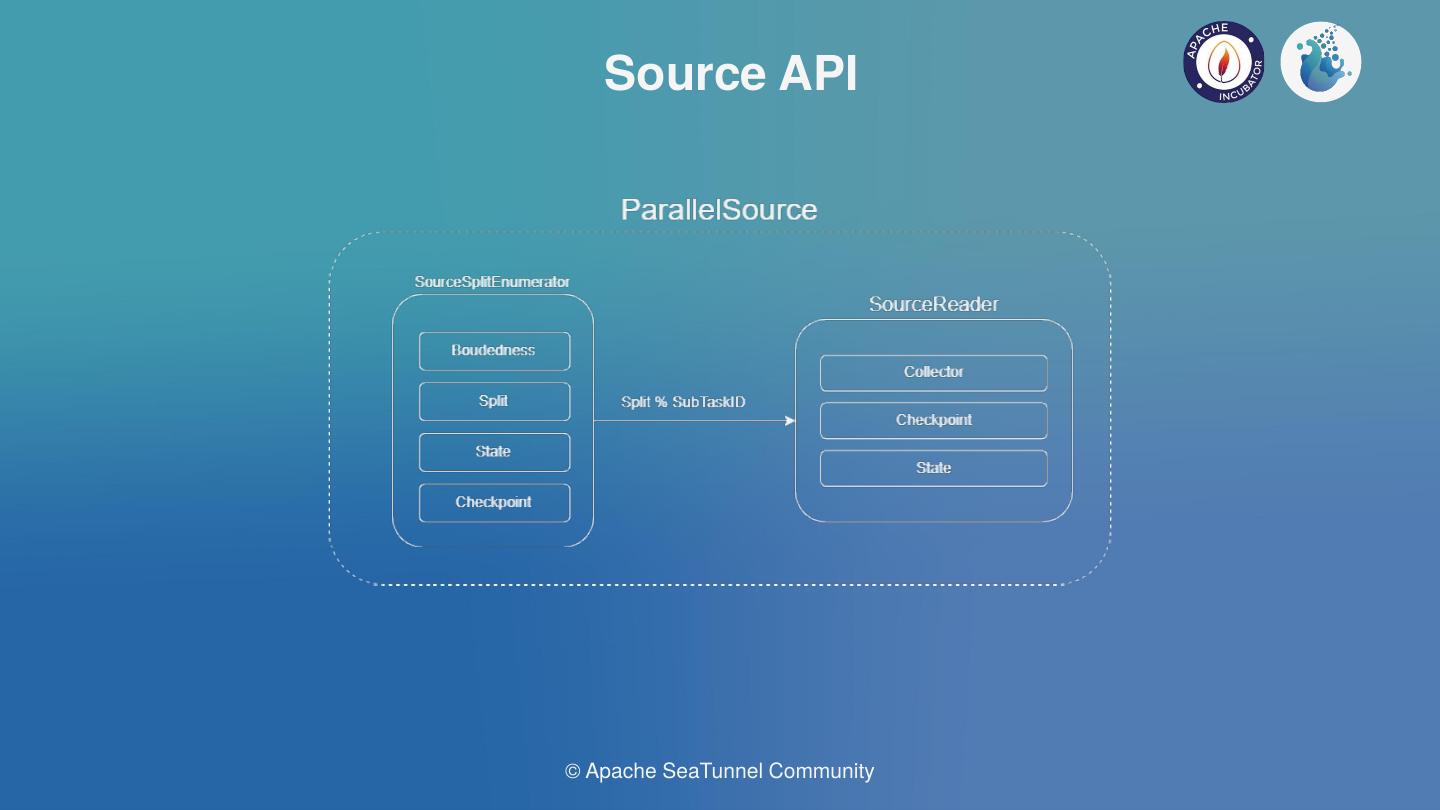
We found that other connectors do not need coordinators, except for CDC. For those connectors that do not need coordinators, we have a Source that supports parallel execution and engine translation.
As shown in the figure above, there is a slice enumerator on the left, which can list which slices the source needs and show what there are. After enumerating slices in real time, each slice would be distributed to SourceReader, the real data reading module. Boundedness marker is used to differentiate offline and real-time operations. Connector can mark whether there is a stop Offset in a slice. For example, Kafka can support real-time and offline operations. The degree of parallelism can be set for the ParallelSource in the engine to support parallel reading.
As shown in the figure above, in a scenario where a coordinator is required, Event transmission is done between the Reader and Enumerator. Enumerator coordinates events by the Event sent by the Reader. The Coordinated Source needs to ensure single parallelism at the engine level to ensure data consistency. Of course, this does not make good use of the engine’s memory management mechanism, but trade-offs are necessary.
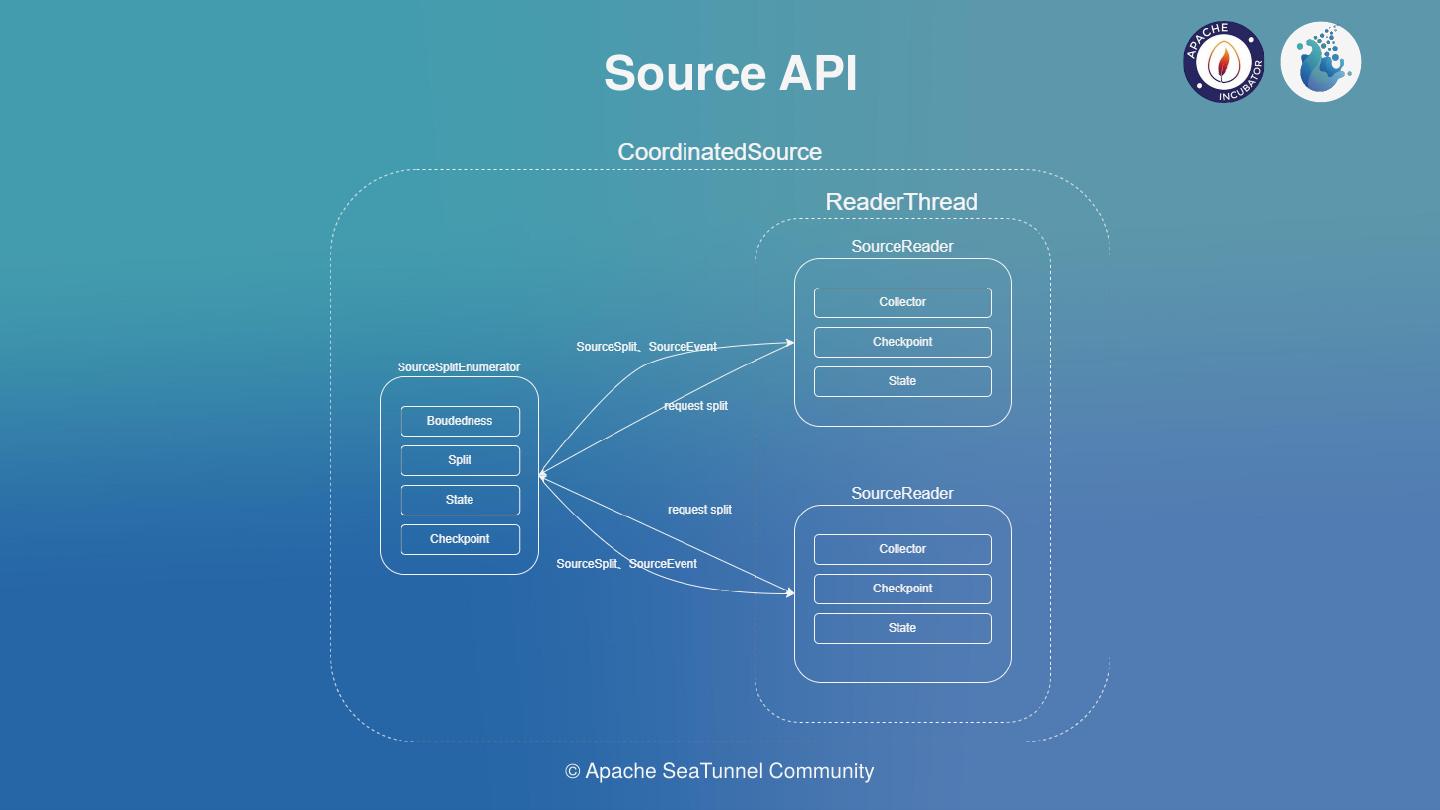
For the last question, how can we support a single reader to process multiple tables? This involves the Table API layer. Once all the required tables have been read from the Catalog, some of the tables may belong to a single job and can be read by a link, and some may need to be separated, depending on how Source is implemented. Since this is a special requirement, we want to make it easier for the developers. In the Table API layer, we will provide a SupportMultipleTable interface to declare that Source supports multiple Table reads. The Source is implemented based on the corresponding deserializer of multiple tables. As for how to separate derived multi-table data, Flink will adopt Side Output mechanism, while Spark is going to use Filter or Partition mechanism.
5 Sink API
At present, there are not many features required by Sink, but three mojor requirements are considerable according to our research.
The first is about idempotent writing, which requires no code and depends on whether the storage engine can support it.
The second is about distributed transactions. The mainstream method is two-phase commitments, such as Kafka etc.
The third is about the submission of aggregation. For Storage engines like Iceberg and Hoodie, we hope there is no issues triggered by small files, so we expect to aggregate these files into a single file and commit it as a whole.
Based on these three requirements, we built three APIS: SinkWriter, SinkCommitter, and SinkAggregated Committer. SinkWriter plays a role of writing, which may or may not be idempotent. SinkCommitter supports for two-phase commitments. SinkAggregatedCommitter supports for aggregated commitments.
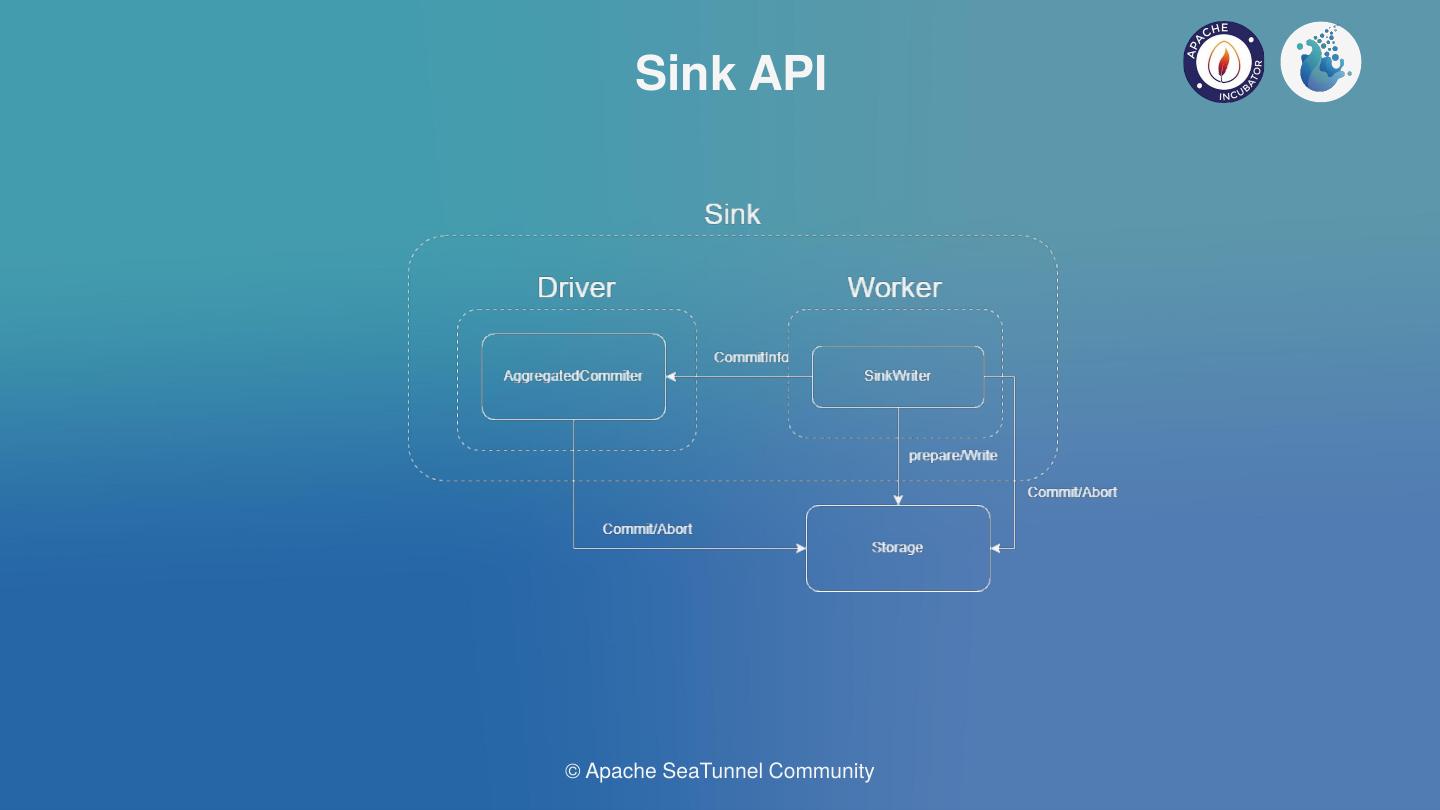
Ideally, AggregatedCommitter runs in Driver in single or parallel, and Writer and Committer run in Worker with multiple parallels, with each parallel carrying its own pre-commit work and then send Aggregated messages to Aggregated committers.
Current advanced versions of Spark and Flink all support AggregatedCommitter running on the Driver(Job Manager) and Writer and Committer running on the worker(Task Manager).
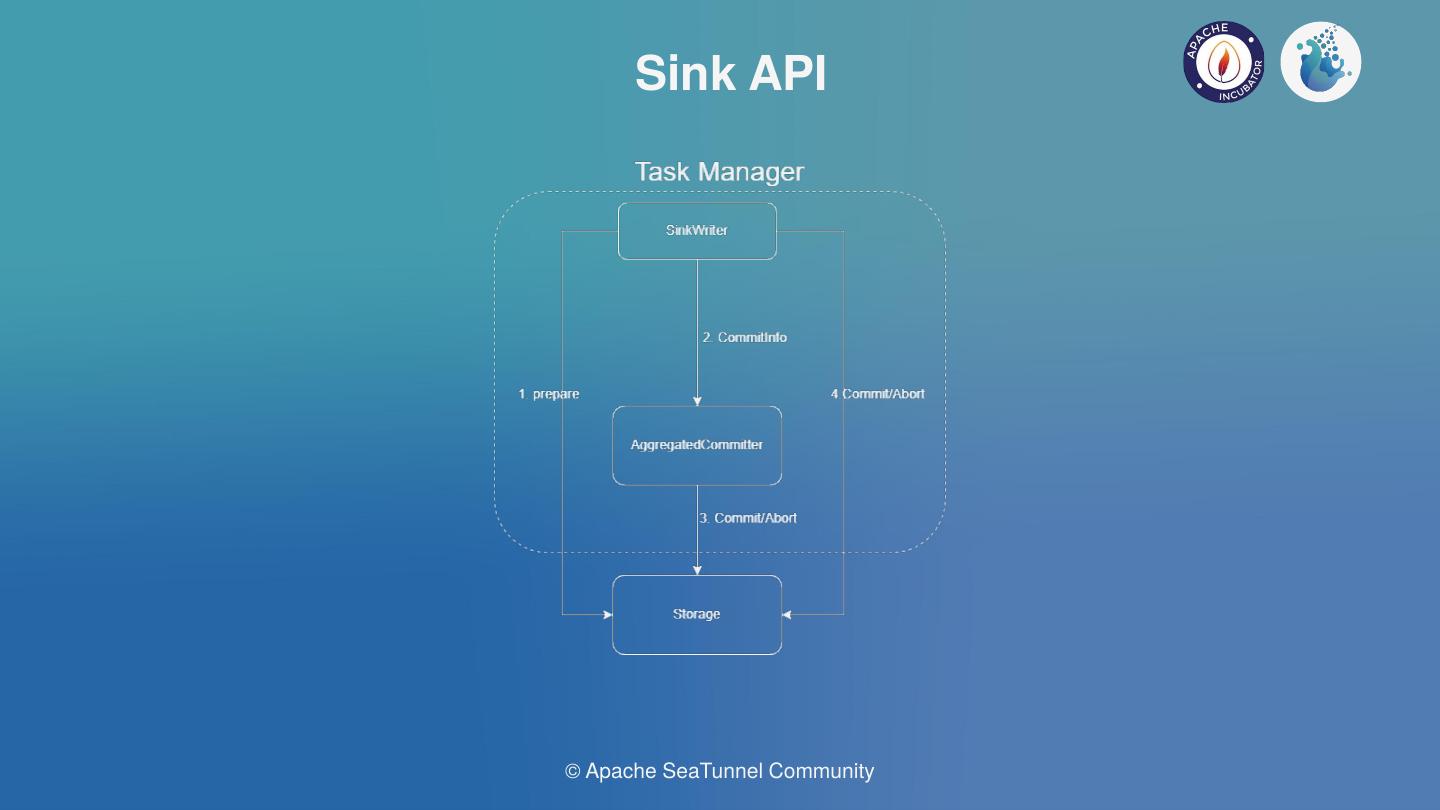
However, for the lower versions of Flink, AggregatedCommitter cannot be supported to run in JM, so we are also carrying translation adaptation. Writer and Committer will act as pre-operators, packaged by Flink’s ProcessFunction, supports concurrent pre-delivery and write, and implement two-phase commitment based on Flink’s Checkpoint mechanism. This is also the current 2PC implementation of many of Flink connectors. The ProcessFunction can send messages about pre-commits to downstream Aggregated committers, which can be wrapped around operators such as SinkFunction or ProcessFunction. Of course, We need to ensure that only one single parallel will be started by the AggregatedCommitter in case of the broken of the logic of the aggregated commitment.
Thank you for watching. If you’re interested in the specific implementations mentioned in my speech, you can refer to the Apache SeaTunnel (Incubating) community and check out the API-Draft branch code. Thank you again.