
Author | Fan Jia, Apache SeaTunnel(Incubating) Contributor Editor | Test Engineer Feng Xiulan
For importing billions of batches of data, the traditional JDBC approach does not perform as well as it should in some massive data synchronization scenarios. To write data faster, Apache SeaTunnel (Incubating) has just released version 2.1.1 to provide support for ClickhouseFile-Connector to implement Bulk load data writing.
Bulk load means synchronizing large amounts of data to the target DB. SeaTunnel currently supports data synchronization to ClickHouse.
At the Apache SeaTunnel (Incubating) April Meetup, Apache SeaTunnel (Incubating) contributor Fan Jia shared the topic of "ClickHouse bulk load implementation based on SeaTunnel", explaining in detail the implementation principle and process of ClickHouseFile for efficient processing of large amounts of data.
Thanks to the test engineer Feng Xiulan for the article arrangement!
This presentation contains seven parts.
- State of ClickHouse Sink
- Scenarios that ClickHouse Sink isn't good at
- Introduction to the ClickHouseFile plugin
- ClickHouseFile core technologies
- Analysis of ClickHouseFile plugin implementation
- Comparison of plug-in capabilities
- Post-optimization directions

Fan Jia, Apache SeaTunnel (Incubating) contributor, Senior Enginee of WhaleOps.
01 Status of ClickHouse Sink
At present, the process of synchronizing data from SeaTunnel to ClickHouse is as follows: as long as the data source is supported by SeaTunnel, the data can be extracted, converted (or not), and written directly to the ClickHouse sink connector, and then written to the ClickHouse server via JDBC.
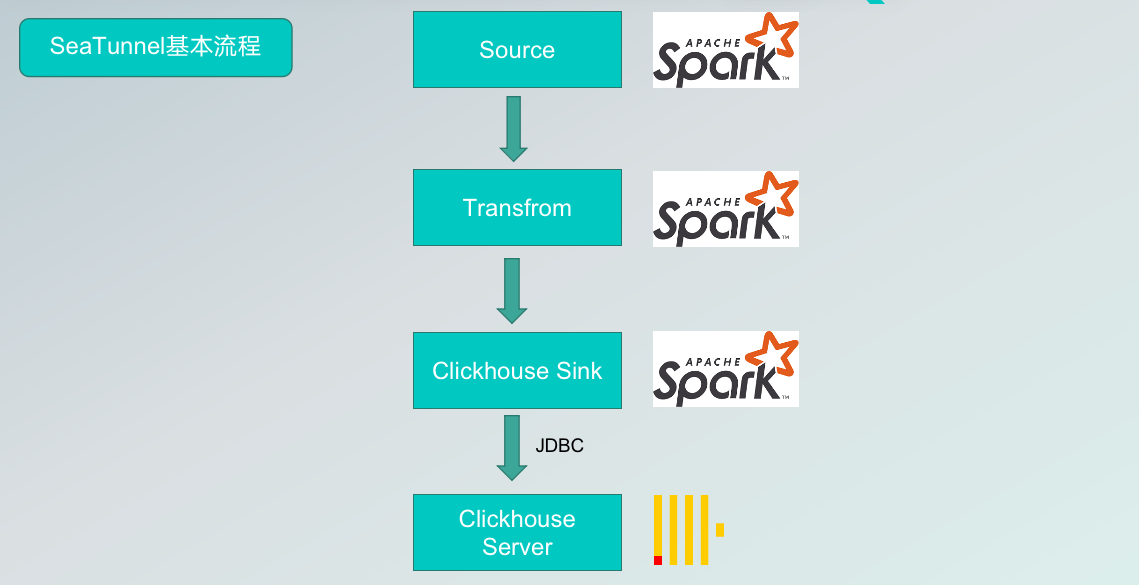
However, there are some problems with writing to the ClickHouse server via traditional JDBC.
Firstly, the tool used now is the driver provided by ClickHouse and implemented via HTTP, however, HTTP is not very efficient to implement in certain scenarios. The second is the huge amount of data, if there is duplicate data or a large amount of data written at once, it needs to generate the corresponding insert statement and send it via HTTP to the ClickHouse server-side by the traditional method, where it is parsed and executed item by item or in batches, which does not allow data compression.
Finally, there is the problem we often encounter, i.e. too much data may lead to an OOM on the SeaTunnel side or a server-side hang due to too much data being written to the server-side too often.
So we thought, is there a faster way to send than HTTP? If data pre-processing or data compression could be done on the SeaTunnel side, then the network bandwidth pressure would be reduced and the transmission rate would be increased.
02 Scenarios that ClickHouse Sink isn't good at
- If the HTTP transfer protocol is used, HTTP may not be able to handle it when the volume of data is too large and the batch is sending requests in micro-batches.
- Too many INSERT requests may put too much pressure on the server. The bandwidth can handle a large number of requests, but the server-side is not always able to carry them. The online server not only needs data inserts but more importantly, the query data can be used by other business teams. If the server cluster goes down due to too much-inserted data, it is more than worth the cost.
03 ClickHouse File core technologies
In response to these scenarios that ClickHouse is not good at, we wondered is there a way to do data compression right on the Spark side, without increasing the resource load on the Server when writing data, and with the ability to write large amounts of data quickly? So we developed the ClickHouseFile plugin to solve the problem.
The key technology of the ClickHouseFile plugin is ClickHouse -local. ClickHouse-local mode allows users to perform fast processing of local files without having to deploy and configure a ClickHouse Server. C lickHouse-local uses the same core as ClickHouse Server, so it supports most features as well as the same format and table engine.
These two features mean that users can work directly with local files without having to do the processing on the ClickHouse Server side. Because it is the same format, the data generated by the operations we perform on the remote or SeaTunnel side is seamlessly compatible with the server-side and can be written to using ClickHouse local. ClickHouse local is the core technology for the implementation of ClickHouseFile, which allows for implementing the ClickHouse file connector.
ClickHouse local core is used in the following ways.
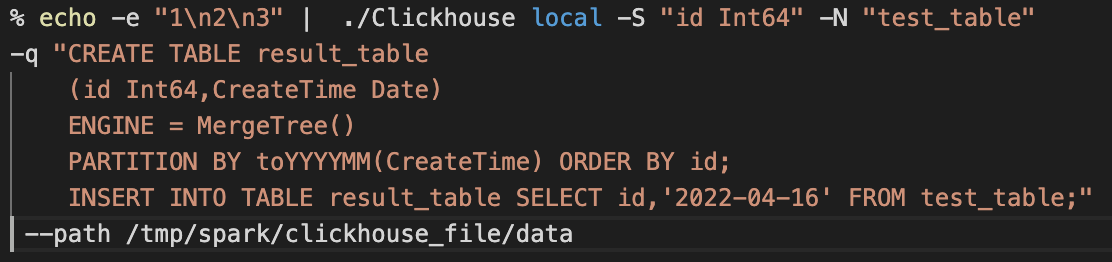
First line: pass the data to the test_table table of the ClickHouse-local program via the Linux pipeline.
Lines two to five: create a result_table for receiving data.
The sixth line: pass data from test_table to the result_table.
Line 7: Define the disk path for data processing.
By calling the Clickhouse-local component, the Apache SeaTunnel (Incubating) is used to generate the data files and compress the data. By communicating with the Server, the generated data is sent directly to the different nodes of Clickhouse and the data files are then made available to the nodes for the query.
Comparison of the original and current implementations.
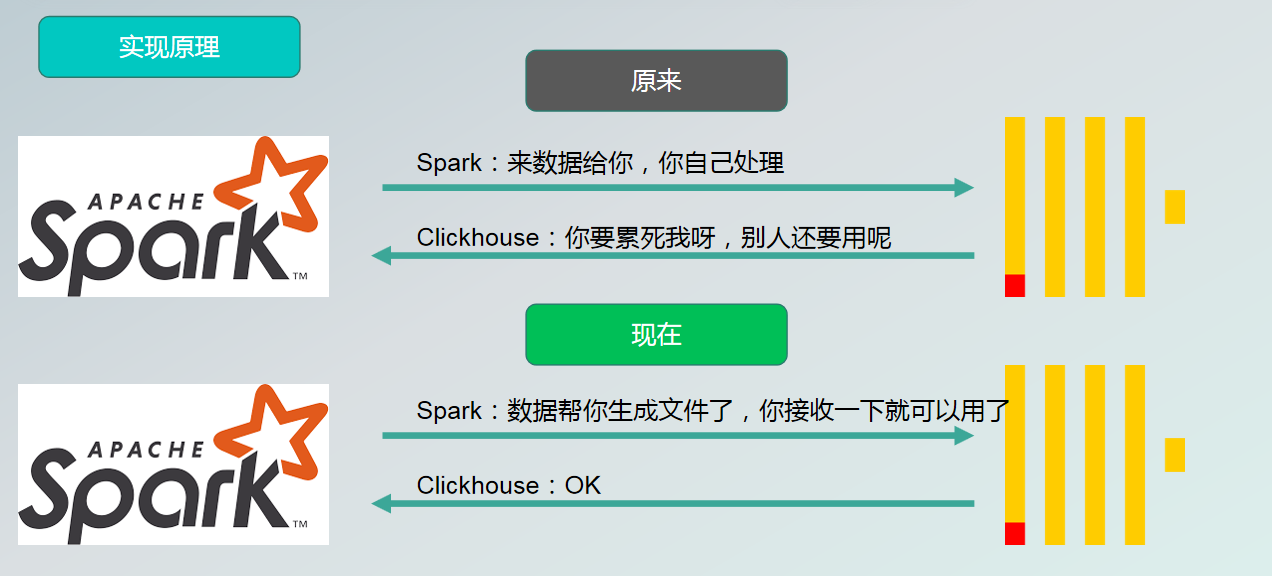
Originally, the data, including the insert statements was sent by Spark to the server, and the server did the SQL parsing, generated and compressed the table data files, generated the corresponding files, and created the corresponding indexes. If we use ClickHouse local technology, the data file generation, file compression and index creation are done by SeaTunnel, and the final output is a file or folder for the server-side, which is synchronized to the server and the server can queries the data without additional operations.
04 Core technical points
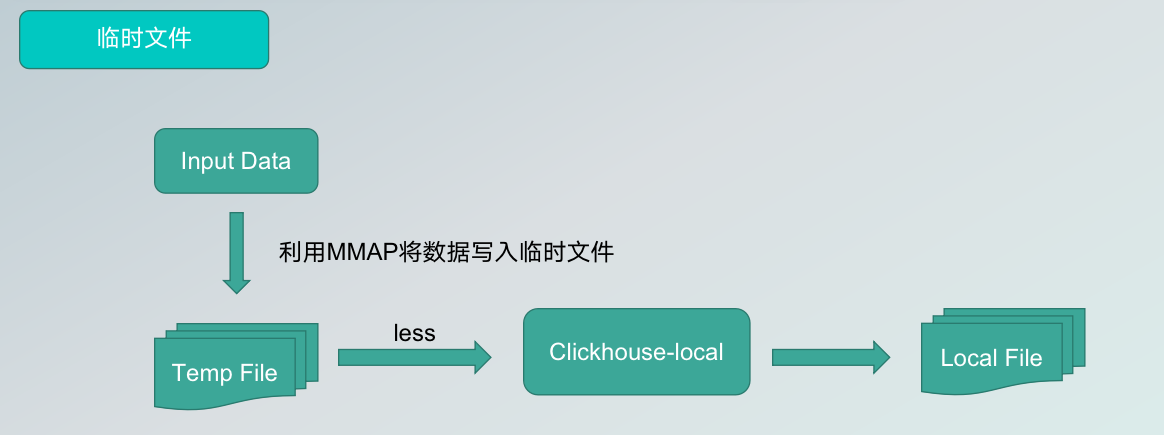
The above process makes data synchronization more efficient, thanks to three optimizations we have made to it.
Firstly, the data is transferred from the pipeline to the ClickHouseFile by the division, which imposes limitations in terms of length and memory. For this reason, we write the data received by the ClickHouse connector, i.e. the sink side, to a temporary file via MMAP technology, and then the ClickHouse local reads the data from the temporary file to generate our target local file, in order to achieve the effect of incremental data reading and solve the OM problem.
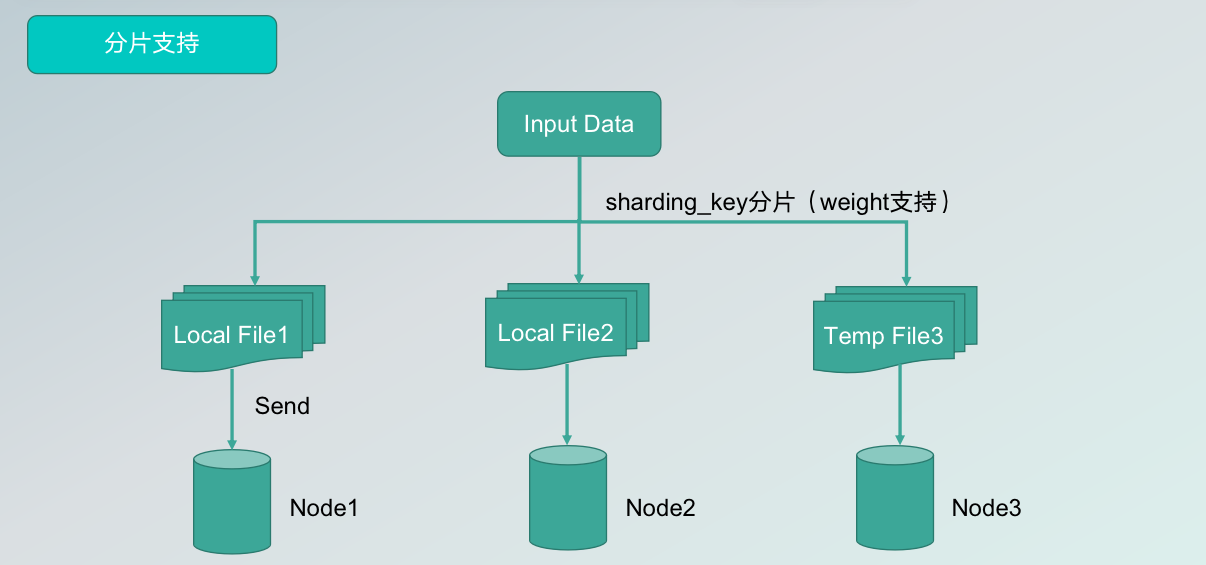
Secondly, it supports sharding. If only one file or folder is generated in a cluster, the file is distributed to only one node, which will greatly reduce the performance of the query. Therefore, we carry out slicing support. Users can set the key for slicing in the configuration folder, and the algorithm will divide the data into multiple log files and write them to different cluster nodes, significantly improving the read performance.

The third key optimization is file transfer. Currently, SeaTunnel supports two file transfer methods, one is SCP, which is characterized by security, versatility, and no additional configuration; the other is RSYNC, which is somewhat fast and efficient and supports breakpoint resume, but requires additional configuration, users can choose between the way suits their needs.
05 Plugin implementation analysis
In summary, the general implementation process of ClickHouseFile is as follows.
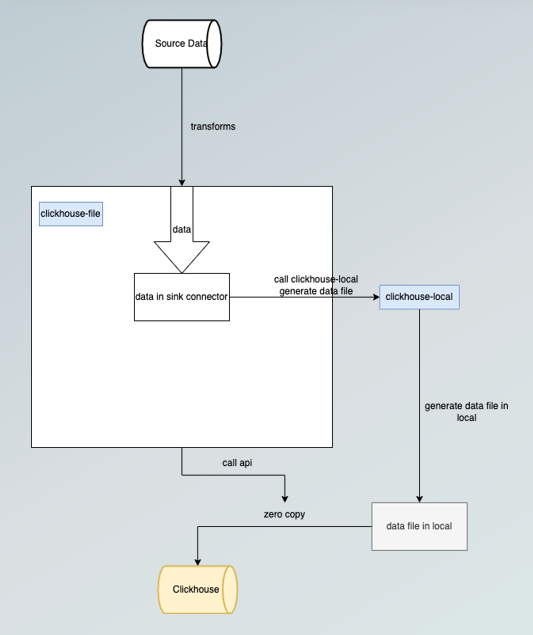
1.caching data to the ClickHouse sink side. 2.calling ClickHouse-local to generate the file. 3.sending the data to the ClickHouse server. 4.Execution of the ATTACH command.
With the above four steps, the generated data reaches a queryable state.
06 Comparison of plug-in capabilities
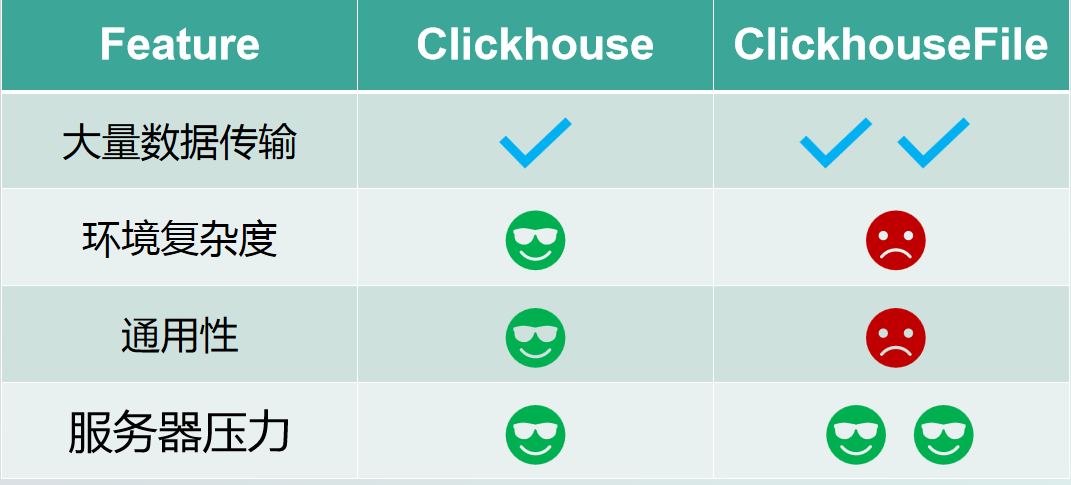
(a) In terms of data transfer, ClickHouseFile is more suitable for massive amounts of data, with the advantage that no additional configuration is required and it is highly versatile, while ClickHouseFile is more complex to configure and currently supports fewer engines.
In terms of environmental complexity, ClickHouse is more suitable for complex environments and can be run directly without additional configuration.
In terms of versatility, ClickHouse, due to being an officially supported JDBC diver by SeaTunnel, basically supports all engines for data writing, while ClickHouseFile supports relatively few engines.
In terms of server pressure, ClickHouseFile's advantage shows when it comes to massive data transfers that don't put too much pressure on the server.
However, the two are not in competition and the choice needs to be based on the usage scenario.
07 Follow-up plans
Although SeaTunnel currently supports the ClickHouseFile plugin, there are still many defects that need to be optimized, mainly including
- Rsync support.
- Exactly-Once support.
- Zero Copy support for transferring data files.
- More Engine support.
Anyone interested in the above issues is welcome to contribute to the follow-up plans, or tell me your ideas!