
At the Apache SeaTunnel (Incubating) Meetup in April, Yuan Hongjun, a big data expert and OLAP platform architect at Kidswant, shared a topic of SeaTunnel Application and Refactoring at Kidswant.
The presentation contains five parts.
- Background of the introduction of Apache SeaTunnel (Incubating) by Kidswant
- A comparison of mainstream tools for big data processing
- The implementation of Apache SeaTunnel (Incubating)
- Common problems in Apache SeaTunnel (Incubating) refactoring
- Predictions on the future development of Kidswant

Yuan Hongjun, Big data expert, OLAP platform architect of Kidswant. He has many years of experience in big data platform development and management, and has rich research experience in data assets, data lineage mapping, data governance, OLAP, and other fields.
01 Background
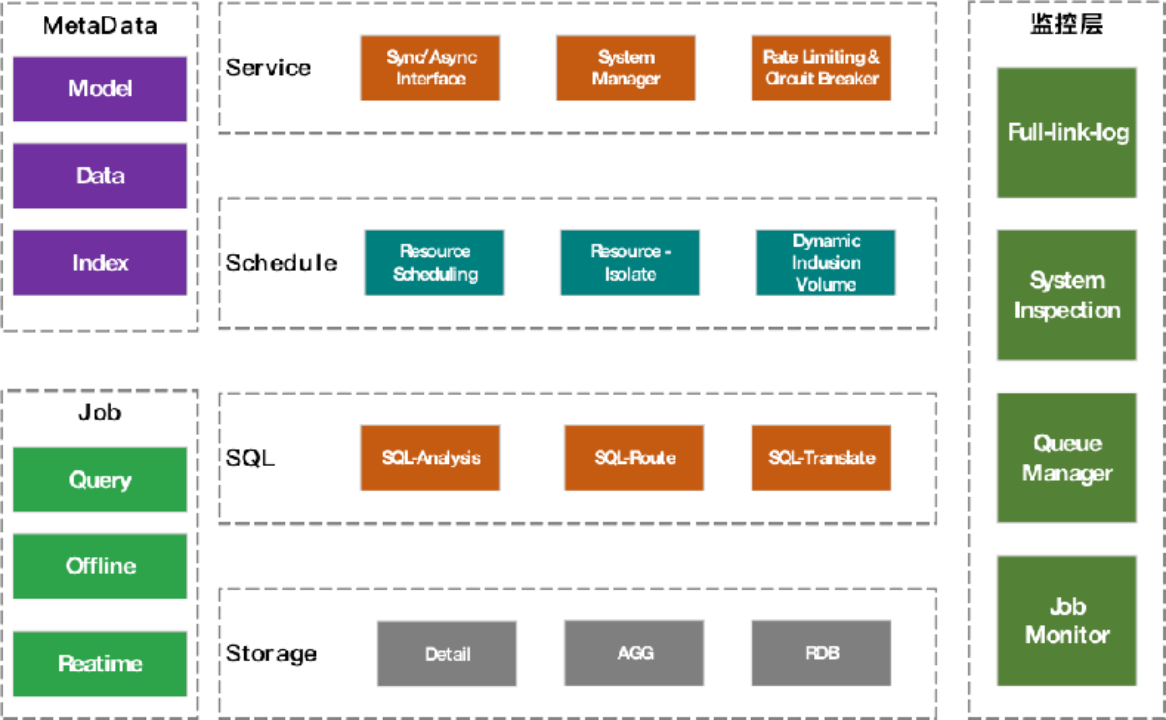
At present, Kidswant’s OLAP platform consists of seven parts: metadata layer, task layer, storage layer, SQL layer, scheduling layer, service layer, and monitoring layer. This sharing focuses on offline tasks in the task layer.
In fact, Kidswant had a complete internal collection and push system, but due to some historical legacy issues, the company’s existing platform could not quickly support the OLAP platform getting online, so at that time the company had to abandon its own platform and start developing a new system instead. There were three options in front of OLAP at the time.
1, Re-develop the collection and push system.
2、Self-R&D.
3, Participate in open source projects.
02 Big data processing mainstream tools comparison
These three options have their own pros and cons. Carrying re-research and development based on the collection and push system is convenient for us to take advantage of the experience of previous results and avoid repeatedly stepping into the pit. But the disadvantage is that it requires a large amount of code, time, a longer research period, and with less abstract code and lots of customized functions bound to the business, it’s difficult to do the re-development.
If completely self-developed, though the development process is autonomous and controllable, some engines such as Spark can be done to fit our own architecture, while the disadvantage is that we may encounter some unknown problems.
For the last choice, if we use open-source frameworks, the advantage is that there is more abstract code, and the framework can be guaranteed in terms of performance and stability after verification by other major companies. Therefore Kidswant mainly studied three open-source data synchronization tools, DATAX, Sqoop, and SeaTunnel in the early stages of OLAP data synchronization refactoring.
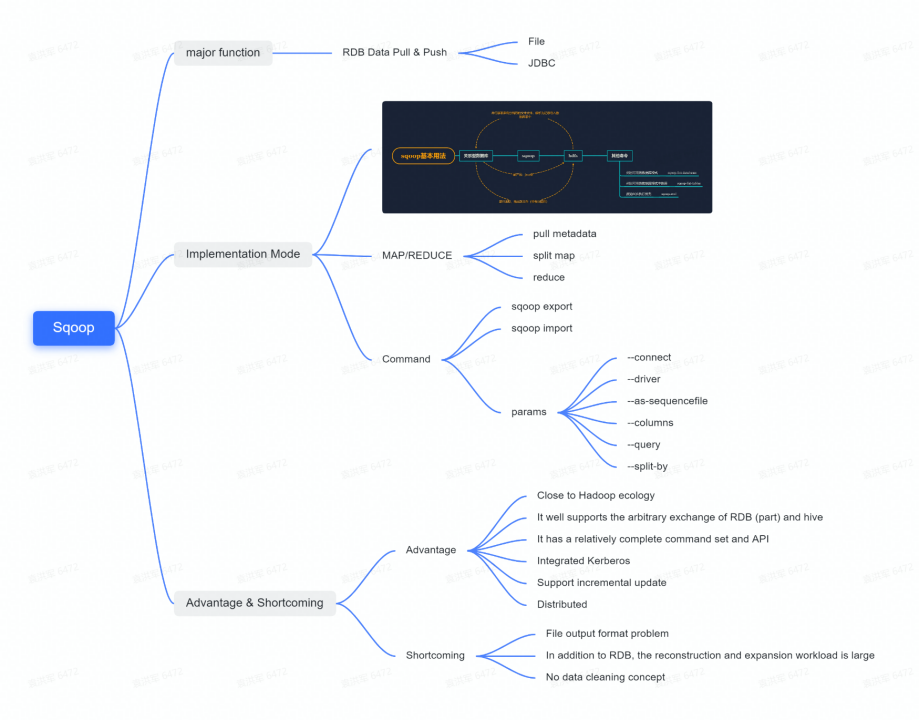
From the diagram we can see that Sqoop’s main function is data synchronization for RDB, and its implementation is based on MAP/REDUCE. Sqoop has rich parameters and command lines to perform various operations. The advantage of Sqoop is that it fits Hadoop ecology, and already supports most of the conversion from RDB to HIVE arbitrary source, with a complete set of commands and APIs.
The disadvantages are that Sqoop only supports RDB data synchronization and has some limitations on data files, and there is no concept of data cleansing yet.
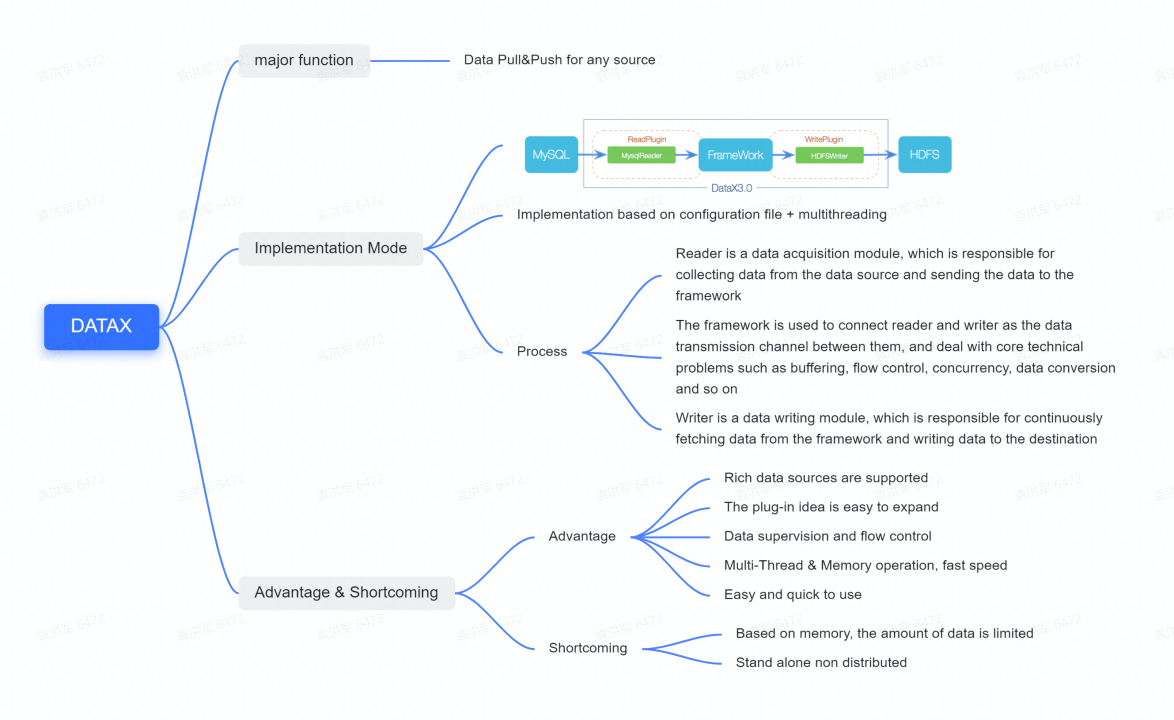
DataX mainly aims at synchronizing data from any source by configurable files + multi-threading, which runs three main processes: Reader, Framework, and Writer, where Framework mainly plays the role of communication and leaving empty space.
The advantage of DataX is that it uses plug-in development, has its own flow control and data control, and is active in the community, with DataX’s official website offering data pushes from many different sources. The disadvantage of DataX, however, is that it is memory-based and there may be limitations on the amount of data available.
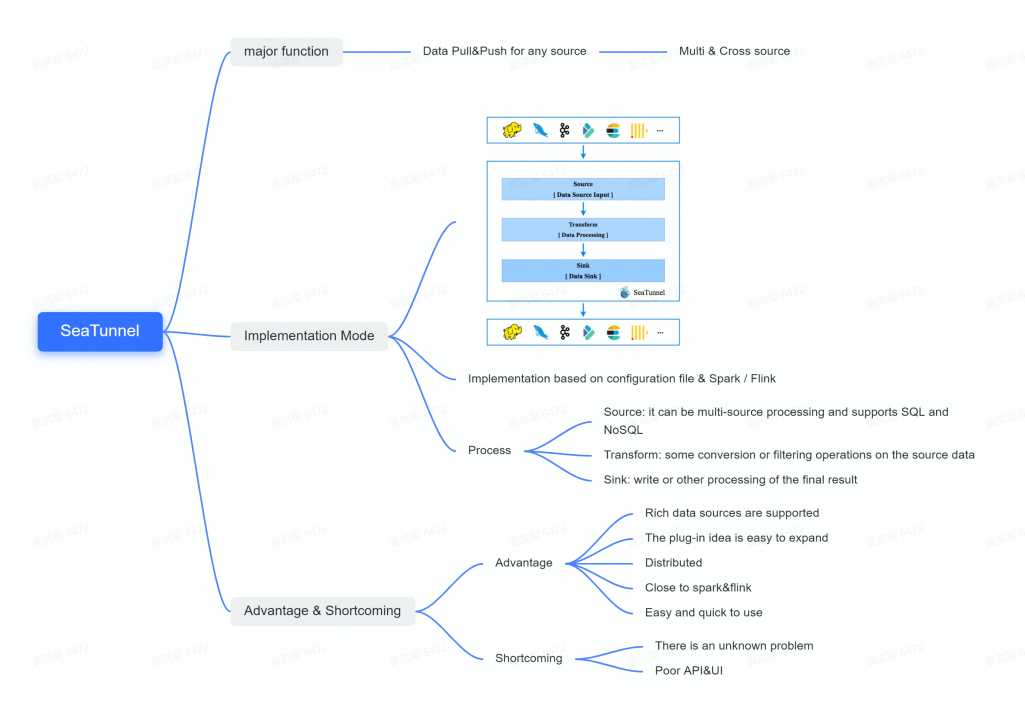
Apache SeaTunnel (Incubating) also does data synchronization from any source and implements the process in three steps: source, transform and sink based on configuration files, Spark or Flink.
The advantage is that the current 2.1.0 version has a very large number of plug-ins and source pushes, based on the idea of plug-ins also makes it very easy to extend and embrace Spark and Flink while with a distributed architecture. The only downside to Apache SeaTunnel (Incubating) is probably the lack of IP calls at the moment and the need to manage the UI interface by yourself.
In summary, although Sqoop is distributed, it only supports data synchronization between RDB and HIVE, Hbase and has poor scalability, which is not convenient for re-development. DataX is scalable and stable overall, but because it is a standalone version, it cannot be deployed in a distributed cluster, and there is a strong dependency between data extraction capability and machine performance. SeaTunnel, on the other hand, is similar to DataX and makes up for the flaw of non-distributed DataX. It also supports real-time streaming, and the community is highly active as a new product. We chose SeaTunnel based on a number of factors such as whether it supported distributed or not, and whether it needed to be deployed on a separate machine.
03 Implementation
On the Apache SeaTunnel (Incubating) website, we can see that the basic process of Apache SeaTunnel (Incubating) consists of three parts: source, transform and sink. According to the guidelines on the website, Apache SeaTunnel (Incubating) requires a configuration script to start, but after some research, we found that the final execution of Apache SeaTunnel (Incubating) is bansed on an application submitted by spark-submit that relies on the config file.
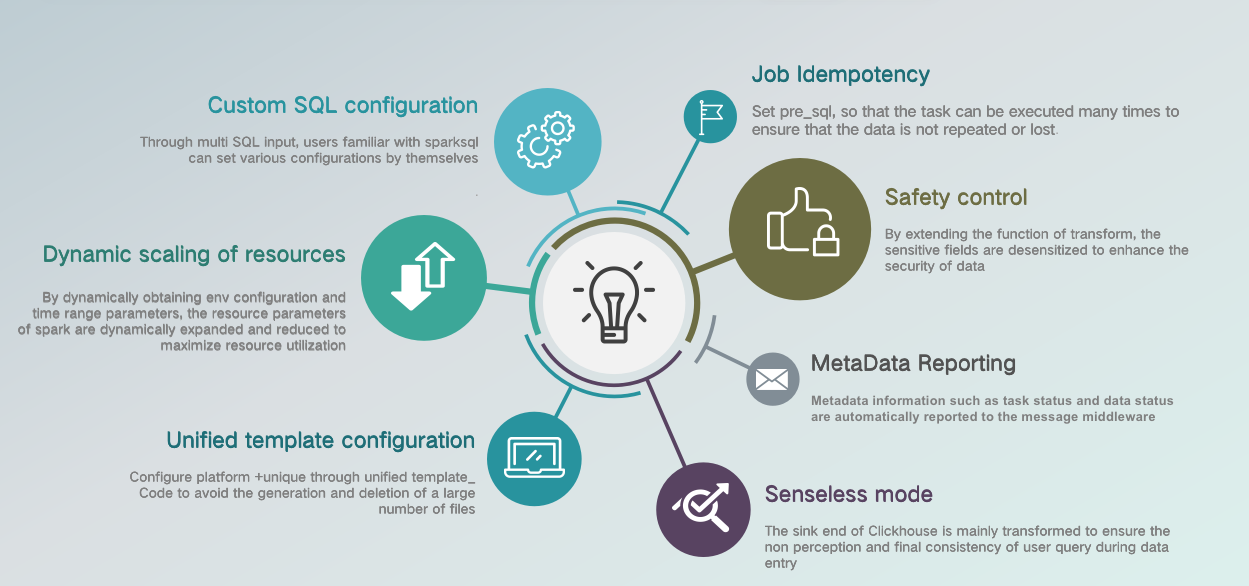
This initialization, although simple, has the problem of having to rely on the config file, which is generated and then cleared after each run, and although it can be dynamically generated in the scheduling script, it raises two questions: 1) whether frequent disk operations make sense; and 2) whether there is a more efficient way to support Apache SeaTunnel (Incubating).
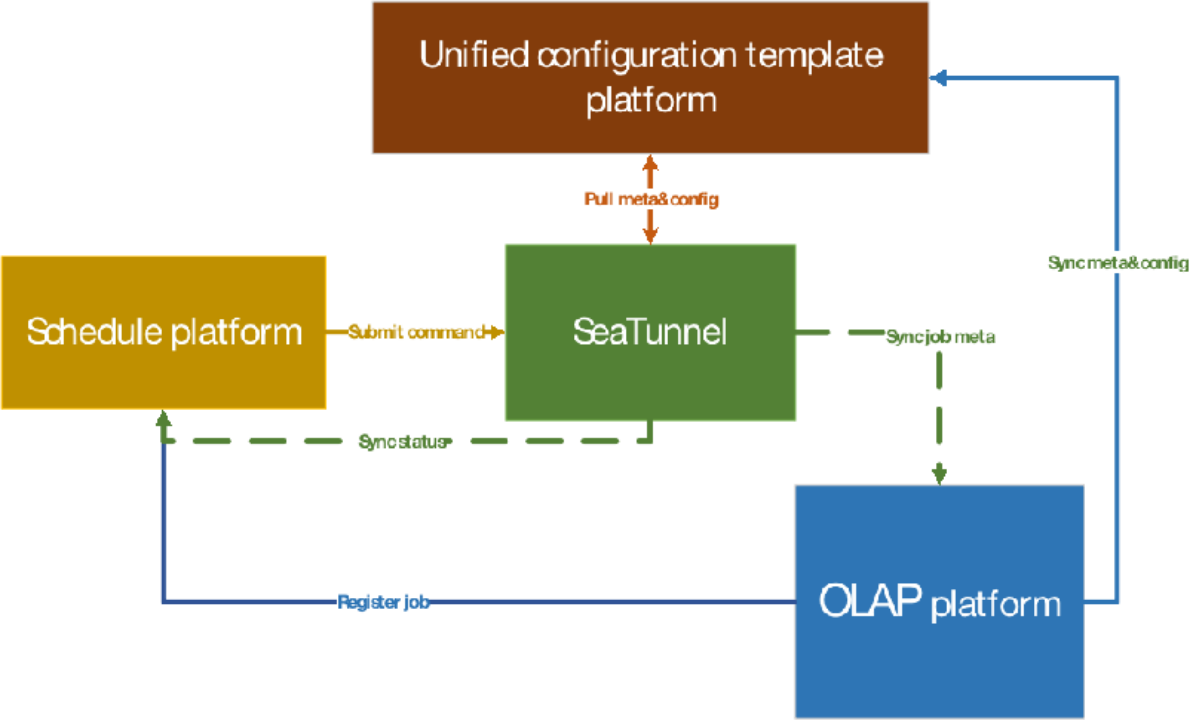
With these considerations in mind, we added a Unified Configuration Template Platform module to the final design solution. Scheduling is done by initiating a commit command, and Apache SeaTunnel (Incubating) itself pulls the configuration information from the unified configuration template platform, then loads and initializes the parameters.
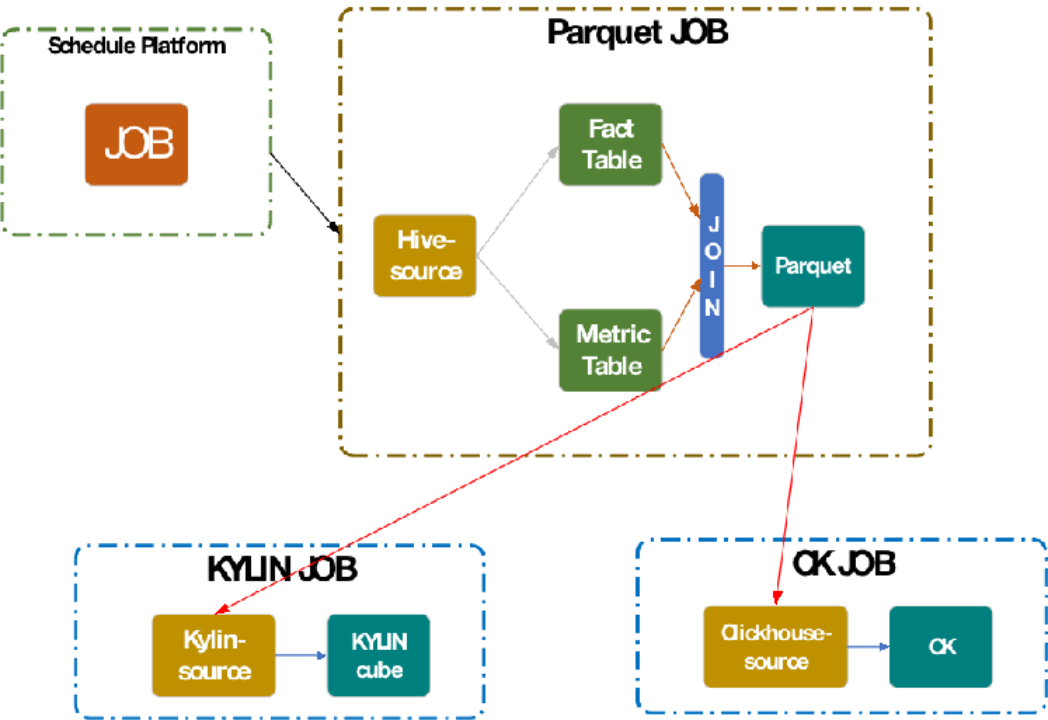
The diagram above shows the business process for Kidswant’s OLAP, which is divided into three sections. The overall flow of data from Parquet, i.e. Hive, through the Parquet tables to KYLIN and CK source.
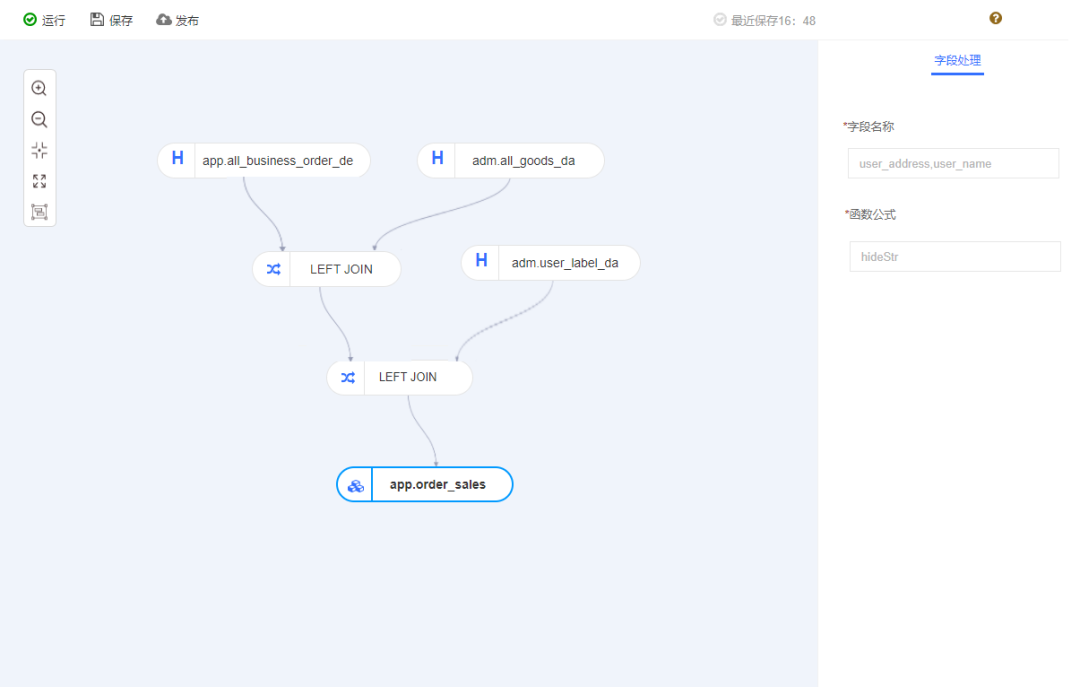
This is the page where we construct the model, which is generated mainly through drag and drop, with some transactional operations between each table, and micro-processing for Apache SeaTunnel (Incubating) on the right.
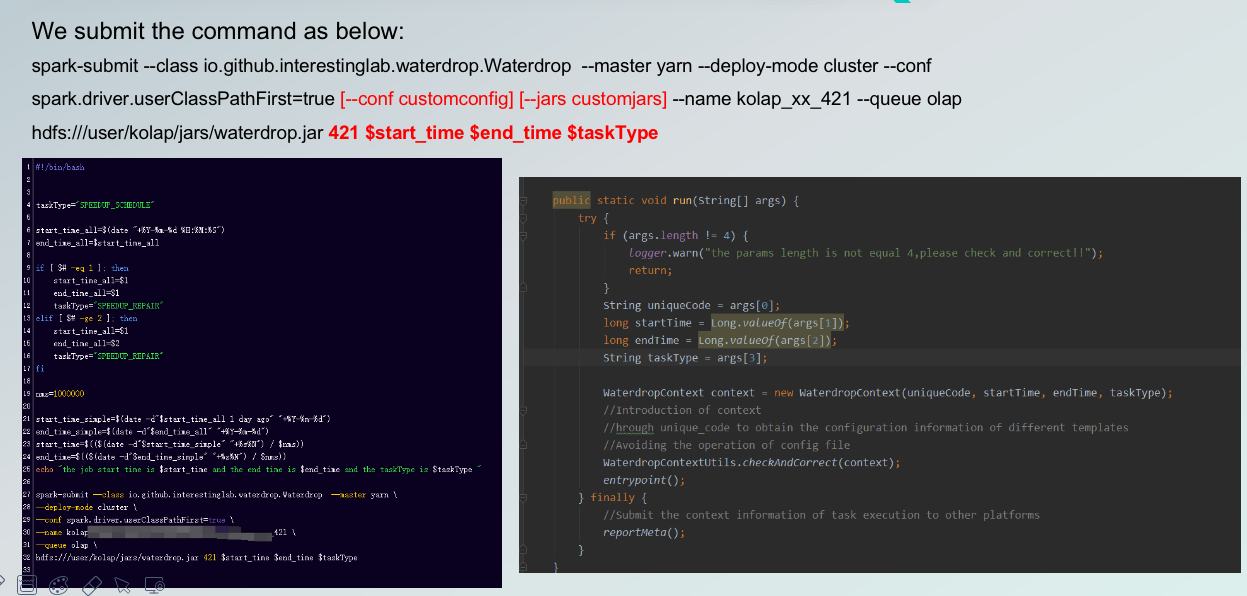
So we end up submitting the commands as above, where the first one marked in red is [-conf customconfig/jars], referring to the fact that the user can then unify the configuration template platform for processing, or specify it separately when modeling. The last one marked in red is [421 $start_time $end_time $taskType] Unicode, which is a unique encoding.
Below, on the left, are the 38 commands submitted by our final dispatch script. Below, on the right, is a modification made for Apache SeaTunnel (Incubating), and you can see a more specific tool class called WaterdropContext. It can first determine if Unicode exists and then use Unicode_code to get the configuration information for the different templates, avoiding the need to manipulate the config file.
In the end, the reportMeta is used to report some information after the task is completed, which is also done in Apache SeaTunnel (Incubating).
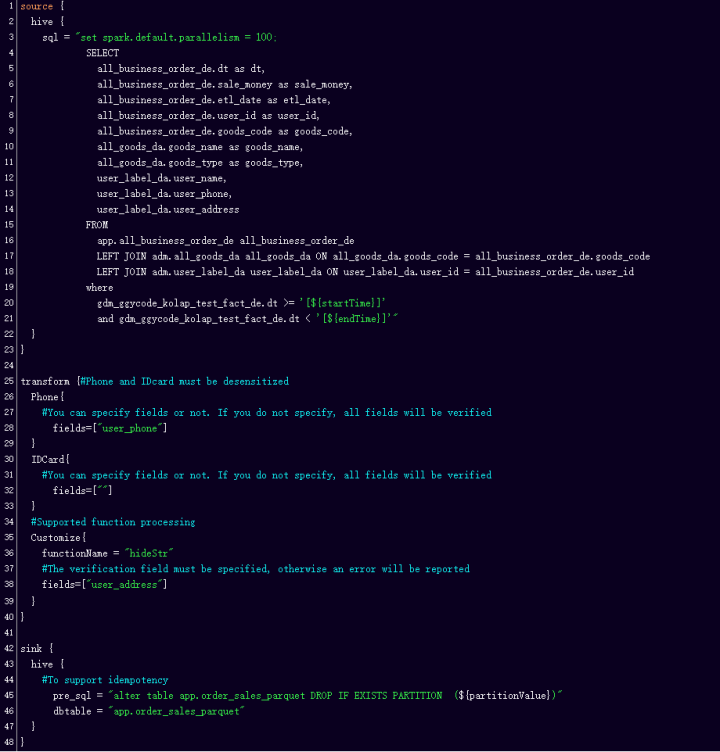
In the finalized config file as above, it is worth noting that in terms of transforms, Kidswant has made some changes. The first is to do desensitization for mobile phones or ID numbers etc. If the user specifies a field, they do it by field, if not they will scan all fields and then desensitize and encrypt them according to pattern matching.
Second, transform also supports custom processing, as mentioned above when talking about OLAP modeling. With the addition of HideStr, the first ten fields of a string of characters can be retained and all characters at the back encrypted, providing some security in the data.
Then, on the sink side, we added pre_sql in order to support the idempotency of the task, which is mainly done for tasks such as data deletion, or partition deletion, as the task cannot be run only once during production, and this design needed to account for the data deviation and correctness once operations such as reruns or complement occur.
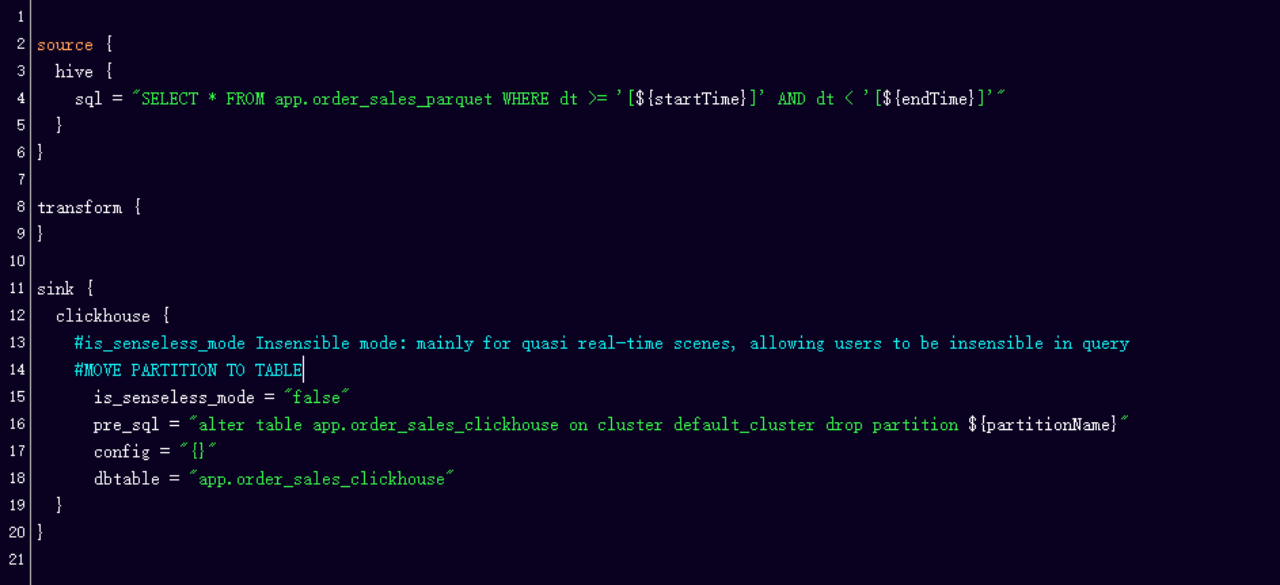
On the right side of the diagram, on the Sink side of a Clickhouse, we have added an is_senseless_mode, which forms a read/write senseless mode, where the user does not perceive the whole area when querying and complementing but uses the CK partition conversion, i.e. the command called MOVE PARTITION TO TABLE to operate.
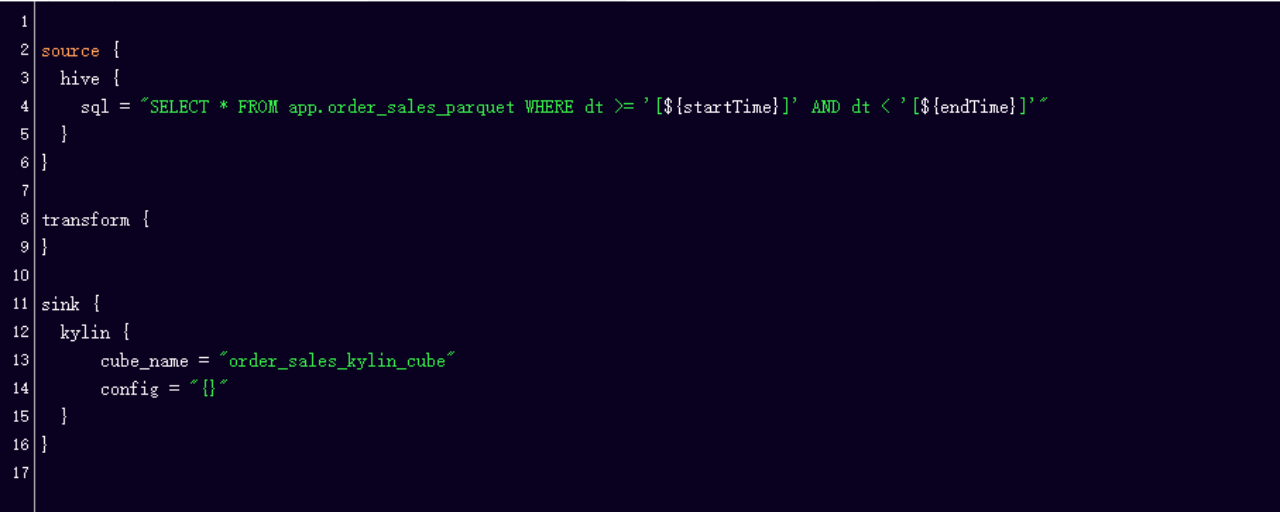
A special note here is the Sink side of KYLIN. KYLIN is a very special source with its own set of data entry logic and its monitoring page, so the transformation we have done on KYLIN is simply a call to its API operation and a simple API call and constant polling of the state when using KYLIN, so the resources for KYLIN are limited in the Unified Template Configuration platform.
04 Common problems about the Apache SeaTunnel (Incubating) transformation
01 OOM & Too Many Parts
The problem usually arises during the Hive to Hive process, even if we go through automatic resource allocation, but there are cases where the data amount suddenly gets bigger, for example after holding several events. Such problems can only be avoided by manually and dynamically tuning the reference and adjusting the data synchronization batch time. In the future, we may try to control the data volume to achieve fine control.
02 Field and type inconsistency issues
When the model runs, the user will make some changes to the upstream tables or fields that the task depends on, and these changes may lead to task failure if they are not perceived. The current solution is to rely on data lineage+ snapshots for advance awareness to avoid errors.
03 Custom data sources & custom separators
If the finance department requires a customized separator or jar information, the user can now specify the loading of additional jar information as well as the separator information themselves in the unified configuration template platform.
04 Data skewing issues
This may be due to users setting their parallelism but not being able to do so perfectly. We haven’t finished dealing with this issue yet, but we may add post-processing to the Source module to break up the data and complete the skew.
05 KYLIN global dictionary lock problem
As the business grows, one cube will not be able to meet the needs of the users, so it will be necessary to create more than one cube. If the same fields are used between multiple cubes, the problem of KYLIN global dictionary lock will be encountered. The current solution is to separate the scheduling time between two or more tasks, or if this is not possible, we can make a distributed lock control, where the sink side of KYLIN has to get the lock to run.
05 An outlook on the future of Kidswant
- Multi-source data synchronization, maybe processing for RDB sources
- Real-time Flink-based implementation
- Take over the existing collection and scheduling platform (mainly to solve the problem of splitting library and tables)
- Data quality verification, like some null values, the vacancy rate of the whole data, main time judgment, etc.
This is all I have to share, I hope we can communicate more with the community in the future and make progress together, thanks!