Guest speaker: Vip Senior Big Data Engineer Wang Yu Lecture preparation: Zhang Detong
Introduction: Vip referenced SeaTunnel as early as version 1.0. We use SeaTunnel to perform some data interaction work between Hive and ClickHouse. Today's presentation will focus on the following points:
- Requirements and pain points of ClickHouse data import;
- Selection of ClickHouse warehousing and warehousing tools;
- Hive to ClickHouse;
- ClickHouse to Hive;
- Integration of SeaTunnel and Vipshop data platform;
- Future outlook;
Requirements and pain points of ClickHouse data import
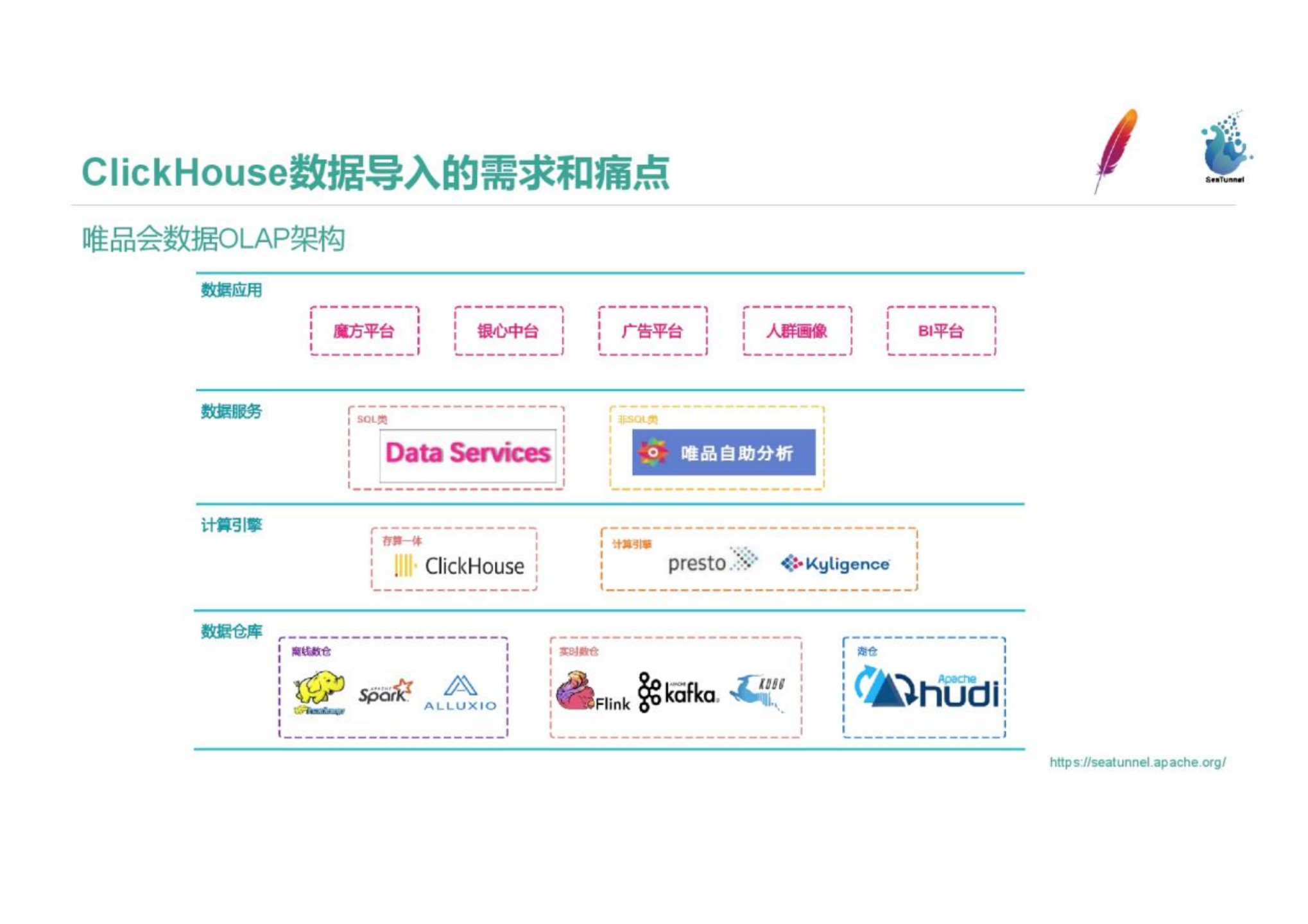
1. Vipshop Data OLAP Architecture
The picture shows the OLAP architecture of Vipshop. The modules we are responsible for are the data service and the computing engine in the picture. The underlying data warehouses are divided into offline data warehouses, real-time data warehouses, and lake warehouses. For computing engines, we use Presto, Kylin and Clickhouse. Although Clickhouse is a storage-integrated OLAP database, we have included it in the computing engine part in order to take advantage of Clickhouse's excellent computing performance. Based on OLAP components, we provide SQL data services and non-SQL independent analysis of Vipshop to serve different intelligences. For example, non-SQL services are services that provide data analysis that is closer to the business for BI and commerce. Multiple data applications are abstracted on top of data services.
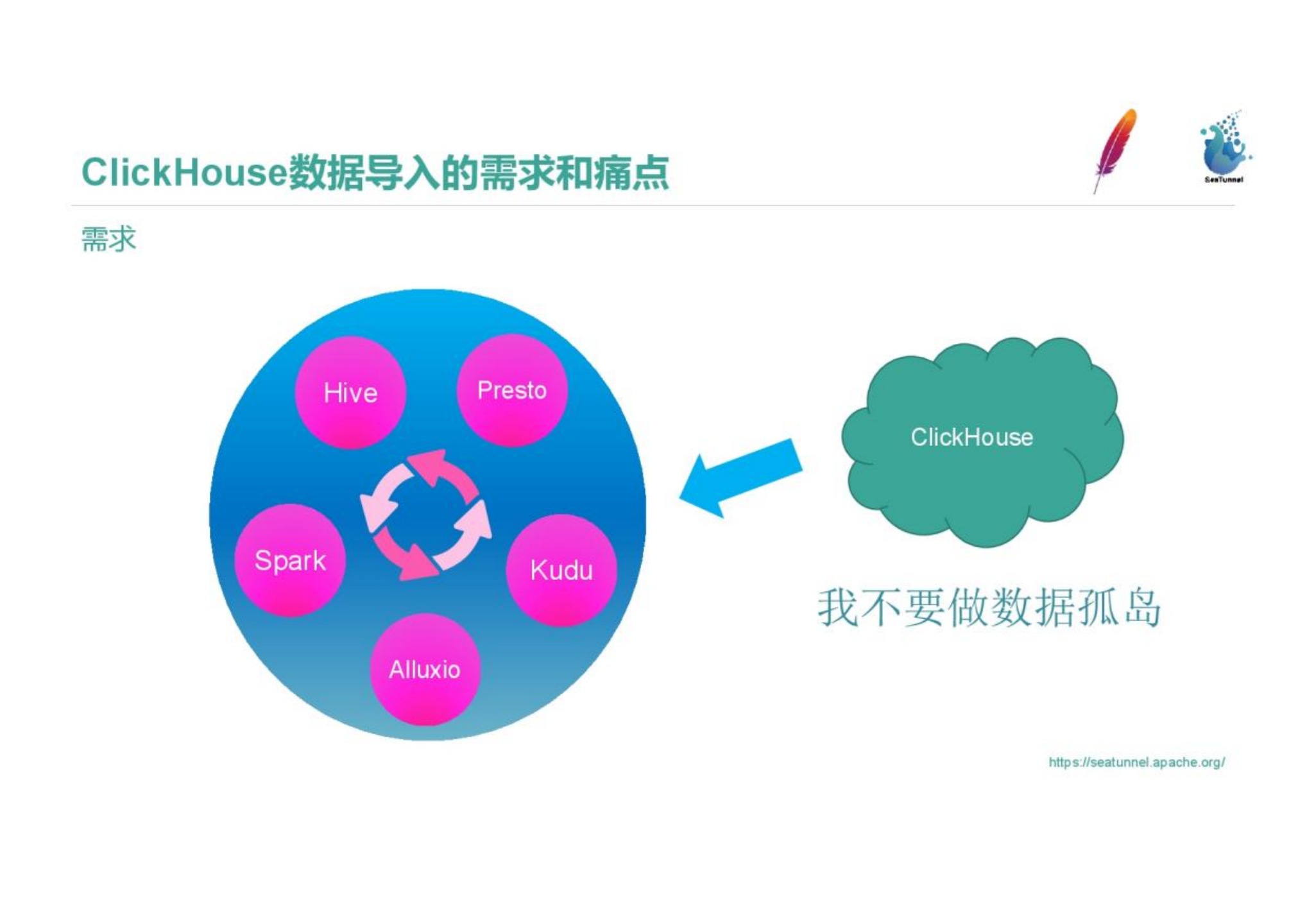
2. Requirements
We connect the underlying Hive, Kudu, and Alluxio components through Presto Connector and Spark components. Big data components can import and export data to and from each other, and you can use appropriate components to analyze data according to the needs and scenarios of data analysis. But when we introduced Clickhouse, it was a data island, and it was difficult to import and export data. There is a lot of work between Hive and Clickhouse to implement import and export. Our first data import and export requirement is to improve the import and export efficiency and incorporate Clickhouse into the big data system.
The second requirement is that Presto runs SQL relatively slowly. The figure shows an example of slow SQL. The SQL where condition in the figure sets the date, time range, and specific filter conditions. This kind of SQL usage runs slowly because Presto uses partition granularity to push down. Even after optimization by other methods such as Hive's bucket table and bucketing, the return time is a few seconds, which cannot meet business requirements. In this case, we need to use Clickhouse for offline OLAP computing acceleration.

Our real-time data is written to Clickhouse through Kafka and Flink SQL. However, it is not enough to use real-time data for analysis. It is necessary to use the Hive dimension table and the T+1 real-time table with the ETL calculation number for accelerated transportation in Clickhouse. This requires importing Hive data into Clickhouse, which is our third requirement.
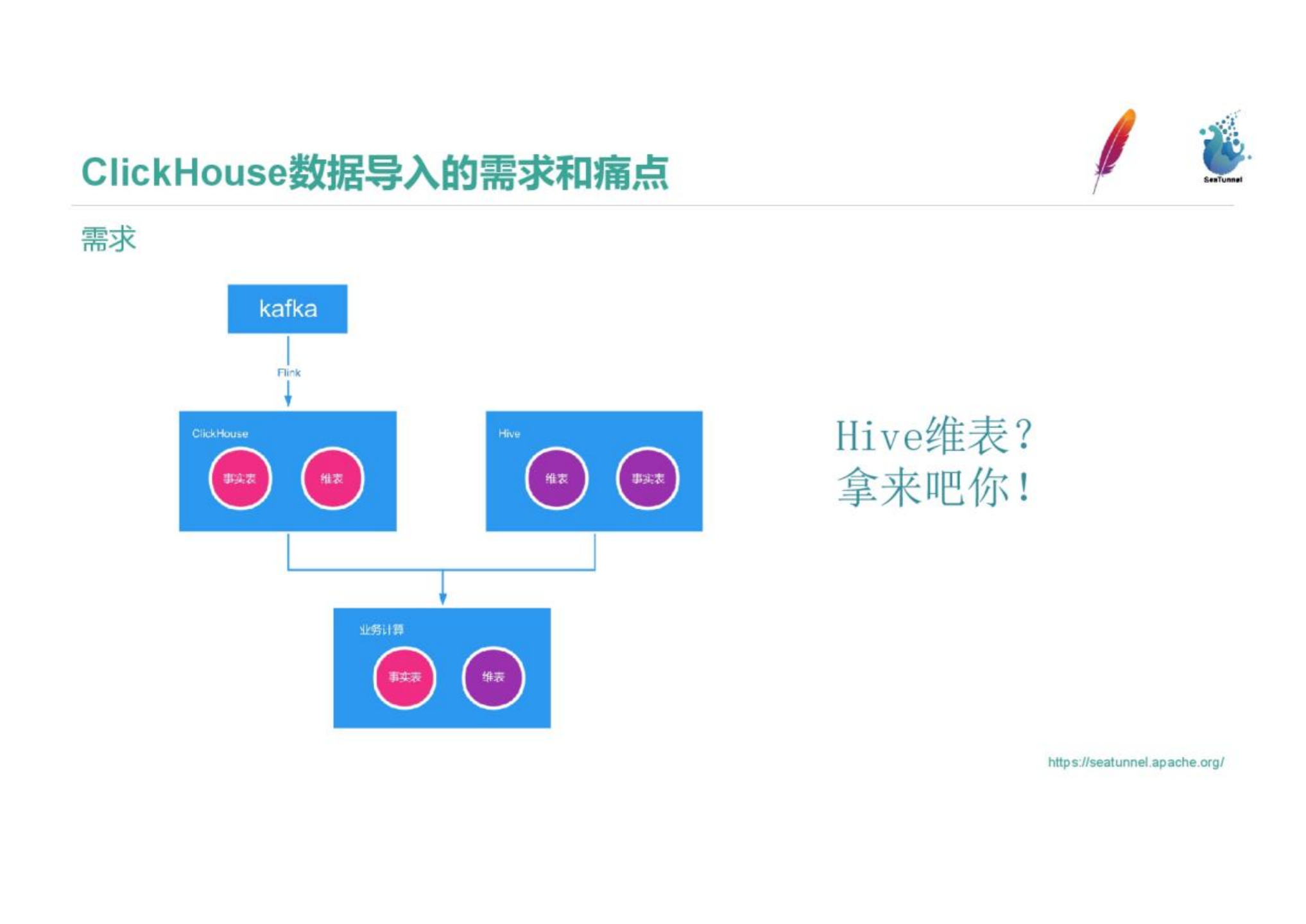
3. Pain points
First, we introduce a data component to consider its performance. The granularity of the Hive table is five minutes. Is there a component that can support a short ETL process and import the ETL results into Clickhouse within five minutes? Second, we need to ensure the quality of the data, and the accuracy of the data needs to be guaranteed. The number of data entries in Hive and Clickhouse needs to be consistent. If there is a problem with the data quality, can the data be repaired by rerunning and other mechanisms? Third, are the data types that data import needs to support complete? The data types and some mechanisms between different databases are different. We have data types such as HiperLogLog and BitMap that are widely used in a certain storage engine. Whether they can be correctly transmitted and identified, and can be used well.
Selection of ClickHouse and Hive warehousing and warehousing tools
Based on the pain points in the data business, we have compared and selected data warehouse and warehouse tools. We mainly choose among open source tools, without considering commercial warehouse entry and exit tools, we mainly compare DataX, SeaTunnel, and write Spark programs and use jdbc to insert ClickHouse among the three options.
SeaTunnel and Spark rely on Vipshop's own Yarn cluster, which can directly implement distributed reading and writing. DataX is non-distributed, and the startup process between Reader and Writer takes a long time, and the performance is ordinary. The performance of SeaTunnel and Spark for data processing can reach several times that of DataX.
Data of more than one billion can run smoothly in SeaTunnel and Spark. DataX has great performance pressure after the amount of data is large, and it is difficult to process data of more than one billion.
In terms of read and write plug-in scalability, SeaTunnel supports a variety of data sources and supports users to develop plug-ins. SeaTunnel supports data import into Redis.
In terms of stability, since SeaTunnel and DataX are self-contained tools, the stability will be better. The stability aspect of Spark requires attention to code quality.

The amount of data in our exposure table is in the billions of levels every day. We have the performance requirement to complete data processing within 5 minutes. We have the need to import and export data to Redis. We need import and export tools that can be connected to the data platform for task scheduling. . For the consideration of data volume, performance, scalability, and platform compatibility, we chose SeaTunnel as our data warehouse import and export tool.
Import Hive data into ClickHouse
The following will introduce our use of SeaTunnel.
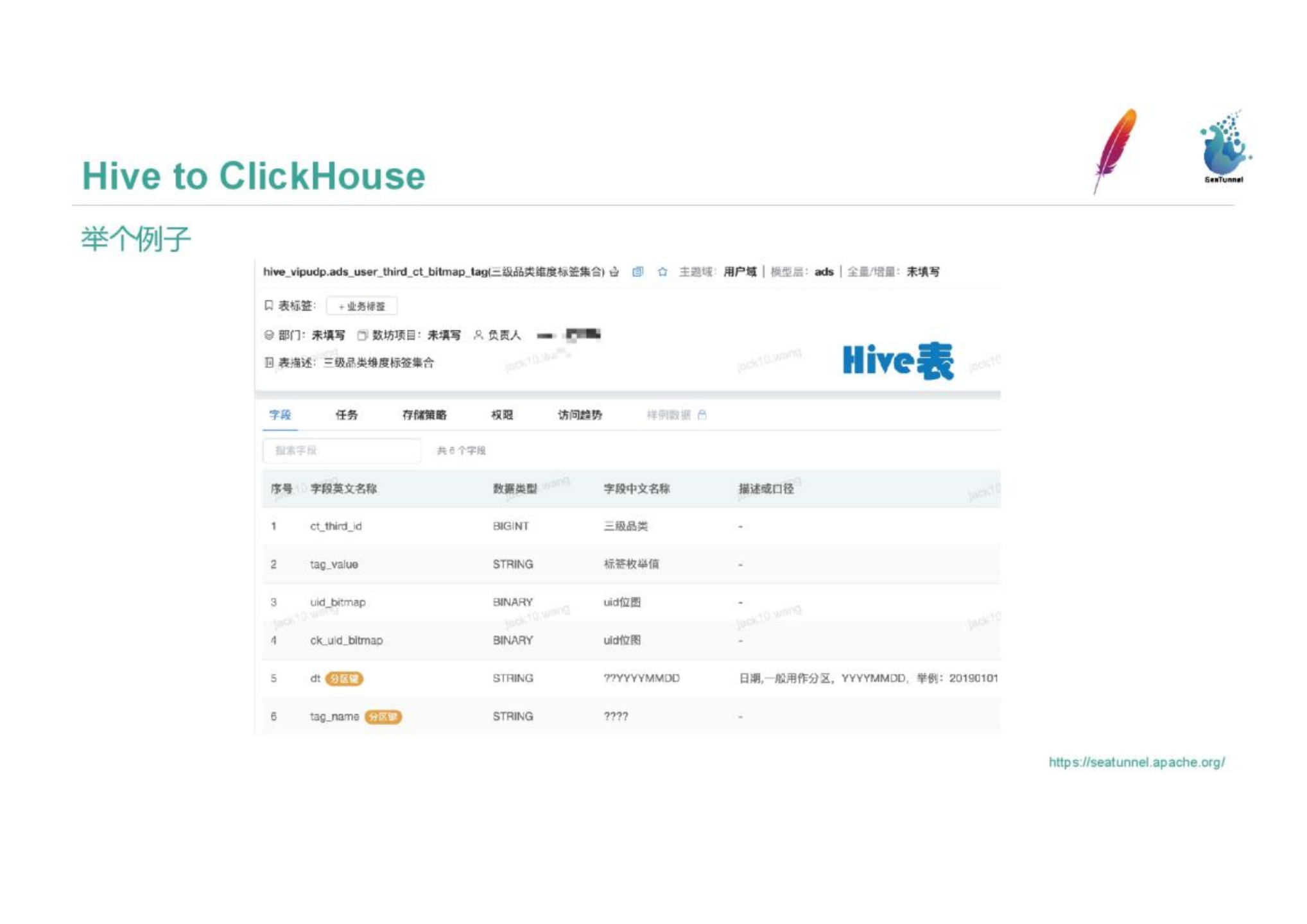
The picture is a Hive table, which is our three-level product dimension table, including category products, dimension categories, and user population information. The primary key of the table is a third-level category ct_third_id, and the following value is the bitmap of two uids, which is the bitmap type of the user id. We need to import this Hive table into Clickhouse.
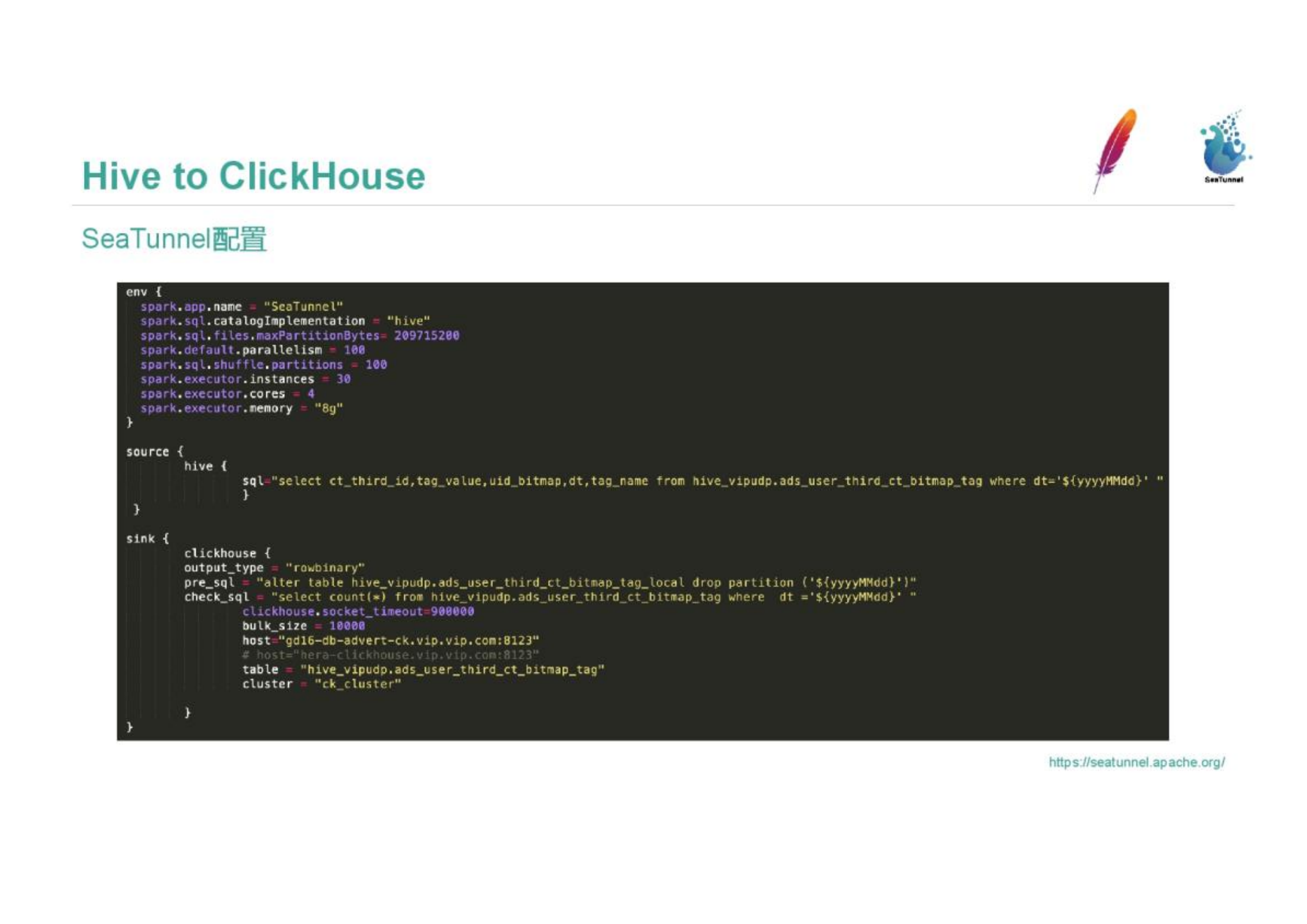
SeaTunnel is easy to install, and the official website documentation describes how to install it. The figure below shows the configuration of SeaTunnel. In the configuration, env, source and sink are essential. In the env part, the example in the figure is the Spark configuration. The configuration includes concurrency, etc. These parameters can be adjusted. The source part is the data source. The Hive data source is configured here, including a Hive Select statement. Spark runs the SQL in the source configuration to read the data. UDF is supported here for simple ETL; the sink part is configured with Clickhouse, and you can see output_type= rowbinary and rowbinary are the self-developed acceleration solutions of Vipshop; pre_sql and check_sql are self-developed functions for data verification, which will be described in detail later; clickhouse.socket_timeout and bulk_size can be adjusted according to the actual situation.
Run SeaTunnel, execute the sh script file, configure the conf file address and yarn information, and then you can.
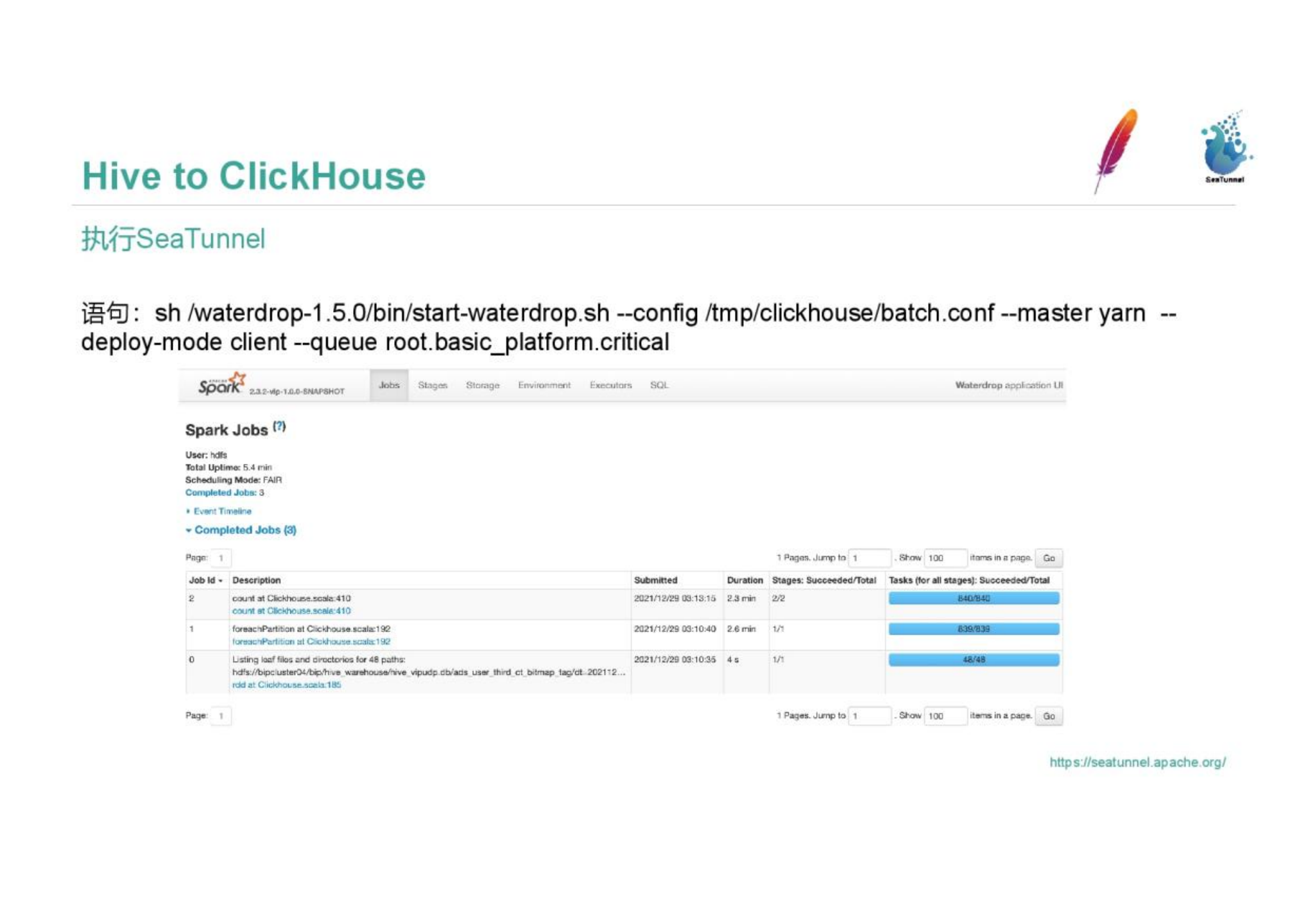 Spark logs are generated during the running process, and both successful running and running errors can be viewed in the logs.
Spark logs are generated during the running process, and both successful running and running errors can be viewed in the logs.

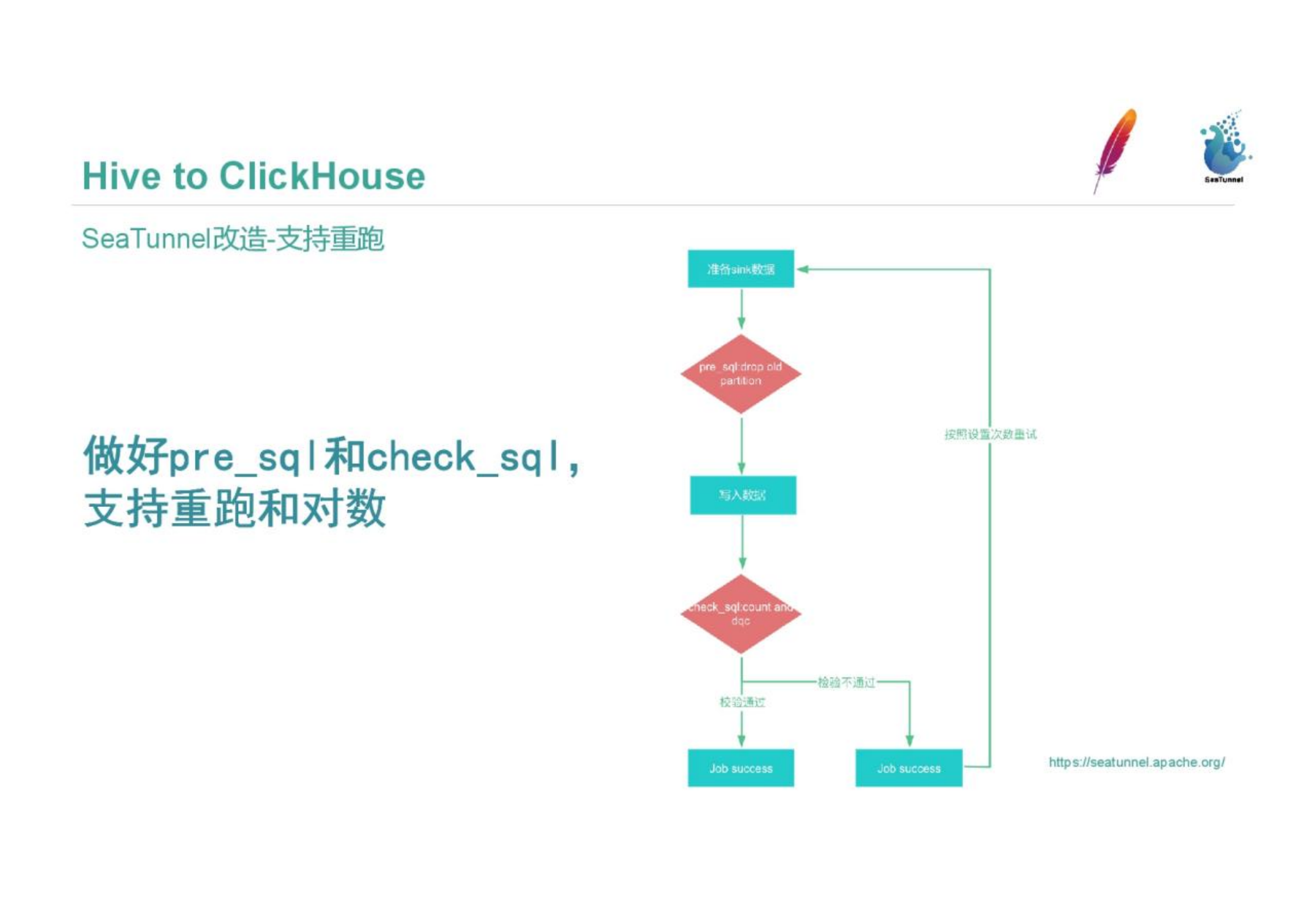
In order to better fit the business, Vipshop will make some improvements to SeaTunnel. All our ETL tasks need to be rerun. We support pre_sql and check_sql to implement data rerun and logarithm. The main process is to execute pre_sql for preprocessing after the data is ready, delete the old partition data in Clickhouse, store it in a directory, and restore the partition and rename when it fails. check_sql will check, and the whole process will end after the check is passed; if the check fails, it will be rerun according to the configuration, and if the rerun fails, the corresponding person in charge will be alerted.
Based on the 1.0 version of SeaTunnel, Vipshop has added RowBinary for acceleration, and it also makes it easier to import the binary files of HuperLogLog and BinaryBitmap from Hive to Clickhouse. We made changes in ClickHouse-jdbc, bulk_size, Hive-source. Use the extended api of CK-jdbc to write data to CK in rowbinary mode. Bulk_size introduces the control logic for writing to CK in rowbinary mode. Hive-source RDD is partitioned with HashPartitioner to break up data to prevent data from being skewed.
We also let SeaTunnel support multiple types. In order to circle the crowd, corresponding methods need to be implemented in Clickhouse, Preso, and Spark. We added Callback, HttpEntity, and RowBinaryStream that support Batch feature to Clickhouse-jdbc, added bitmap type mapping to Clickhouse-jdbc and Clickhouse-sink code, and implemented UDF of Clickhouse's Hyperloglog and Bitmap functions in Presto and Spark. In the previous configuration, the clickhouse-sink part can specify the table name, and here is the difference between writing to the local table and the distributed table. The performance of writing to a distributed table is worse than that of writing to a local table, which will put more pressure on the Clickhouse cluster. However, in scenarios such as exposure meter, flow meter, and ABTest, two tables are required to join, and both tables are in the order of billions. . At this time, we hope that the Join key falls on the local machine, and the Join cost is smaller. When we built the table, we configured the murmurHash64 rule in the distributed table distribution rules of Clickhouse, and then directly configured the distributed table in the sink of Seatunnel, handed the writing rules to Clickhouse, and used the characteristics of the distributed table to write. Writing to the local table will put less pressure on Clickhouse, and the performance of writing will be better. In Seatunnel, we go to Clickhouse's System.cluster table to obtain the table distribution information and machine distribution host according to the sink's local table. Then write to these hosts according to the equalization rule. Put the distributed writing of data into Seatunnel. For the writing of local tables and distributed tables, our future transformation direction is to implement consistent hashing in Seatunnel, write directly according to certain rules, such as Clickhouse, without relying on Clickhouse itself for data distribution, and improve Clickhouse's high CPU load problem.
ClickHouse data import into Hive
We have the needs of people in the circle. Every day, Vipshop gathers 200,000 people in the supplier circle, such as people born in the 1980s, Gao Fushuai, and Bai Fumei. These Bitmap crowd information in Clickhouse needs to be exported to the Hive table, coordinated with other ETL tasks in Hive, and finally pushed to PIKA for use by external media. We made SeaTunnel back-push Clickhouse Bitmap crowd data to Hive.
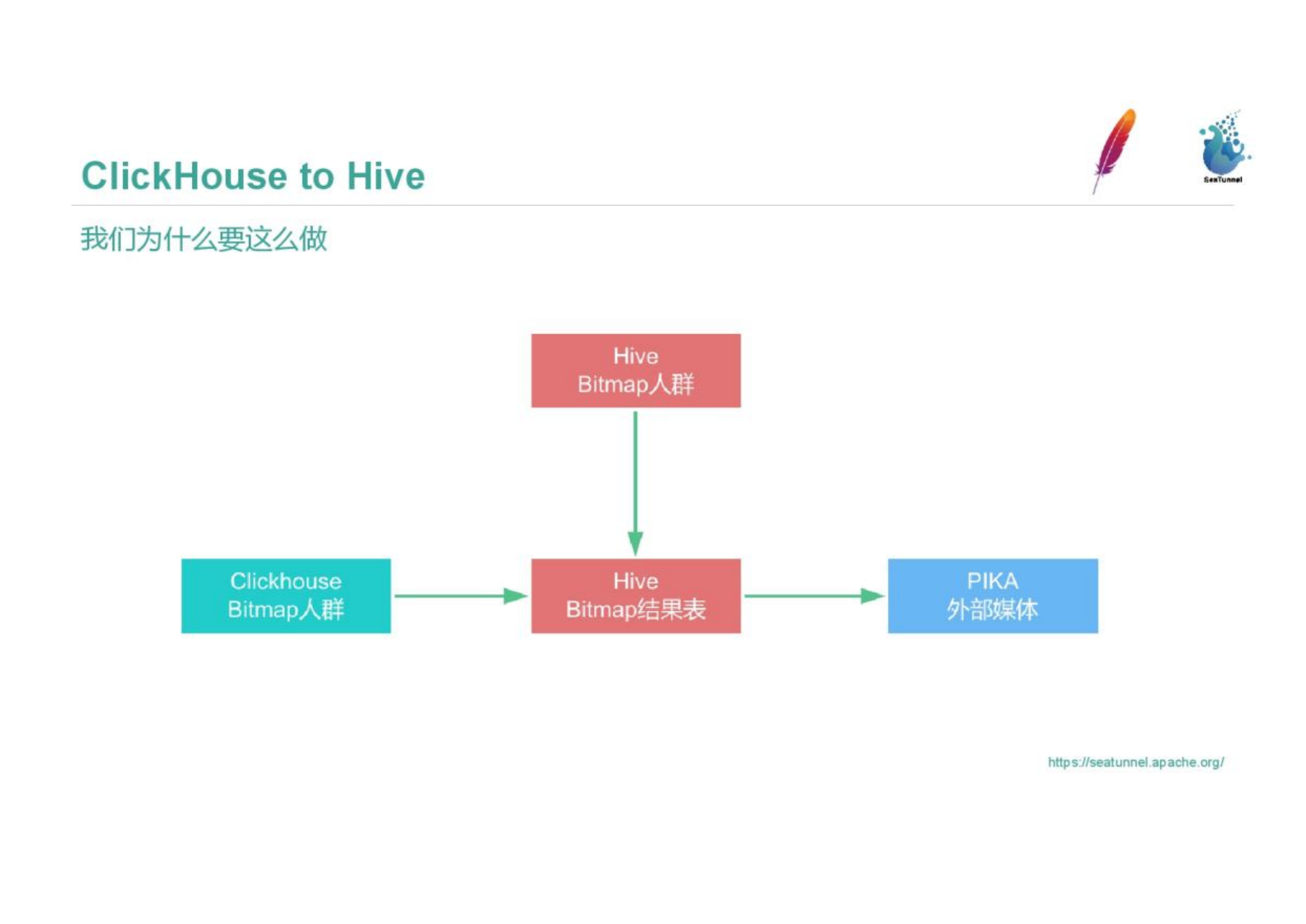
The figure shows the SeaTunnel configuration. We configure the source as Clickhouse, the sink as Hive, and the data verification is also configured in Hive.

Since we access SeaTunnel earlier, we have processed some modules, including adding plugin-spark-sink-hive module, plugin-spark-source-ClickHouse module, and rewriting Spark Row related methods so that they can be packaged through The Clickhouse data mapped by Schem, reconstruct the StructField and generate the DataFrame that finally needs to land on Hive. The latest version has many source and sink components, which is more convenient to use in SeaTunnel. It is now also possible to integrate the Flink connector directly in SeaTunnel.
Integration of SeaTunnel and Vipshop Data Platform
Each company has its own scheduling system, such as Beluga, Zeus. The scheduling tool of Vipshop is Shufang, and the scheduling tool integrates the data transmission tool. The following is the architecture diagram of the scheduling system, which includes the entry and exit of various types of data.
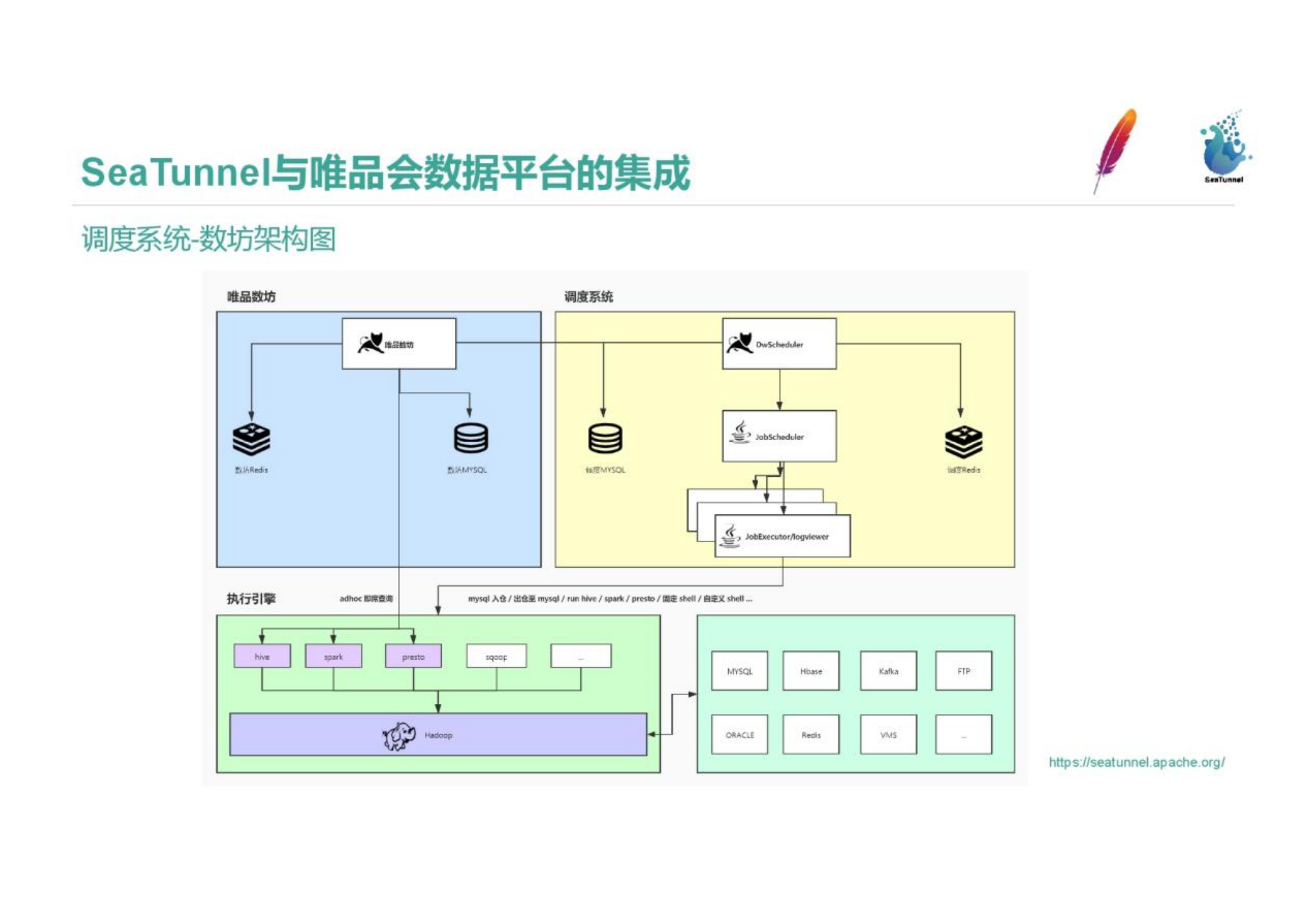
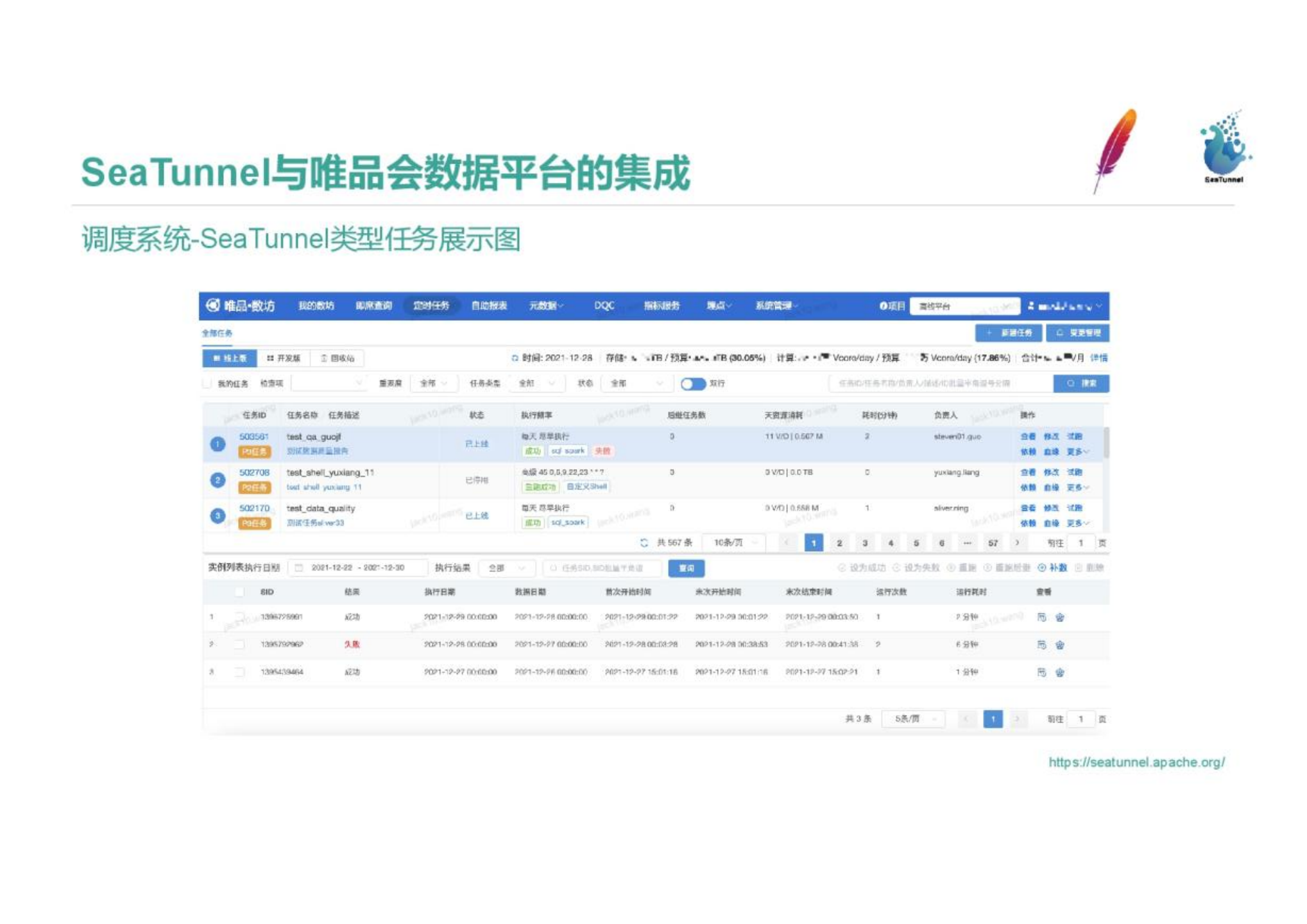
The SeaTunnel task type is integrated into the platform. The picture is a screenshot of the scheduled task of Shufang. You can see that the selected part is a configured SeaTunnel task. resource information. The following shows the historical running instance information.
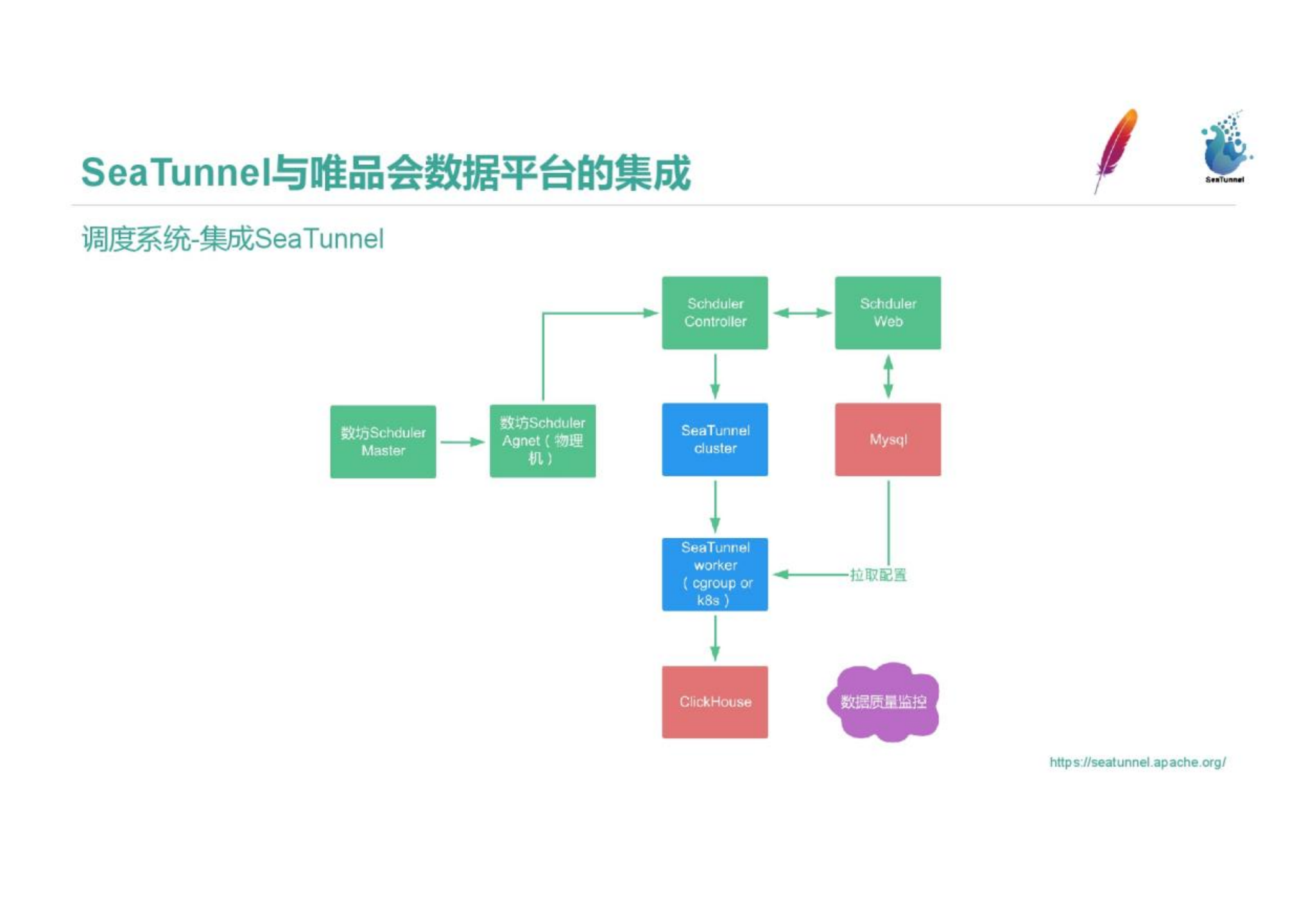
We integrated SeaTunnel into the scheduling system. The Shufang Scheduling Master will assign tasks to the corresponding Agents according to the task types, and assign them to the appropriate machines to run according to the Agent load. The controller pulls the task scheduling configuration and information in the foreground. After arriving, a SeaTunnel cluster is generated and executed in a virtual environment similar to k8s pod and cgroup isolation. The running result will be judged by the data quality monitoring of the scheduling platform whether the task is completed and whether the operation is successful, and if it fails, it will rerun and alarm.
SeaTunnel itself is a tool-based component, which is used to manage and control data blood relationship, data quality, historical records, high-alert monitoring, and resource allocation. We integrate SeaTunnel into the platform, and we can take advantage of the platform to take advantage of SeaTunnel.
SeaTunnel is used for processing in the deposit crowd. By managing data, we divide the circled people into different people according to their paths and usage conditions, or thousands of people and thousands of faces, tag users, and push a certain type of people circled to users, analysts and suppliers.
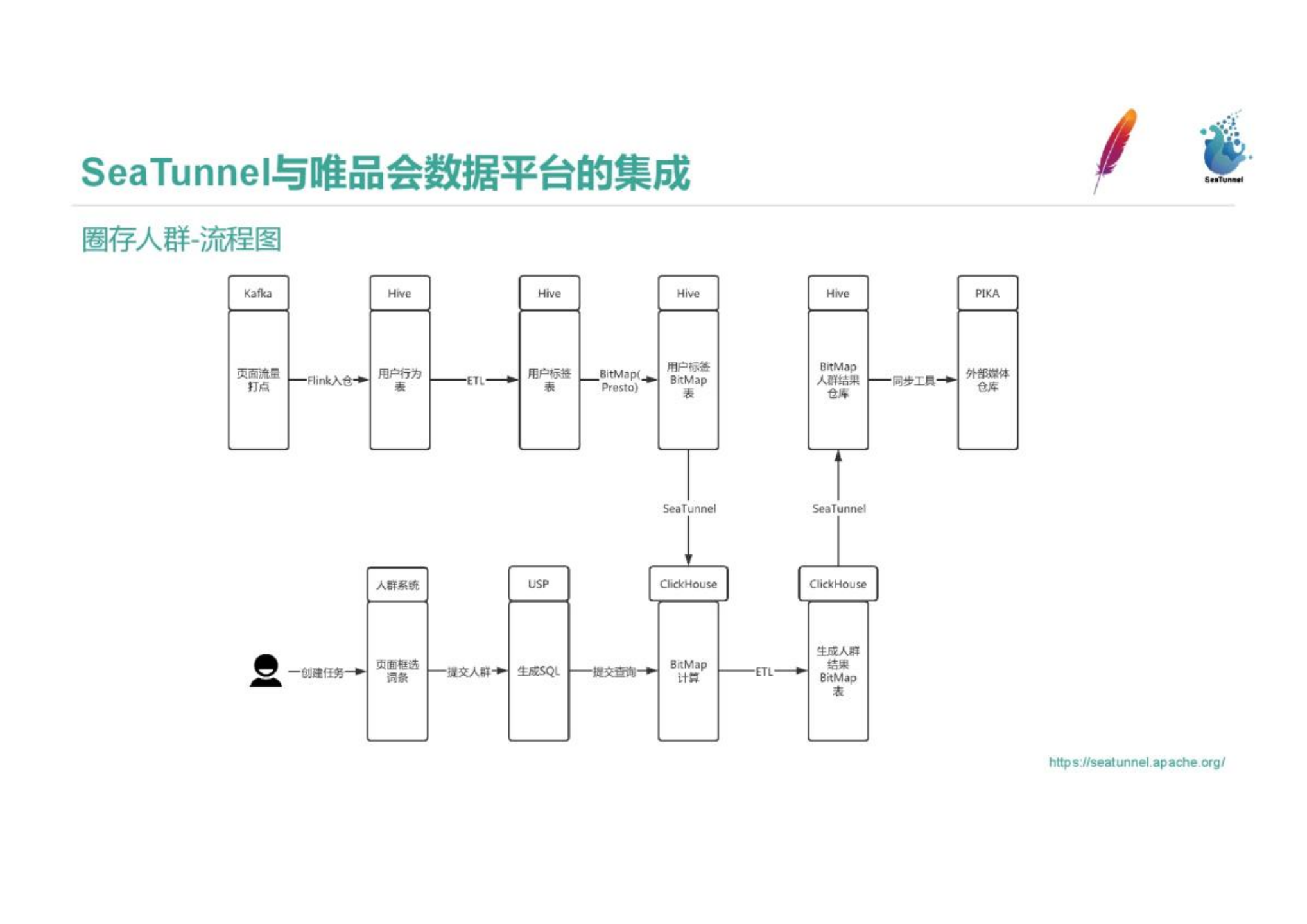
The traffic enters Kafka, enters the warehouse through Flink, and then forms a user label table through ETL. After the user label table is generated, we use the BitMap method implemented by Presto to type the data into a wide table in Hive. Users create tasks by box-selecting entries on the crowd system page, submit to Tengqun, and generate SQL query Clickhouse BitMap. Clickhouse's BitMap query speed is very fast. Due to its inherent advantages, we need to import Hive's BitMap table into Clickhouse through SeaTunnel. After the crowd is circled, we need to land the table to form a partition or a record of Clickhouse, and then store the resulting BitMap table in Hive through SeaTunnel. Finally, the synchronization tool will synchronize Hive's BitMap crowd results to the external media repository Pika. Around 20w people are circled every day. During the whole process, SeaTunnel is responsible for exporting the data from Hive to Clickhouse. After the ETL process of Clickhouse is completed, SeaTunnel exports the data from Clickhouse to Hive. In order to fulfill this requirement, we implemented UDFs of ClickHouse's Hyperloglog and BitMap functions on Presto and Spark; we also developed the Seatunnel interface, so that the crowds circled by users using the Bitmap method in ClickHouse can be directly written to the Hive table through Seatunnel , without an intermediate landing step. Users can also call the SeaTunnel interface through spark to circle the crowd or reverse the crowd bitmap in Hive, so that the data can be directly transmitted to the ClickHouse result table without intermediate landing.
Follow-up
In the future, we will further improve the problem of high CPU load when Clickhouse writes data. In the next step, we will implement the CK-local mode of Clickhouse data source and read end in SeaTunnel, separate read and write, and reduce Clickhouse pressure. In the future we will also add more sink support, such as data push to Pika and corresponding data checking.