
在Apache SeaTunnel(Incubating) 4 月Meetup上,孩子王大数据专家、OLAP平台架构师 袁洪军 为我们带来了《Apache SeaTunnel (Incubating)在孩子王的应用实践》。
本次演讲主要包含五个部分:
孩子王引入Apache SeaTunnel (Incubating)的背景介绍
大数据处理主流工具对比分析
Apache SeaTunnel (Incubating)的落地实践
Apache SeaTunnel (Incubating)改造中的常见问题
对孩子王未来发展方向的预测展望

袁洪军
孩子王 大数据专家、OLAP 平台架构师。多年大数据平台研发管理经验,在数据资产、血缘图谱、数据治理、OLAP 等领域有着丰富的研究经验。
01 背景介绍
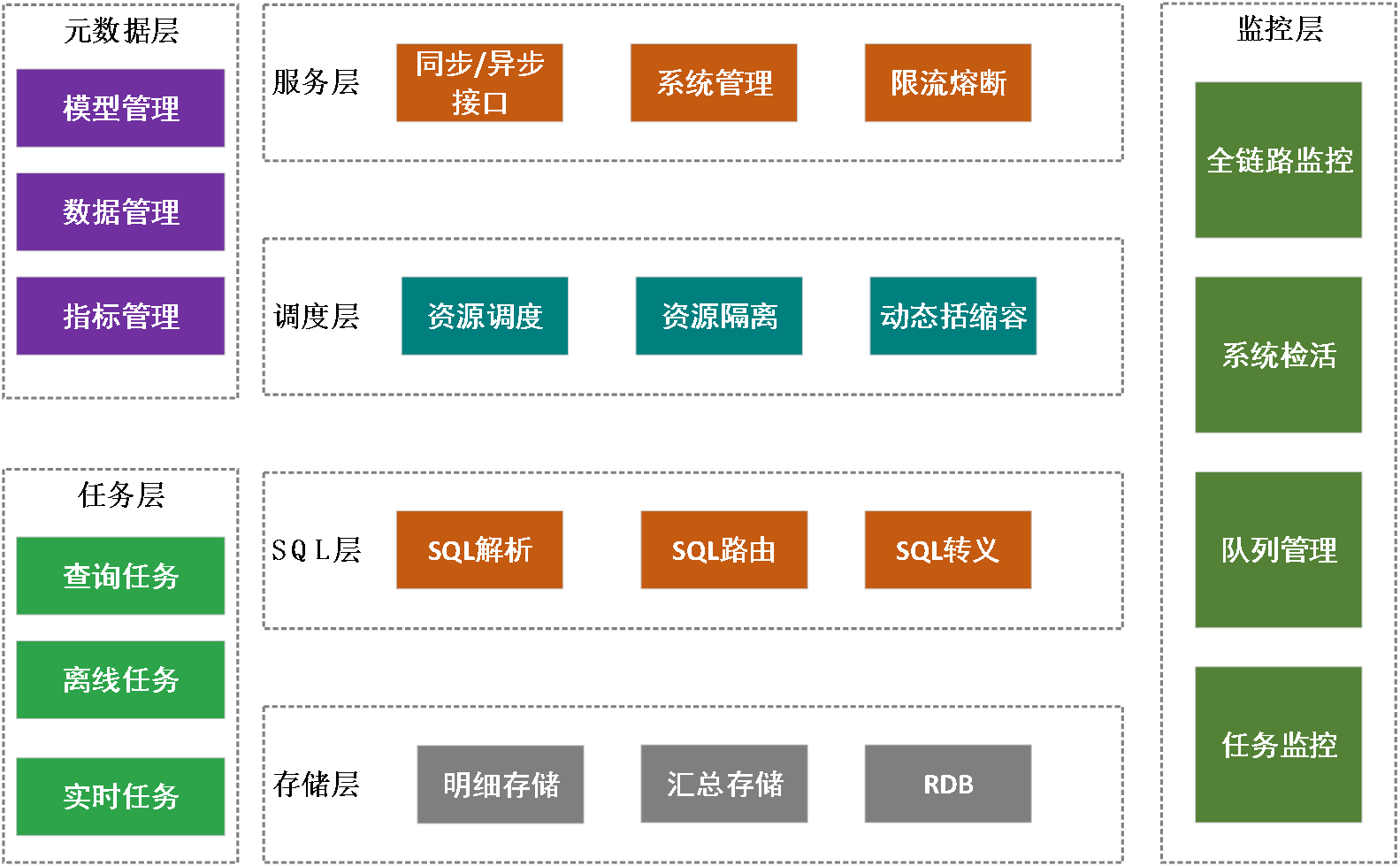
目前孩子王的OLAP平台主要包含元数据层、任务层、存储层、SQL层、调度层、服务层以及监控层七部分,本次分享主要关注任务层中的离线任务。
其实孩子王内部有一套完整的采集推送系统,但由于一些历史遗留问题,公司现有的平台无法快速支持OLAP平台上线,因此当时公司只能选择放弃自身的平台,转而着手研发新的系统。
当时摆在OLAP面前的有三个选择:
1、给予采集推送系统做二次研发;
2、完全自研;
3、参与开源项目。
02 大数据处理主流工具对比分析
而这三项选择却各有优劣。若采基于采集推送做二次研发,其优点是有前人的经验,能够避免重复踩坑。但缺点是代码量大,研读时间、研读周期较长,而且抽象代码较少,与业务绑定的定制化功能较多,这也导致了其二开的难度较大。
若完全自研,其优点第一是开发过程自主可控,第二是可以通过Spark等一些引擎做贴合我们自身的架构,但缺点是可能会遭遇一些未知的问题。
最后如果使用开源框架,其优点一是抽象代码较多,二是经过其他大厂或公司的验证,框架在性能和稳定方面能够得到保障。因此孩子王在OLAP数据同步初期,我们主要研究了DATAX、Sqoop和SeaTunnel这三个开源数据同步工具。
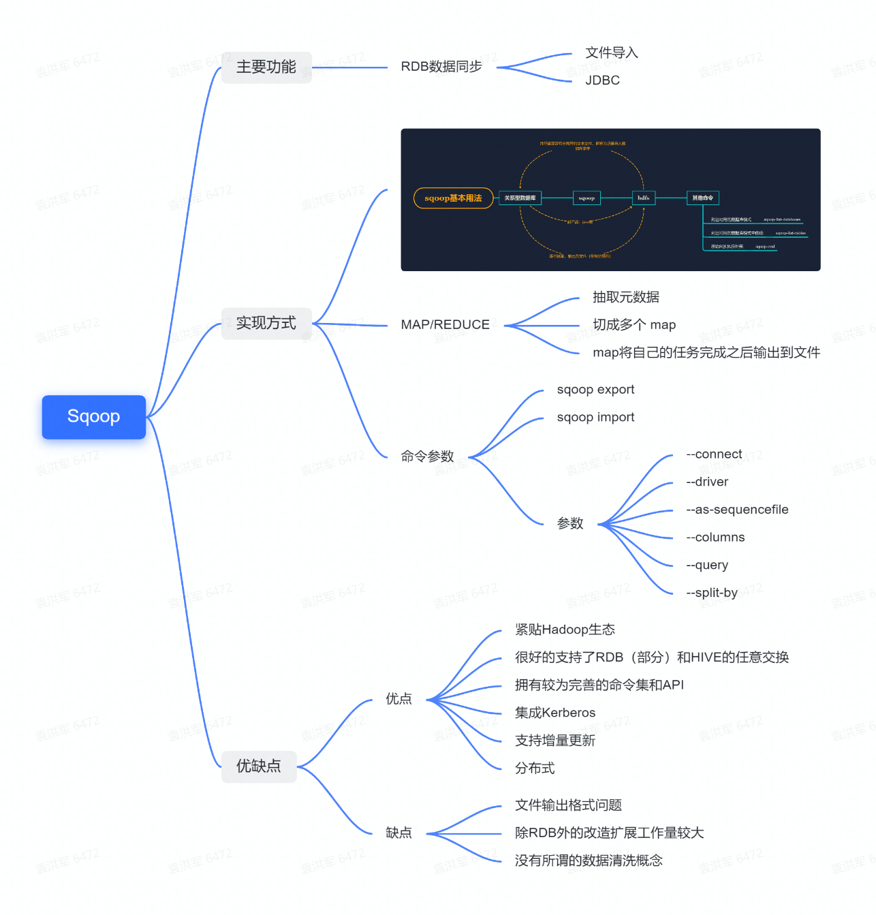
从脑图我们可以看到,Sqoop的主要功能是针对RDB的数据同步,其实现方式是基于MAP/REDUCE。Sqoop拥有丰富的参数和命令行可以去执行各种操作。Sqoop的优点在于它首先贴合Hadoop生态,并已经支持大部分RDB到HIVE任意源的转换,拥有完整的命令集和API的分布式数据同步工具。
但其缺点是Sqoop只支持RDB的数据同步,并且对于数据文件有一定的限制,以及还没有数据清洗的概念。
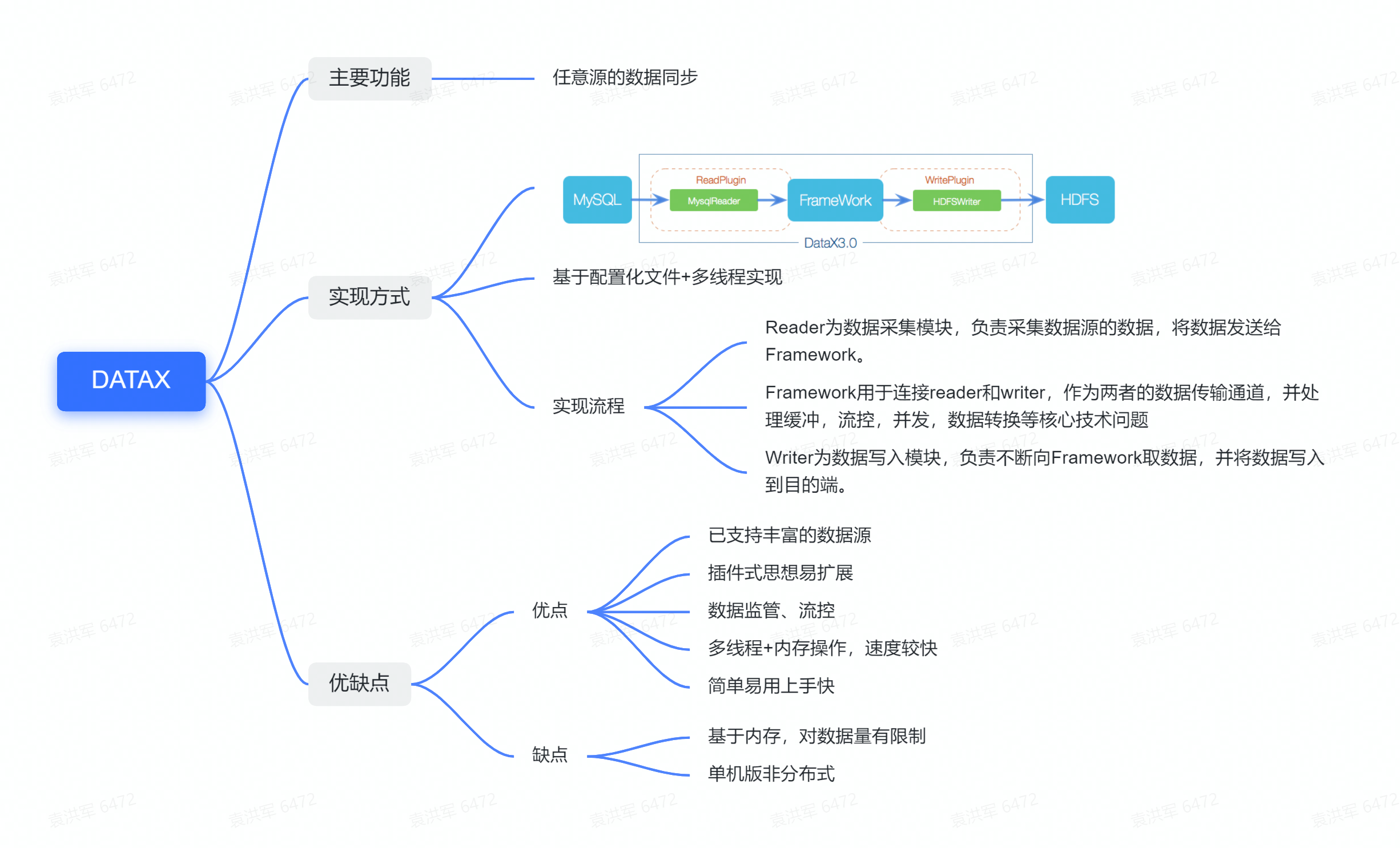
DataX的主要功能是任意源的数据同步,通过配置化文件+多线程的方式实现,主要分为三个流程:Reader、Framework和Writer,其中Framework主要起到通信和留空的作用。
DataX的优点是它采用了插件式的开发,拥有自己的流控和数据管控,在社区活跃度上,DataX的官网上提供了许多不同源的数据推送。但DataX的缺点在于它基于内存,对数据量可能存在限制。
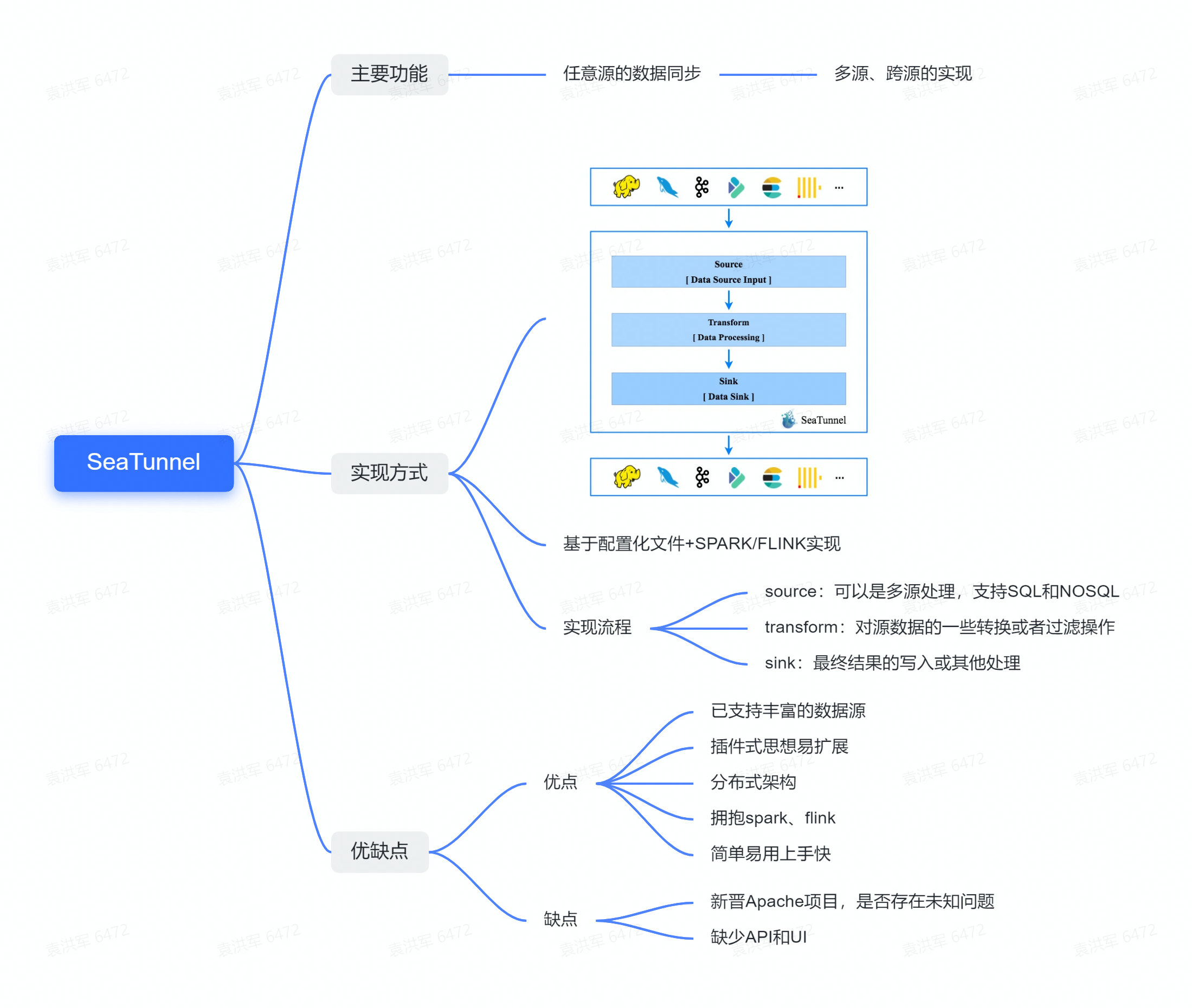
Apache SeaTunnel (Incubating)做的也是任意源的数据同步,实现流程分为source、transform和sink三步,基于配置文件、Spark或Flink实现。其优点是目前官网2.1.0有非常多的插件和源的推送,基于插件式的思想也使其非常容易扩展,拥抱Spark和Flink的同时也做到了分布式的架构。要说Apache SeaTunnel (Incubating)唯一的缺点可能是目前缺少IP的调用,UI界面需要自己做管控。
综上所述,Sqoop虽然是分布式,但是仅支持RDB和HIVE、Hbase之间的数据同步且扩展能力差,不利于二开。DataX扩展性好,整体性稳定,但由于是单机版,无法分布式集群部署,且数据抽取能力和机器性能有强依赖关系。而SeaTunnel和DataX类似并弥补了DataX非分布式的问题,对于实时流也做了很好的支持,虽然是新产品,但社区活跃度高。基于是否支持分布式、是否需要单独机器部署等诸多因素的考量,最后我们选择了SeaTunnel。
03 Apache SeaTunnel (Incubating)的落地实践
在Apache SeaTunnel (Incubating)的官网我们可以看到Apache SeaTunnel (Incubating)的基础流程包括source、transform和sink三部分。根据官网的指南,Apache SeaTunnel (Incubating)的启动需要配置脚本,但经过我们的研究发现,Apache SeaTunnel (Incubating)的最终执行是依赖config文件的spark-submit提交的一个Application应用。
这种初始化方式虽然简单,但存在必须依赖Config文件的问题,每次运行任务后都会生成再进行清除,虽然可以在调度脚本中动态生成,但也产生了两个问题。1、频繁的磁盘操作是否有意义;2、是否存在更为高效的方式支持Apache SeaTunnel (Incubating)的运行。
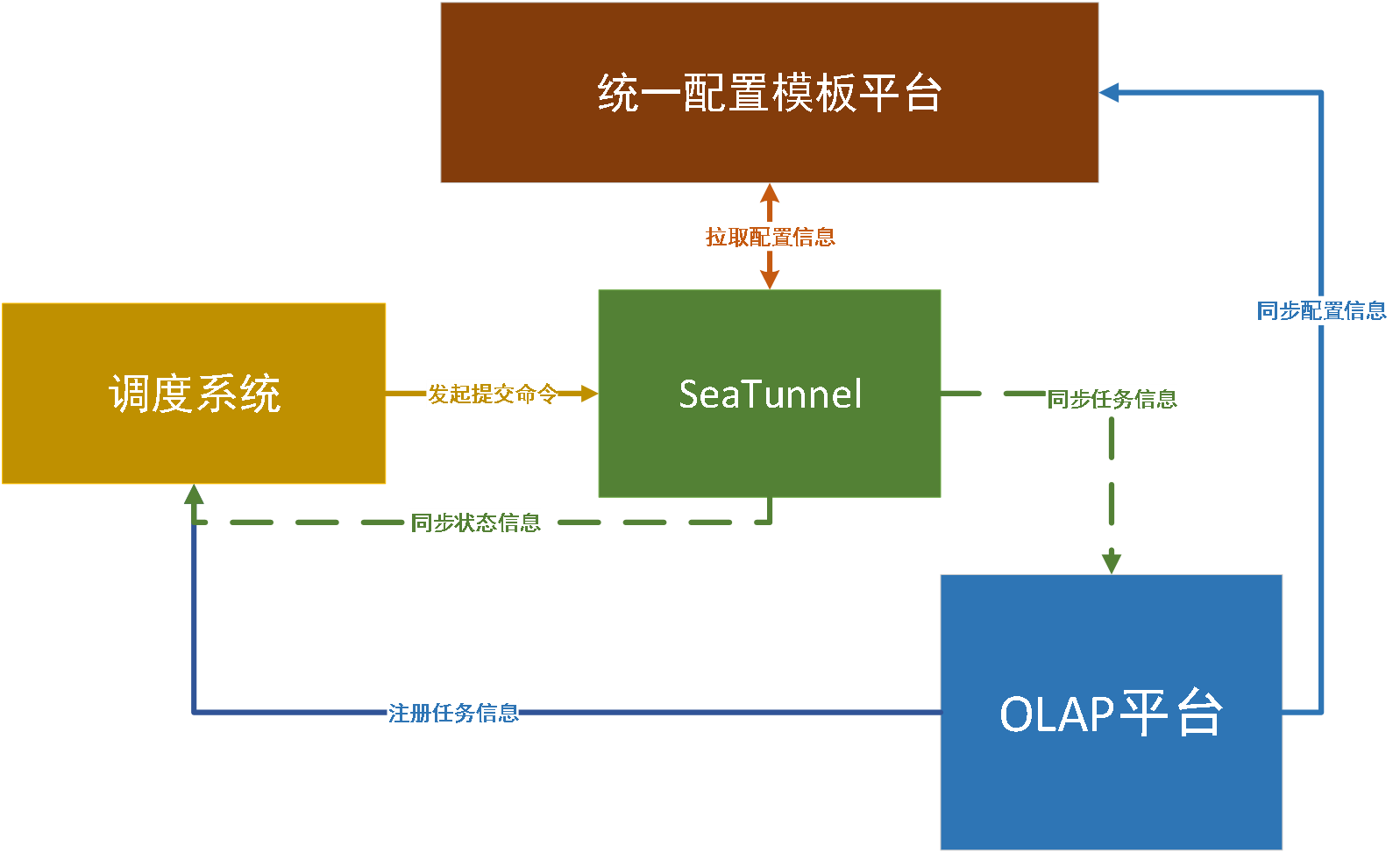
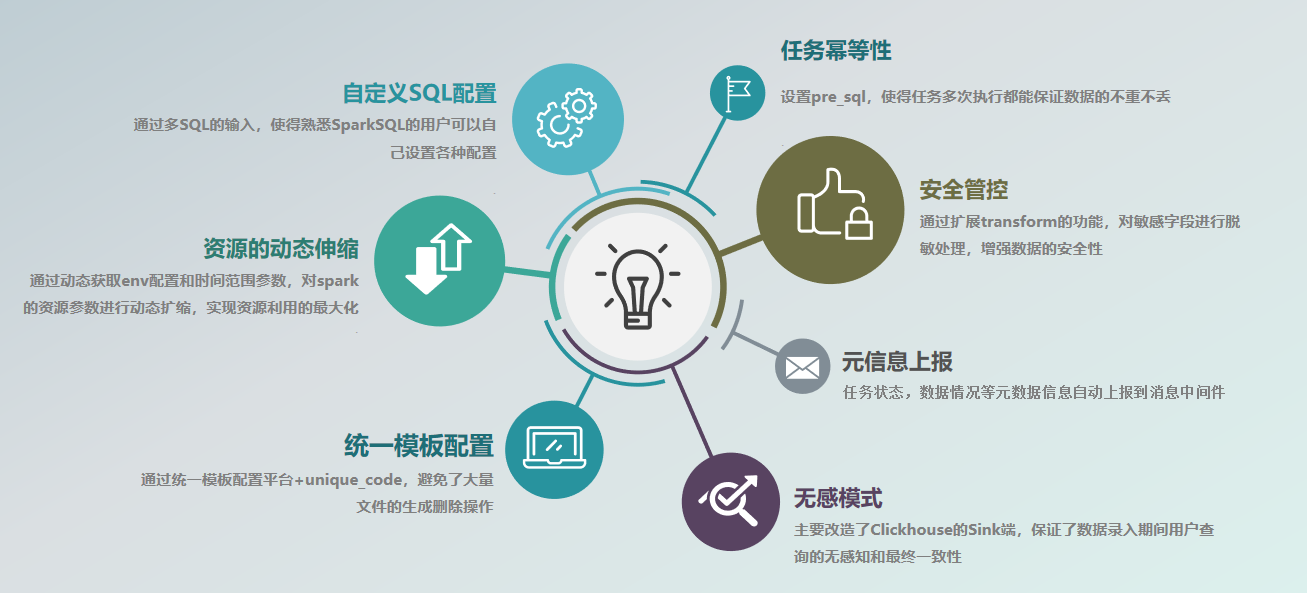
基于以上考量,在最终的设计方案中,我们增加了一个统一配置模板平台模块。调度时只需要发起一个提交命令,由Apache SeaTunnel (Incubating)自身去统一配置模板平台中拉取配置信息,再去装载和初始化参数。
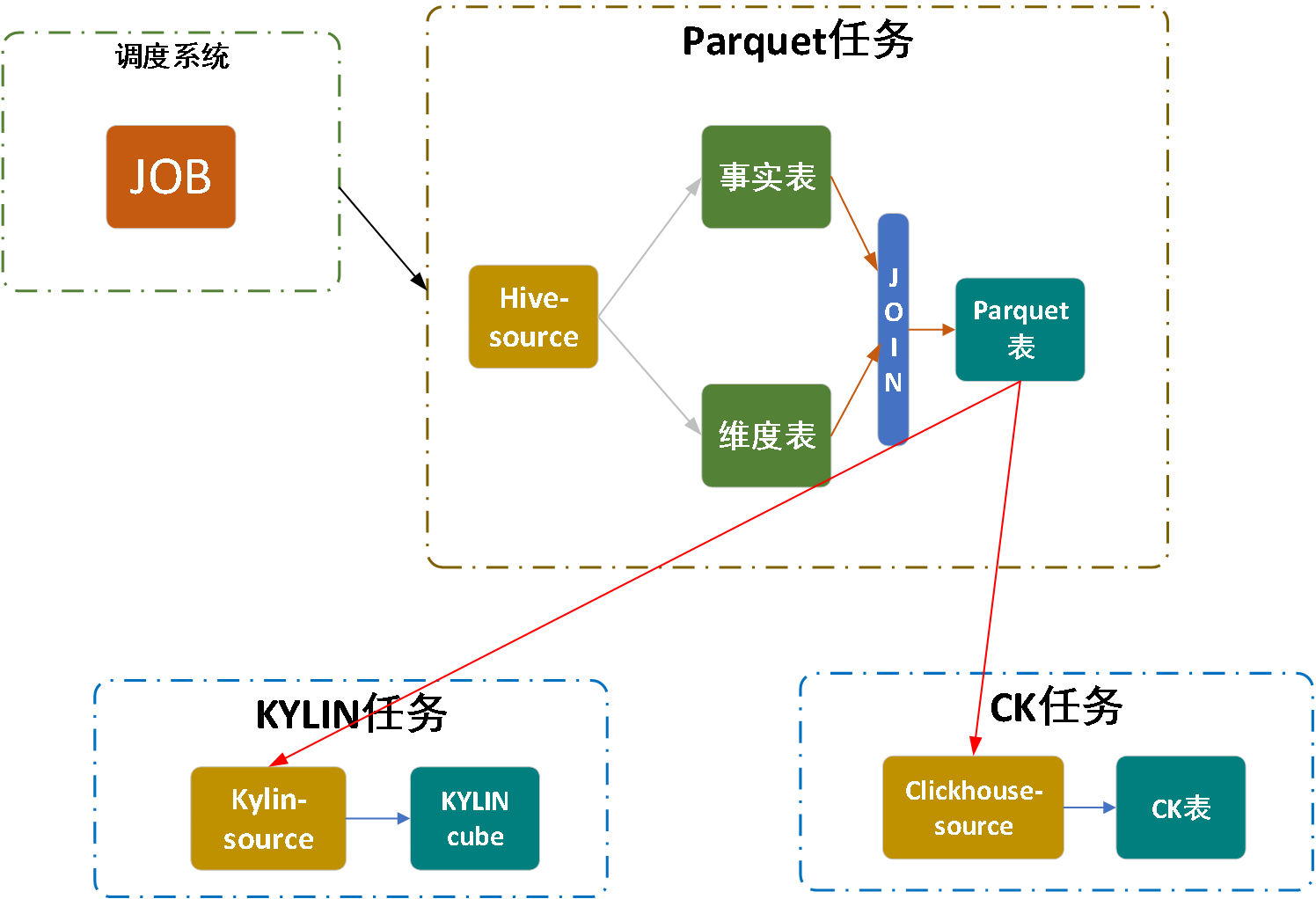
上图展示的便是孩子王OLAP的业务流程,主要分为三块。数据从Parquet,即Hive,通过Parquet表的方式到KYLIN和CK source的整体流程。
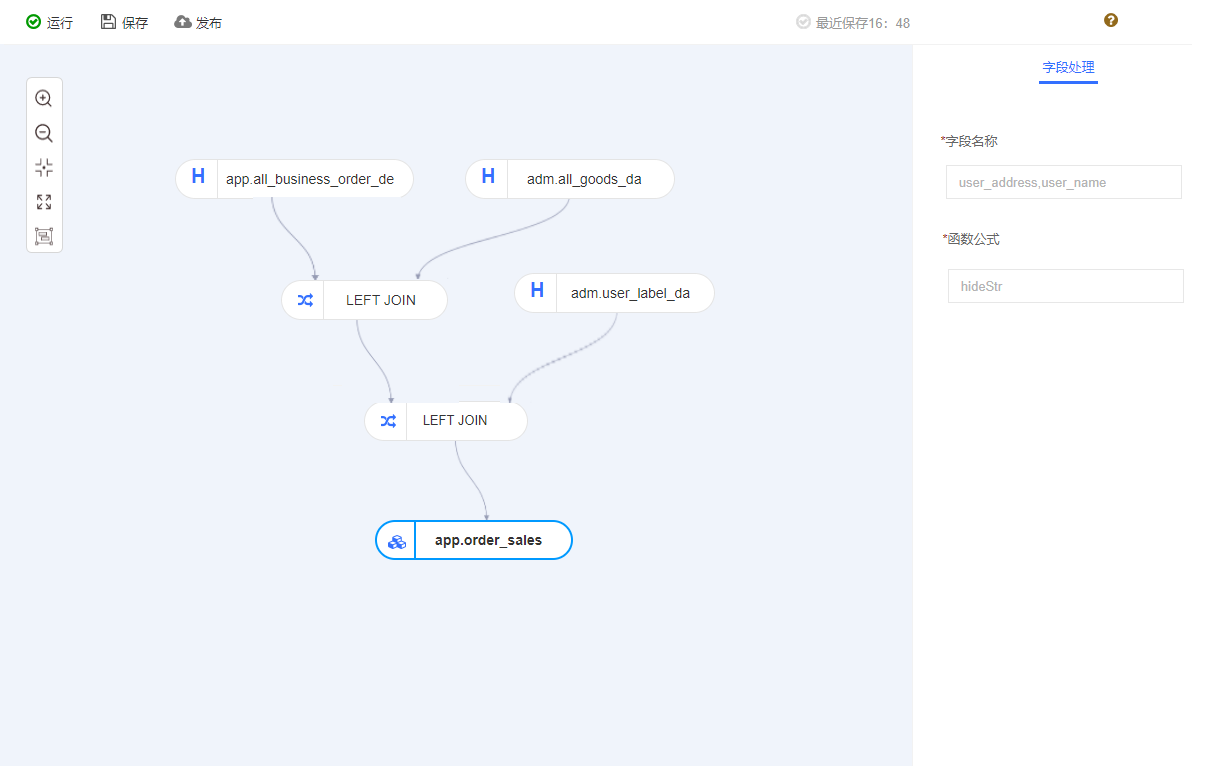
这是我们建模的页面,主要通过拖拉拽的方式生成最终模型,每个表之间通过一些交易操作,右侧是针对Apache SeaTunnel (Incubating)的微处理。
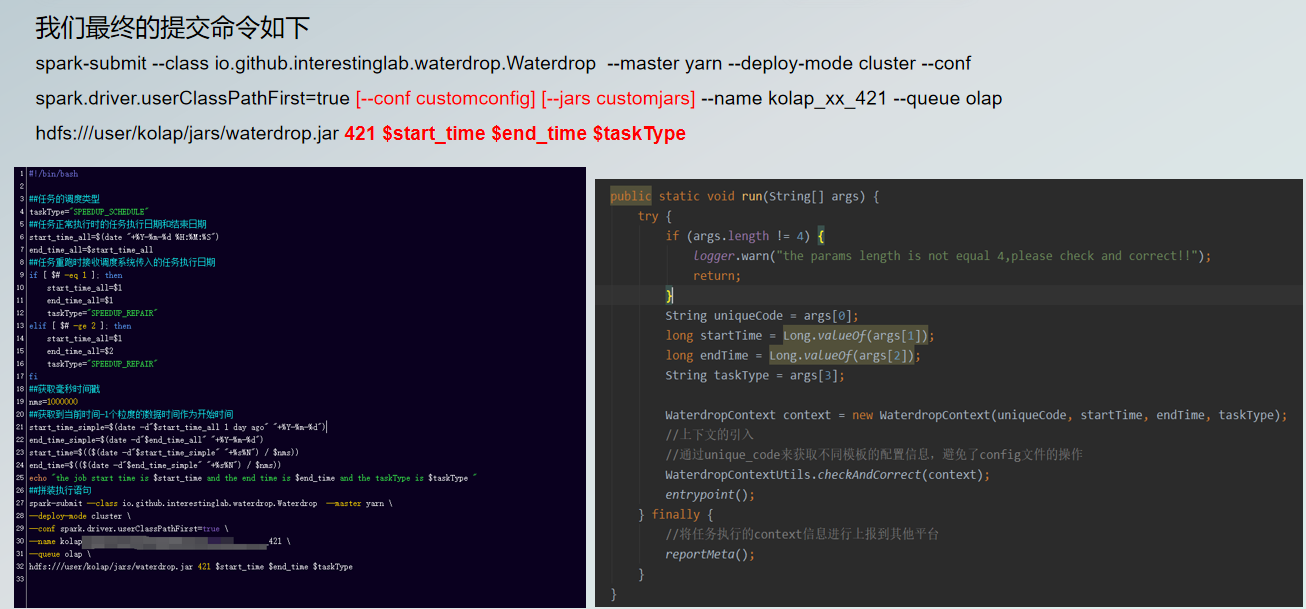
因此我们最终提交的命令如上,其中标红的首先是【-conf customconfig/jars】,指用户可以再统一配置模板平台进行处理,或者建模时单独指定。最后标红的【421 $start_time $end_time $taskType】Unicode,属于唯一编码。
下方图左就是我们最终调度脚本提交的38个命令,下方图右是针对Apache SeaTunnel (Incubating)做的改造,可以看到一个较为特殊的名为WaterdropContext的工具类。可以首先判断Unicode是否存在,再通过Unicode_code来获取不同模板的配置信息,避免了config文件的操作。
在最后的reportMeta则是用于在任务执行完成后上报一些信息,这也会在Apache SeaTunnel (Incubating)中完成。
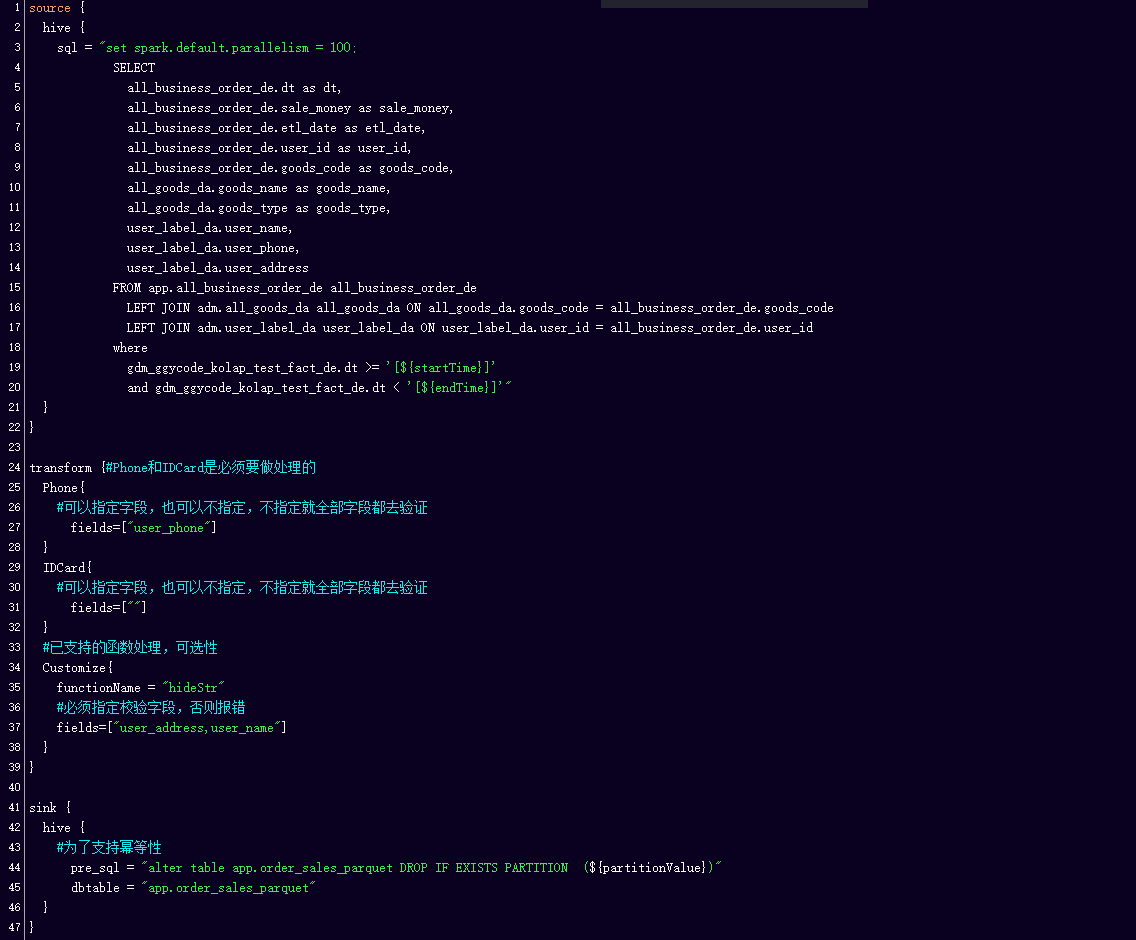

在最终完成的config文件如上,值得注意的是在transform方面,孩子王做了一些改造。首先是针对手机或者身份证号等做脱敏处理,如果用户指定字段,就按照字段做,如果不指定字段就扫描所有字段,然后根据模式匹配,进行脱敏加密。
第二transform还支持自定义处理,如上文说道OLAP建模的时候说到。加入了HideStr,可以保留一串字符的前十个字段,加密后方的所有字符,在数据安全上有所保障。
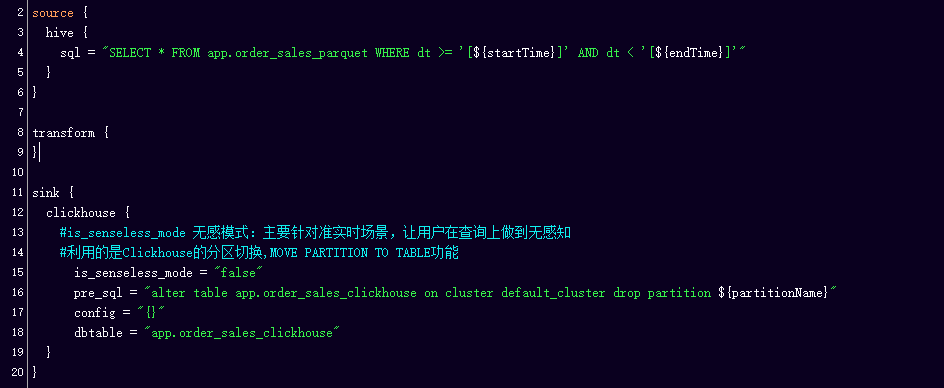
然后,在sink端,我们为了支持任务的幂等性,我们加入了pre_sql,这主要完成的任务是数据的删除,或分区的删除,因为任务在生产过程中不可能只运行一次,一旦出现重跑或补数等操作,就需要这一部分为数据的不同和正确性做考量。
在图右方的一个Clickhouse的Sink端,这里我们加入了一个is_senseless_mode,它组成了一个读写分离的无感模式,用户在查询和补数的时候不感知整体区域,而是用到CK的分区转换,即名为MOVE PARTITION TO TABLE的命令进行操作的。
此处特别说明KYLIN的Sink端,KYLIN是一个非常特殊的源,拥有自己一整套数据录入的逻辑,而且,他有自己的监控页面,因此我们给予KYLIN的改造只是简单地调用其API操作,在使用KYLIN时也只是简单的API调用和不断轮询的状态,所以KYLIN这块的资源在统一模板配置平台就被限制地很小。
04 Apache SeaTunnel (Incubating)改造中的常见问题
1、OOM&Too many Parts
问题通常会出现在Hive到Hive的过程中,即使我们通过了自动资源的分配,但也存在数据突然间变大的情况,比如在举办了多次活动之后。这样的问题其实只能通过手动动态地调参,调整数据同步批量时间来避免。未来我们可能尽力去完成对于数据量的掌握,做到精细的控制。
2、字段、类型不一致问题
模型上线后,任务依赖的上游表或者字段,用户都会做一些修改,这些修改若无法感知,可能导致任务的失败。目前解决方法是依托血缘+快照的方式进行提前感知来避免错误。
3、自定义数据源&自定义分隔符
如财务部门需要单独使用的分割符,或是jar信息,现在用户可以自己在统一配置模板平台指定加载额外jar信息以及分割符信息。
4、数据倾斜问题
这可能因为用户自己设置了并行度,但无法做到尽善尽美。这一块我们暂时还没有完成处理,后续的思路可能在Source模块中添加post处理,对数据进行打散,完成倾斜。
5、KYLIN全局字典锁问题
随着业务发展,一个cube无法满足用户使用,就能需要建立多个cube,如果多个cube之间用了相同的字段,就会遇到KYLIN全局字典锁的问题。目前解决的思路是把两个或多个任务之间的调度时间进行隔开,如果无法隔开,可以做一个分布式锁的控制。KYLIN的sink端必须要拿到锁才能运行。
05 对孩子王未来发展方向的预测展望
多源数据同步,未来可能针对RDB源进行处理
基于实时Flink的实现
接管已有采集调度平台(主要解决分库分表的问题)
数据质量校验,像一些空值、整个数据的空置率、主时间的判断等
我的分享就到这里,希望以后可以和社区多多交流,共同进步,谢谢!