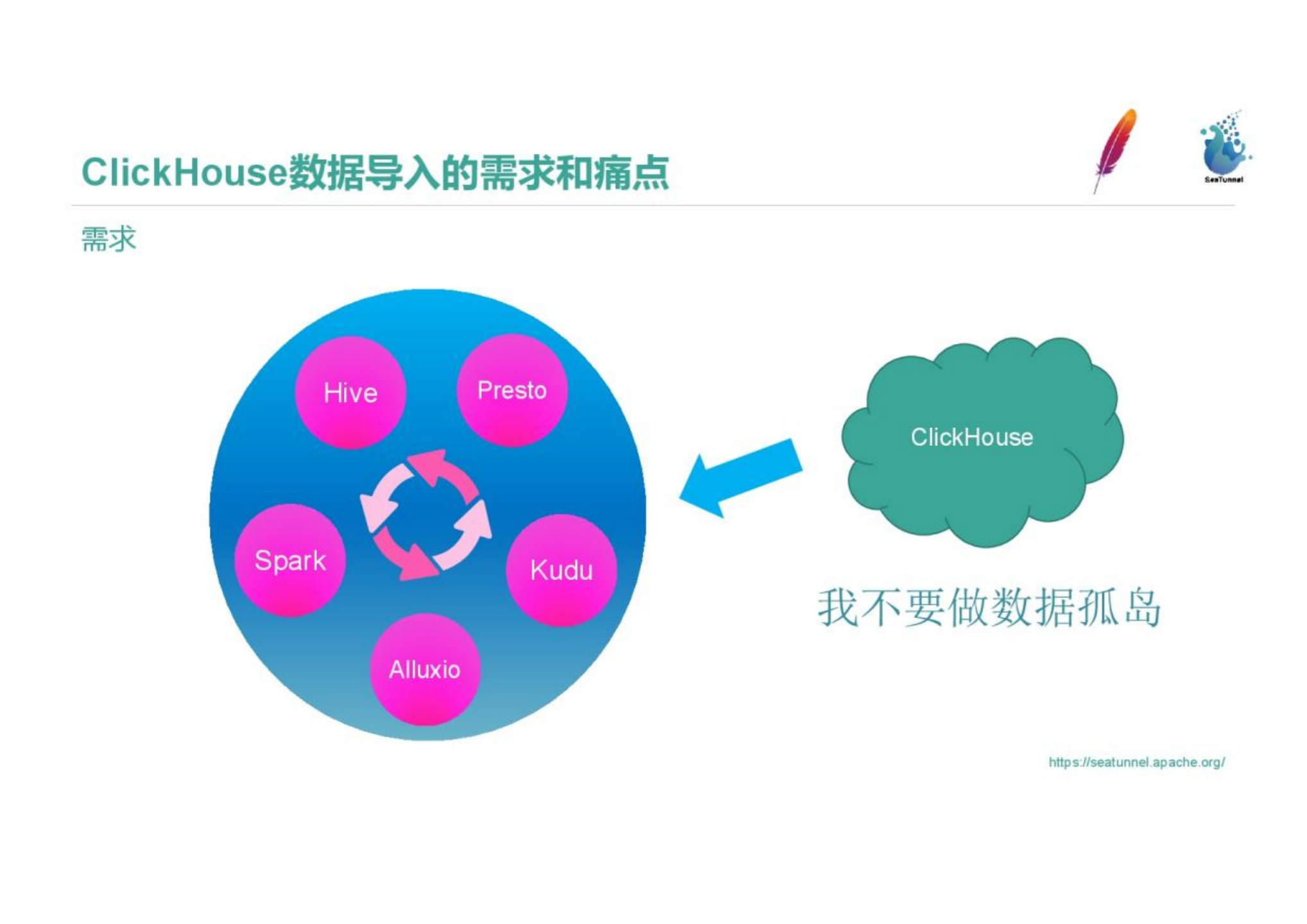
问一位数据工程师他的管道是 ETL 还是 ELT,几乎总能得到秒答——老派工程师说 ETL,dbt 用户说 ELT。
但这两个答案都不完整。有第三种模式更准确地描述了现代数据管道实际在做的事——它一直存在,只是没有被命名:EtLT。
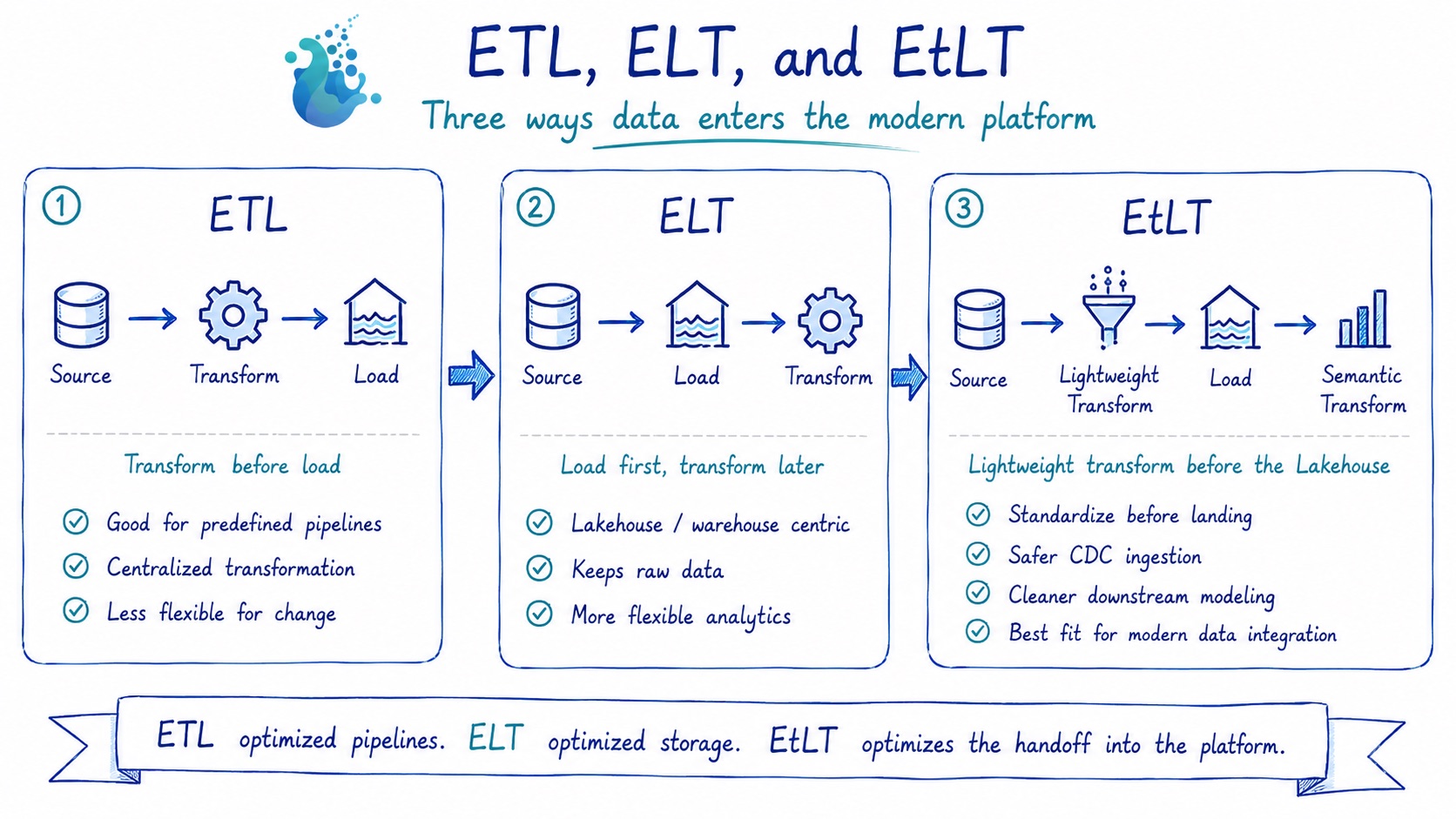
三种范式
ETL:落库前先转换
原始数据从源端提取后,经过专用转换层(Spark、DataStage、Informatica)处理,再写入目标数仓。
源端 ──► [转换层] ──► 目标端
优点: 目标端始终存放干净、业务就绪的数据。合规管控在数据落库前就已强制执行。
缺点: 转换层容易成为瓶颈。Schema 变更需要跨多层同步修改。专用计算集群的运维成本高。
ELT:先落库,原地转换
由 dbt 带火的模式。原始数据直接落入数仓(BigQuery、Snowflake、ClickHouse),再用 SQL 原地做转换。转换层不再是独立集群——就是数仓本身。
源端 ──► 目标端(原始层)──► [数仓内 SQL] ──► 业务层
优点: 原始数据保留完整审计价值。复用数仓算力。迭代速度快。
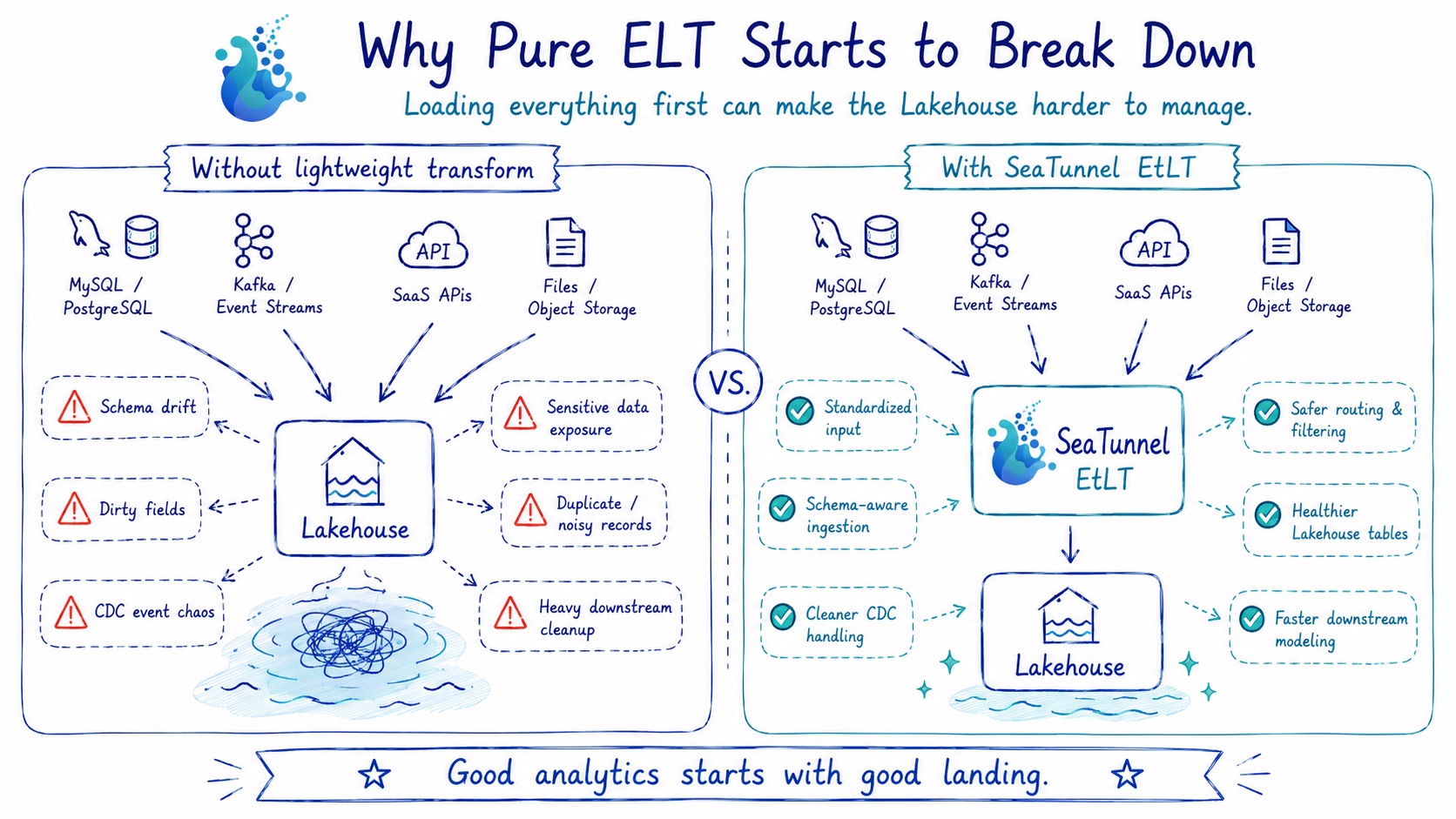
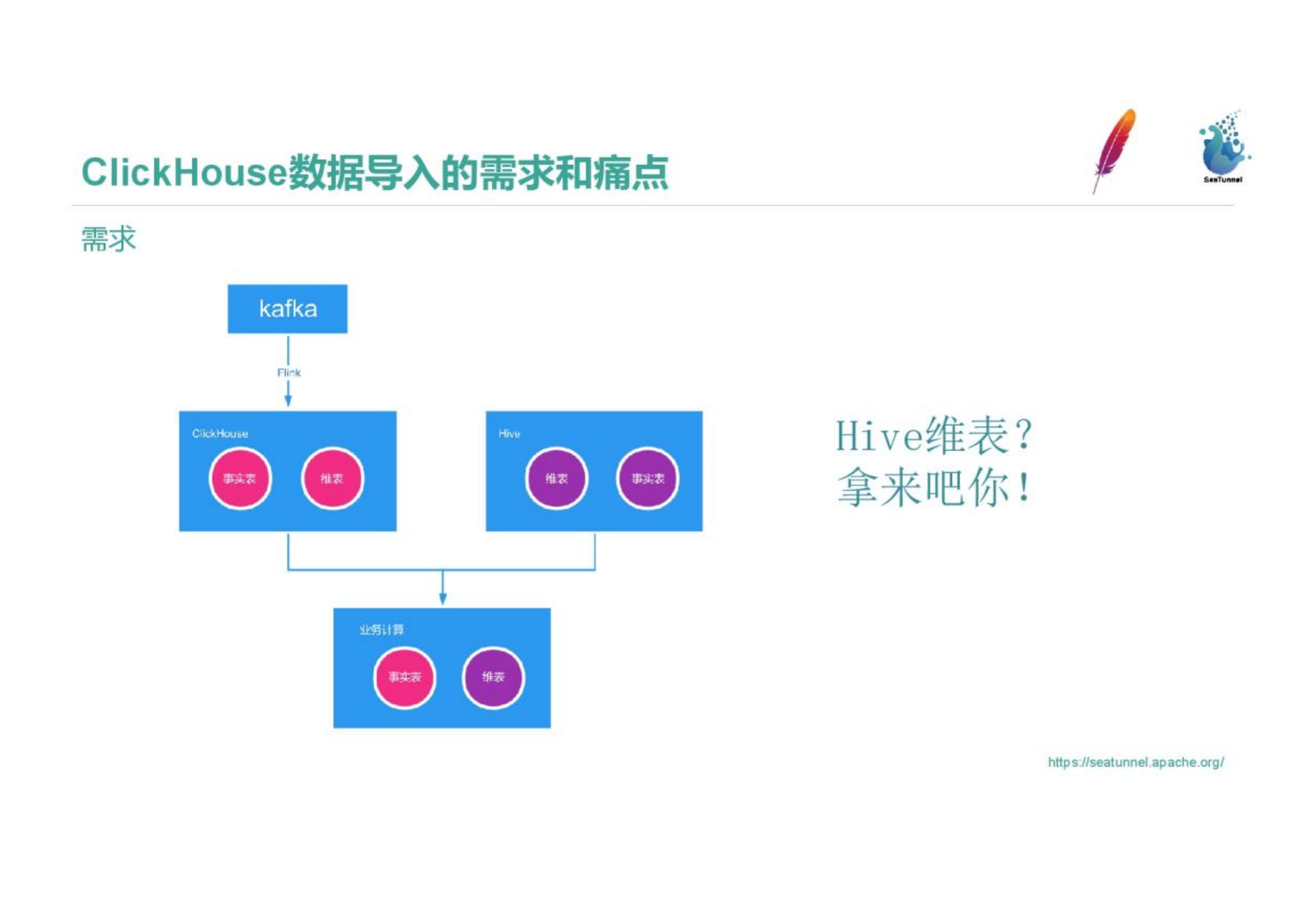
缺点: 手机号、身份证、邮箱等敏感字段以明文落库,存在合规风险。数据质量问题要等 Load 之后才可见,此时下游模型可能已经被污染。
EtLT:传输途中做轻量变换
源端 ──► [tiny t] ──► 目标端(净化原始层)──► [目标端内的 T]
tiny t 是数据在传输过程中完成的一组行级变换:
| tiny t 操作 | 目的 |
|---|---|
| 字段投影 / 列裁剪 | 传输前删除无用列——节省带宽 |
| PII 脱敏 | 手机号、身份证、邮箱在落库前匿名化——合规在管道层强制落地,而非事后补救 |
| 类型归一 | 源端 VARCHAR "2023-01-01" 在入仓时就转为 DATE——省去数仓侧的类型转换 SQL |
| 行过滤 | 不需要的事件可在 Load 前丢弃;有状态的 CDC 变化需要按 changelog 语义处理 |
| 字段重命名 | 适配目标端命名规范,无需数仓侧的别名层 |
| NULL 回填 | 减少下游聚合 SQL 中的 COALESCE 调用 |
大 T(Load 后的 Transform)才是真正的业务逻辑所在:多表 JOIN、指标计算、聚合、ML 特征工程。
为什么工程师长期忽略 EtLT
根本原因是工具,不是概念本身。
传统 ETL 工具(Informatica、DataStage)把转换做得极重,工程师被迫把大量业务逻辑塞进管道,结果管道变得脆弱、难以维护。
现代 ELT 工具(Airbyte、Fivetran)走向另一个极端:源端到目标端几乎没有在途处理,全部交给 dbt。
两类工具都没能填好的空白: 当你同时需要在途操作(脱敏、过滤)和目标端的复杂分析 SQL 时,两个工具族都会让你陷入尴尬的临时方案。
EtLT 天然填补这个空白。
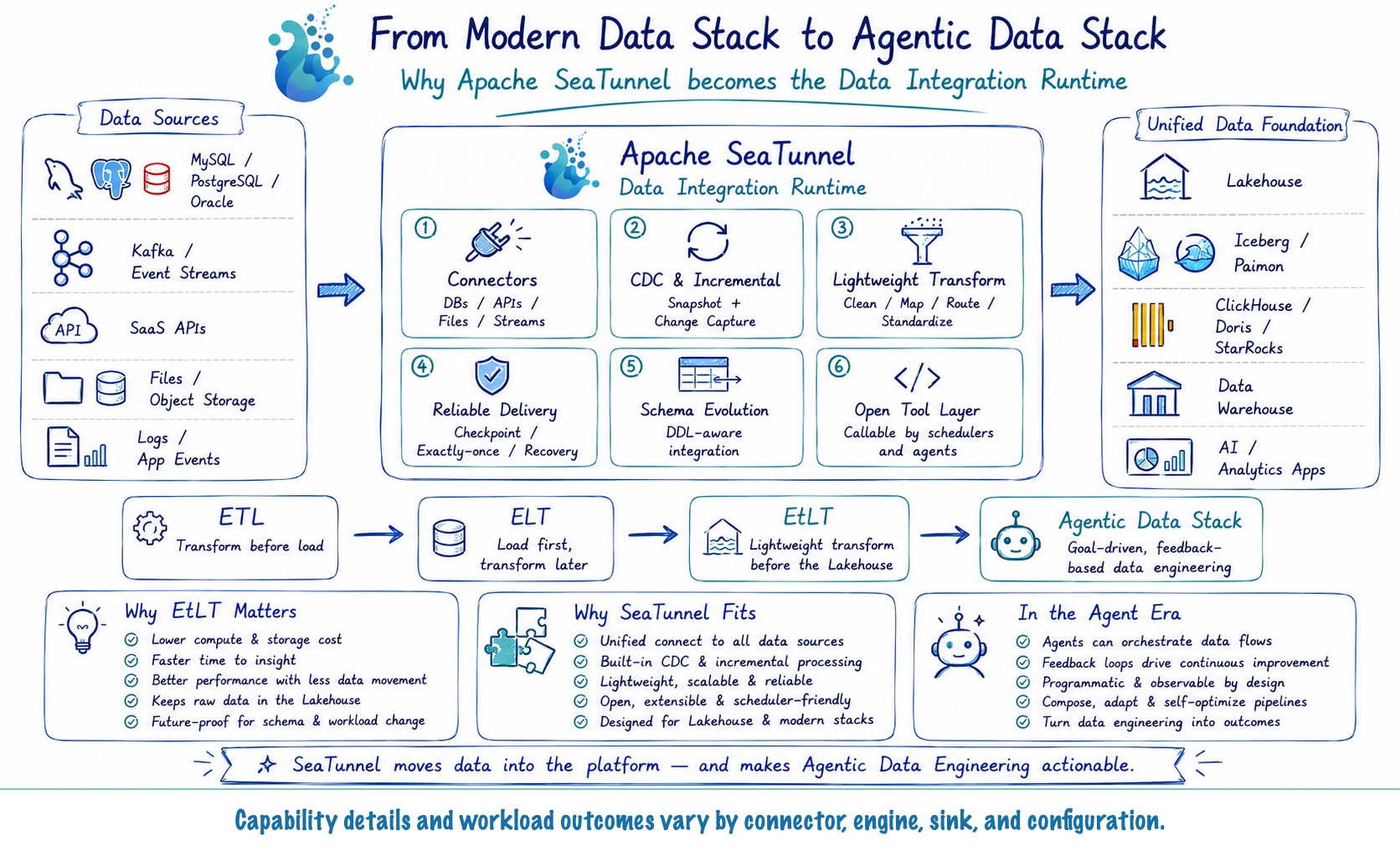
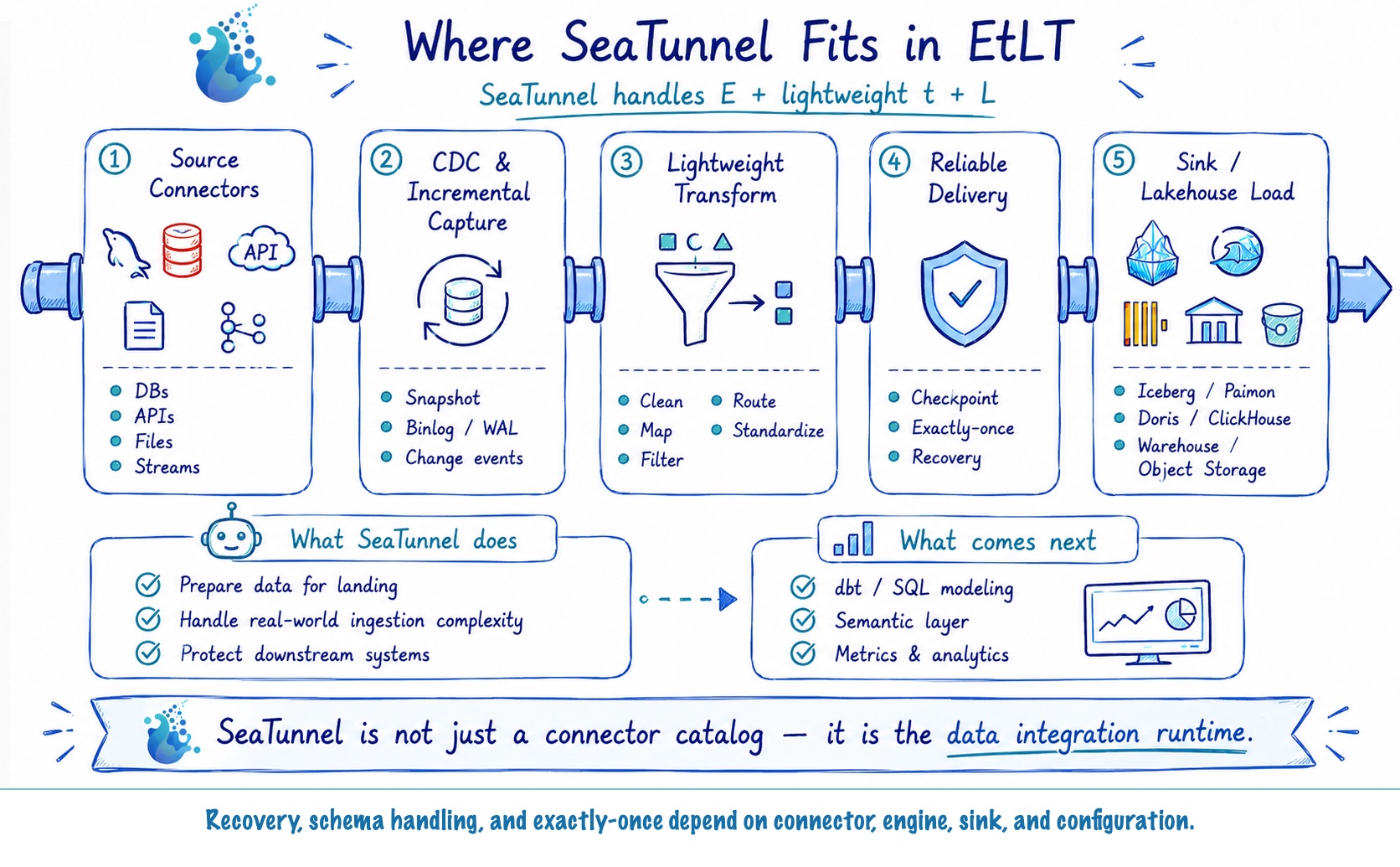
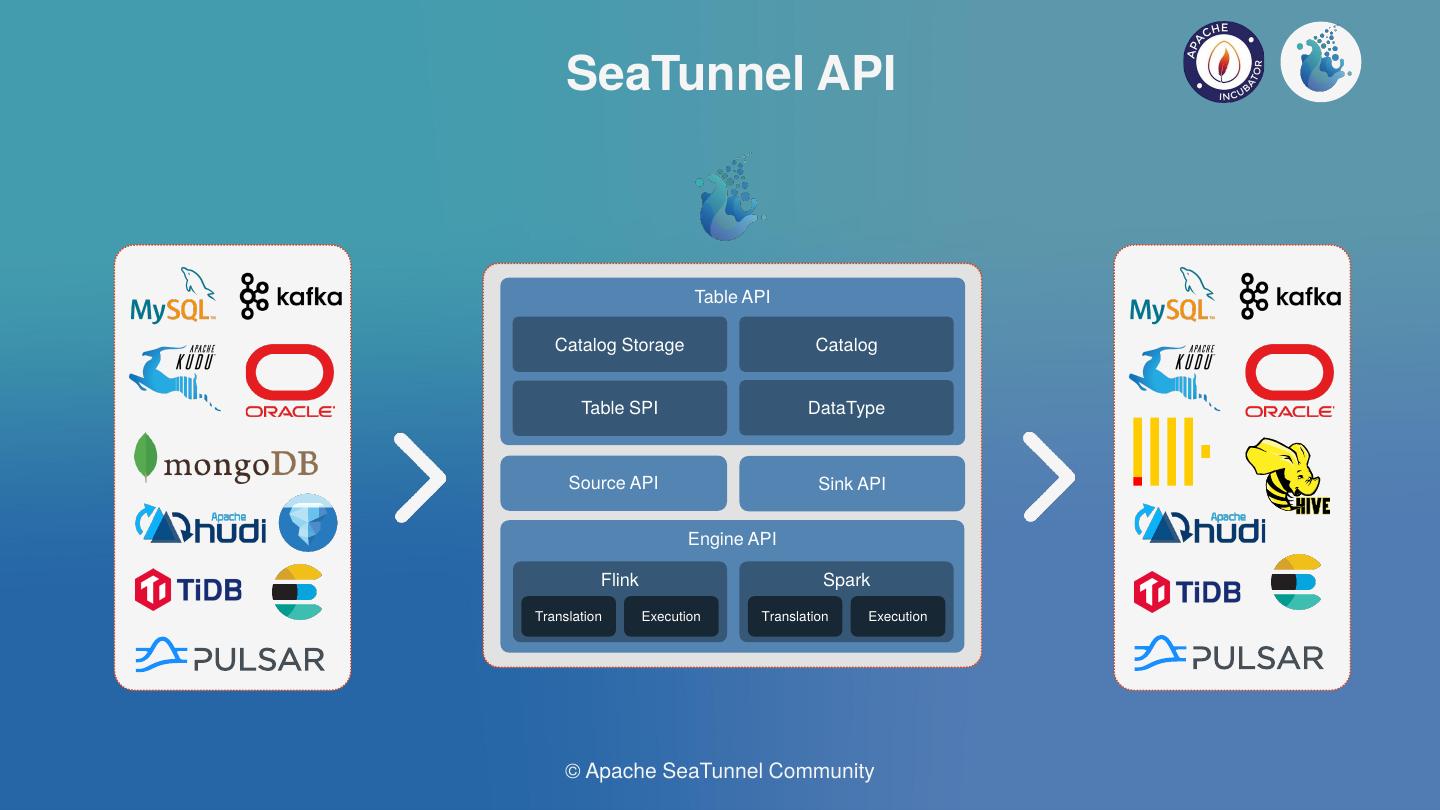
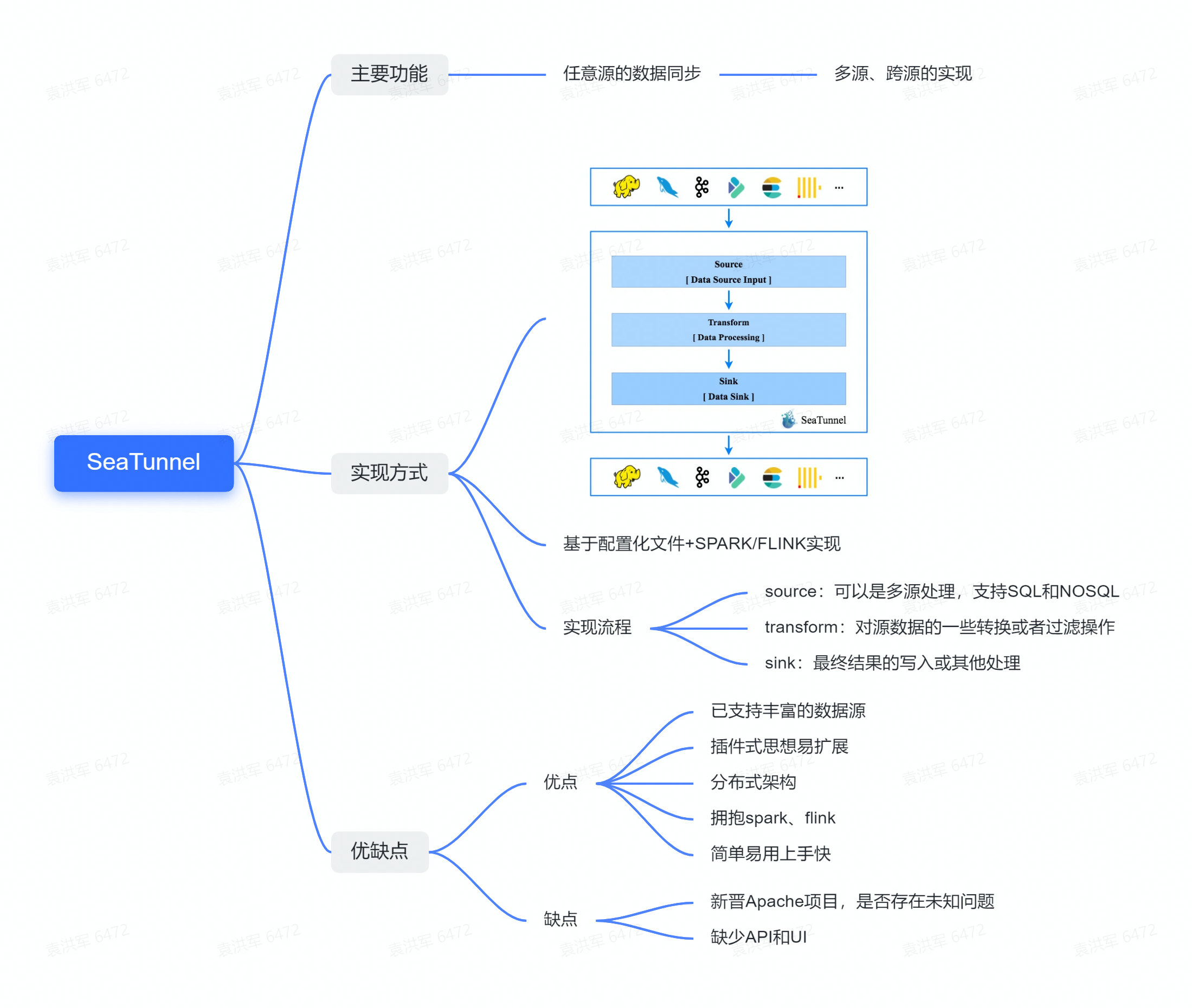
SeaTunnel 天然契合 EtLT
Apache SeaTunnel 在官方文档中把自己定位为 "EL(T) 数据集成工具"——括号里的 T 是刻意为之。Transform 步骤是轻量的、可选的。这不是营销话术,而是一个架构约束。
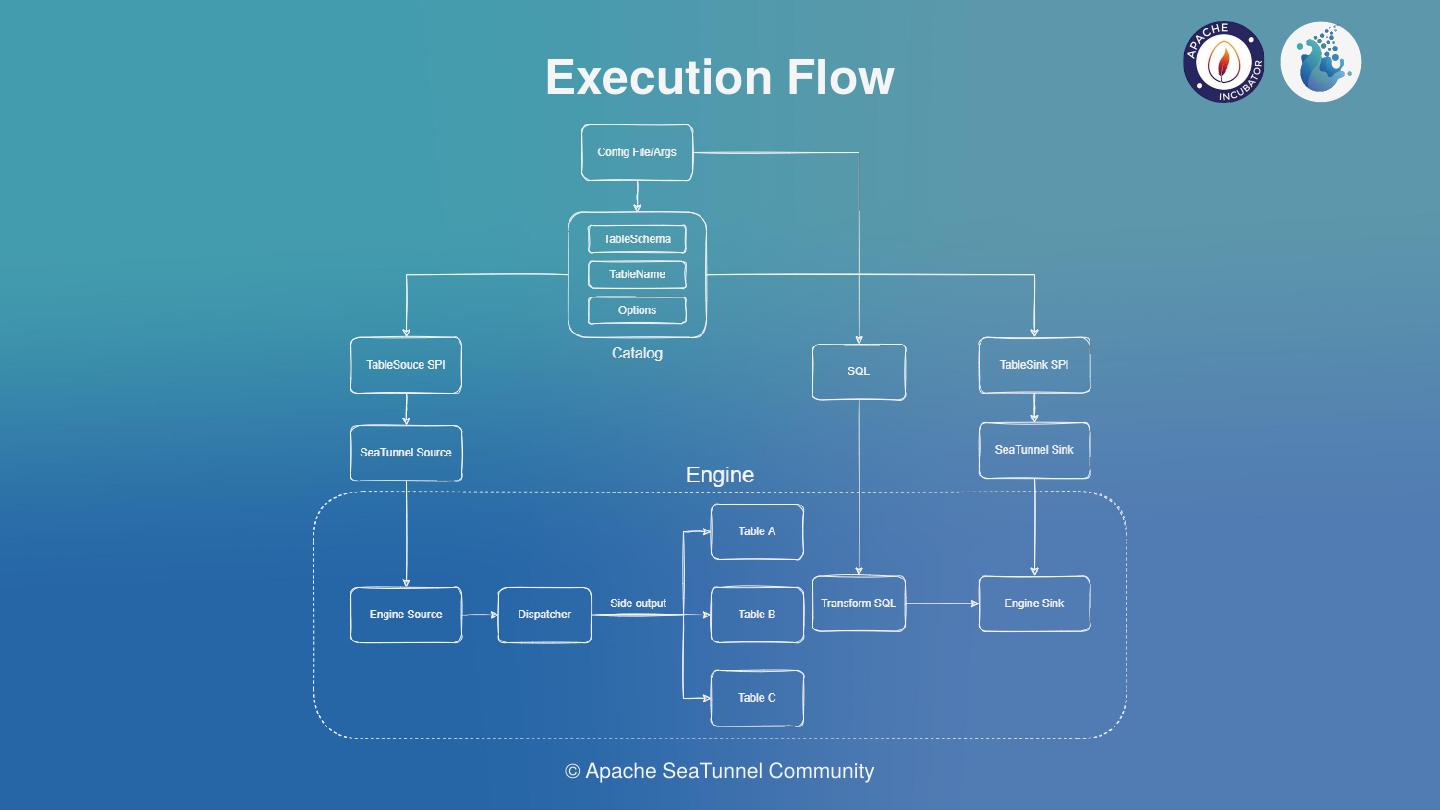
三层模型与 EtLT 直接对应
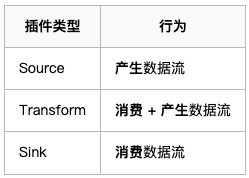
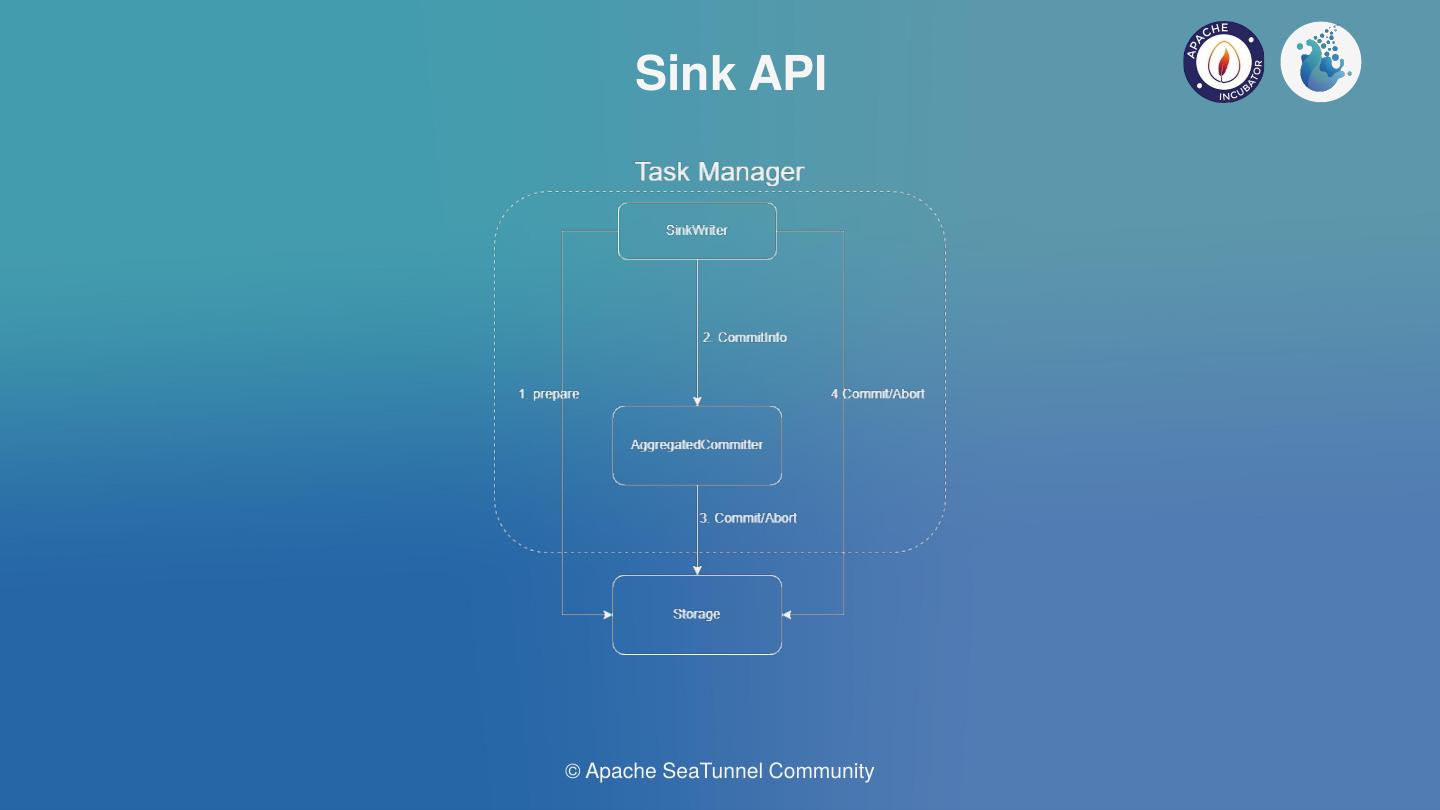
SeaTunnel 的执行模型分三层:Source → Transform → Sink。
Source(E)
└──► Transform(tiny t) ← 可选,轻量处理
└──► Sink(L)
└──► [数仓 SQL / dbt](T) ← 大 T 在这里
SeaTunnel 对 Transform 能做的事划定了清晰边界。官方文档写道:
"Transform can only be used for some simple transformations of data, such as converting a column to uppercase/lowercase, modifying column names, or splitting one column into multiple columns."
这描述的是内置 Transform 的目标边界。当前 Zeta SQL Transform 不支持 JOIN 和 GROUP BY,因此跨表 JOIN 与聚合应放在目标系统或其他专用处理层中完成。
内置 Transform 覆盖典型 tiny t 需求
| SeaTunnel Transform | 对应的 tiny t 操作 |
|---|---|
FieldMapper | 字段重命名、列投影 |
Filter | 通过 include/exclude 列表做字段投影 |
Replace | 字段值替换(脱敏 / 打码) |
Split | 将一列拆成多列(如地址解析) |
SQL Transform | 行过滤和轻量 SQL 表达式;当前 Zeta 实现不支持 JOIN 或 GROUP BY |
Copy | 字段复制 |
SeaTunnel 同时提供 map 和 flat-map Transform 接口。当前内置 Transform 主要处理单条记录和 Schema,而不是跨行聚合,因此很适合作为 tiny t 层。
EtLT 最关键的战场:CDC 管道
实时 CDC 同步是 SeaTunnel 的核心使用场景之一——也是纯 ELT 在合规上失守的地方。
根本问题在于:binlog 事件里的字段值一旦落库,就没有第二次机会打码了。 写入 ClickHouse 的手机号或身份证,不可能被下游 dbt 模型"反写"回来。原始明文已经持久化。
EtLT 解决了 ELT 无法解决的问题:在数据到达目标端之前的唯一时间窗口内,完成合规变换。
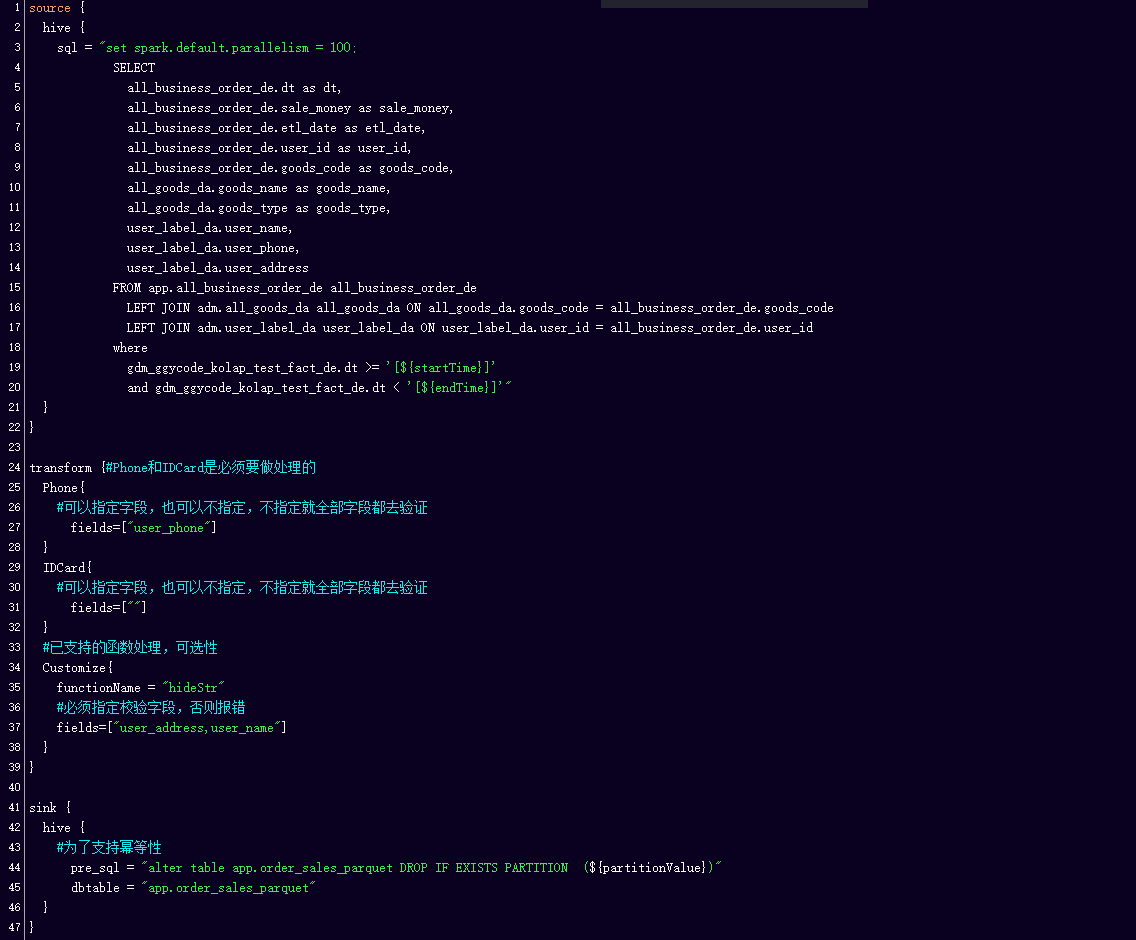
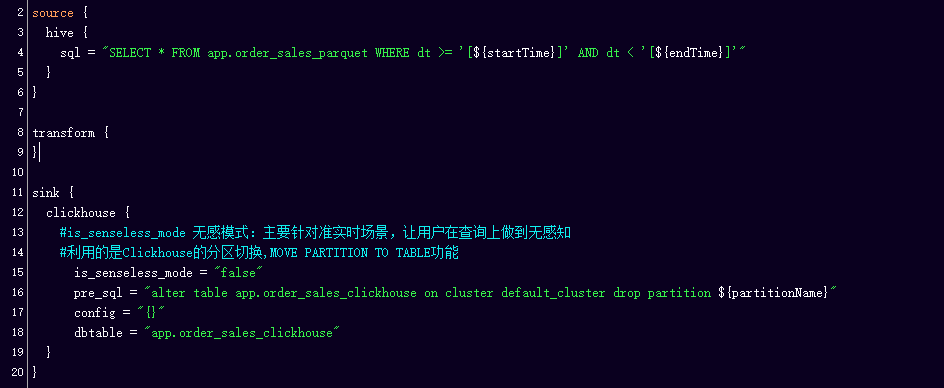
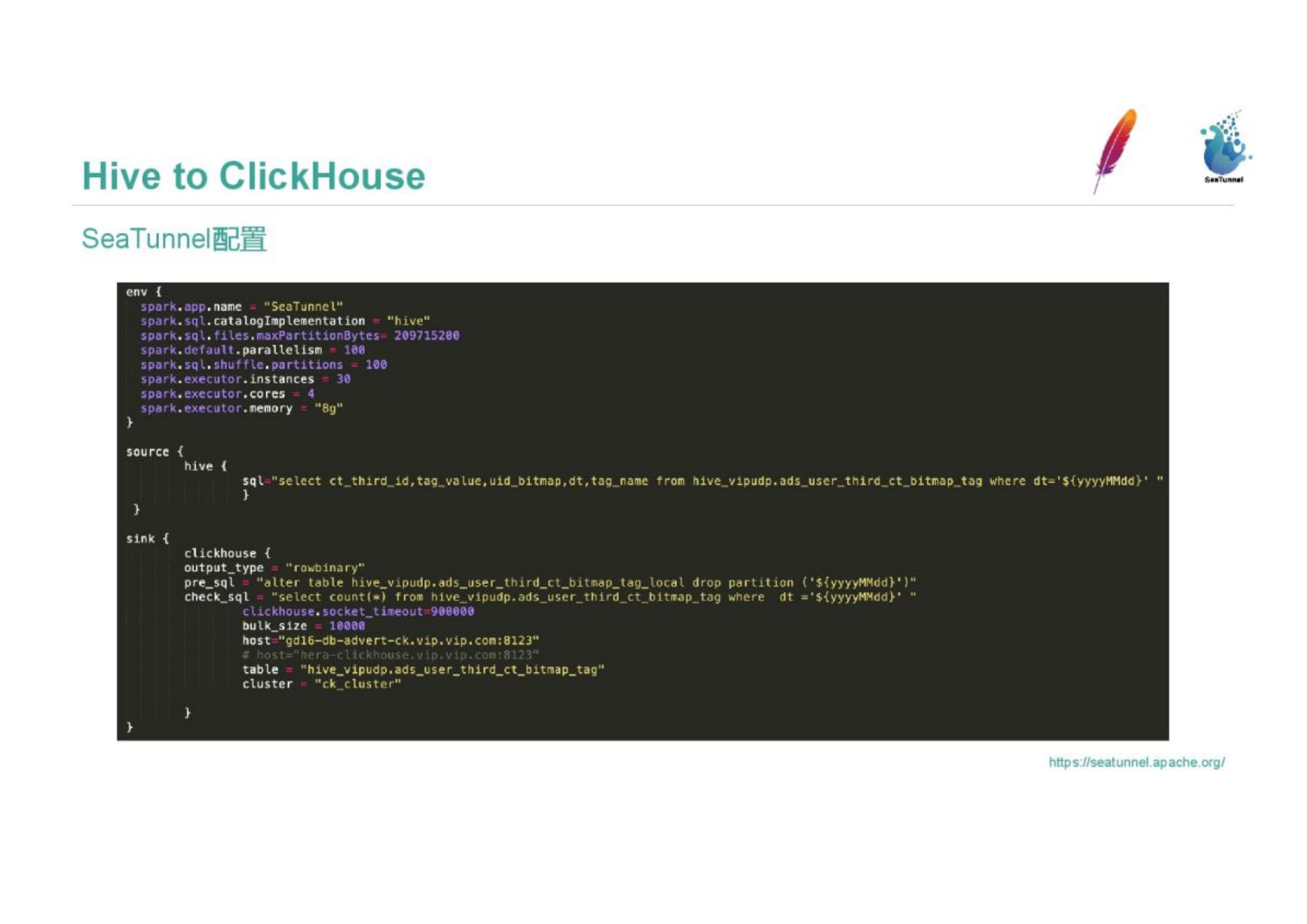
下面给出一个带 tiny t 的 SeaTunnel CDC 作业最小配置形态。运行前请替换示例中的账号、密码和服务地址:
env {
job.mode = "STREAMING"
}
source {
MySQL-CDC {
plugin_output = "raw_user_info"
url = "jdbc:mysql://localhost:3306/orders"
username = "seatunnel"
password = "change-me"
server-id = 5601-5604
table-names = ["orders.user_info"]
}
}
transform {
# 在传输途中打码手机号——原始值永远不会到达数仓
Replace {
plugin_input = "raw_user_info"
plugin_output = "masked_user_info"
replace_field = "phone"
pattern = "(\\d{3})\\d{4}(\\d{4})"
replacement = "$1****$2"
is_regex = true
}
}
sink {
# L:落入 ClickHouse 原始层
Clickhouse {
plugin_input = "masked_user_info"
host = "clickhouse-host:8123"
database = "raw"
table = "user_info"
username = "default"
password = "change-me"
primary_key = "id"
support_upsert = true
allow_experimental_lightweight_delete = true
}
}
数据进入 ClickHouse 后,再用 SQL 构建宽表、计算留存指标、做分析查询——这就是大 T。dbt 模型在这里是天然的搭档。
SeaTunnel + dbt:全栈 EtLT
dbt 负责 Load 之后的大 T;SeaTunnel 负责从源到 Load(含 tiny t)。两者互补,而非竞争。
源端
└── SeaTunnel(E + tiny t + L)
└── dbt(T)
└── BI / ML
SeaTunnel 负责数据到达和在途卫生;dbt 负责数据建模和业务逻辑。每个工具只做它擅长的事。
常见陷阱:把大 T 塞进 SeaTunnel
因为 SeaTunnel 支持 SQL Transform,有些工程师会尝试在里面写 GROUP BY 聚合。当前 Zeta SQL Transform 会明确拒绝 GROUP BY 和 JOIN 查询。
如果确实需要 Load 前的聚合,有两条路:
- 在目标系统里做——这本来就是 EtLT 和 ELT 中大 T 的用途。
- 在 SeaTunnel Transform 链路之外使用专用处理作业——此时构建的是完整流式 ETL 管道,而不是把转换留在 tiny t 层。
边界清晰,失败才容易定位。把 tiny t 和大 T 混在同一层,出问题时几乎无法推断根源在哪里。
总结
| 范式 | 最适合的场景 | SeaTunnel 的角色 |
|---|---|---|
| ETL | 强合规要求、有专用转换计算集群 | 负责 E、L 和已支持的轻量转换;复杂 T 需要专用处理层 |
| ELT | 目标端是强 SQL 引擎(BigQuery/Snowflake),无严格在途合规要求 | 纯 E + L——关闭 Transform |
| EtLT | 实时 CDC、在途 PII 脱敏、目标端有 dbt/SQL 能力 | 天然契合:E + tiny t + L;大 T 归目标端 |
SeaTunnel 天然适合 EtLT——不是因为它声称这个标签,而是因为 Source/Transform/Sink 三层分离、当前内置 Transform 的能力边界和明确的"EL(T)"定位都指向同一件事:快速移动数据,在传输途中轻量净化,把重活留给目标系统。
延伸阅读
- Apache SeaTunnel — About — 官方 EL(T) 定位说明(在页面 "SeaTunnel Work Flowchart" 小节)
- SeaTunnel Transform Connectors — 内置轻量 Transform 算子一览
- dbt — EtLT 中大 T 的标准搭档
- SeaTunnel API Deep Dive — Transform map 接口单行约束详解

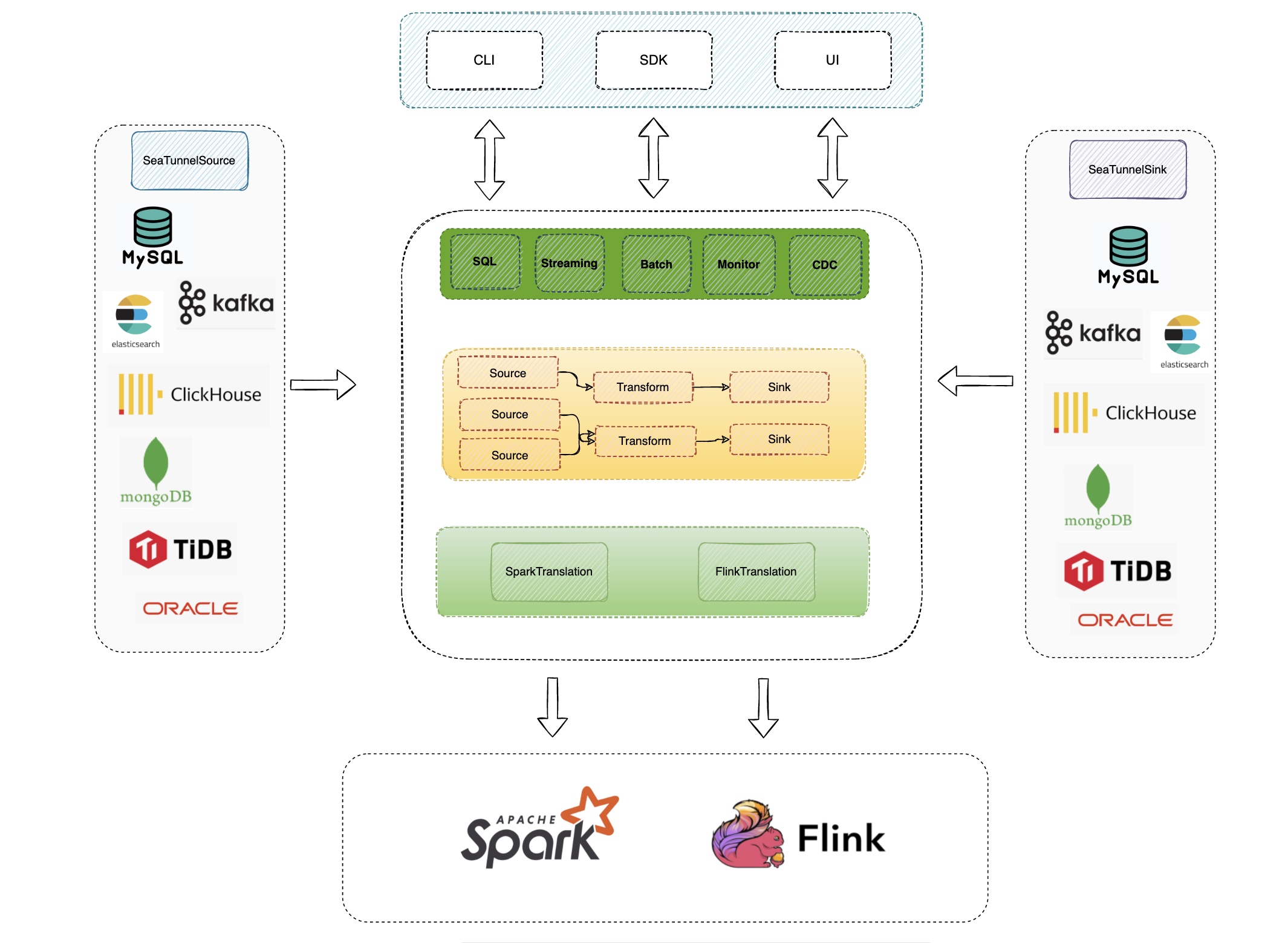
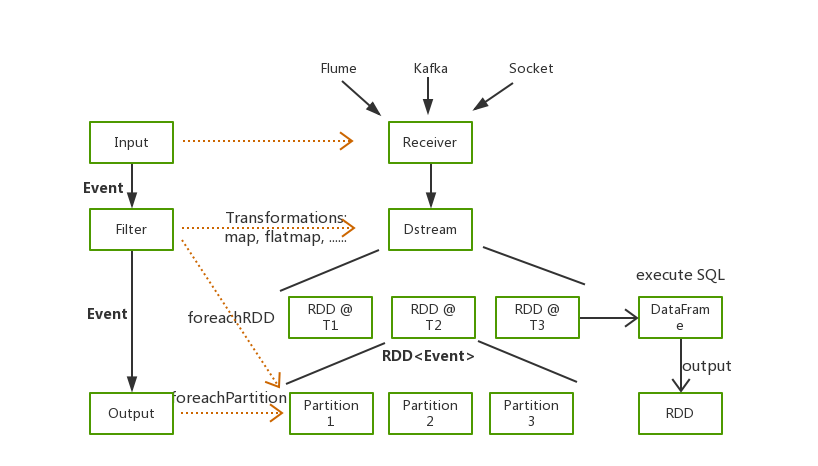
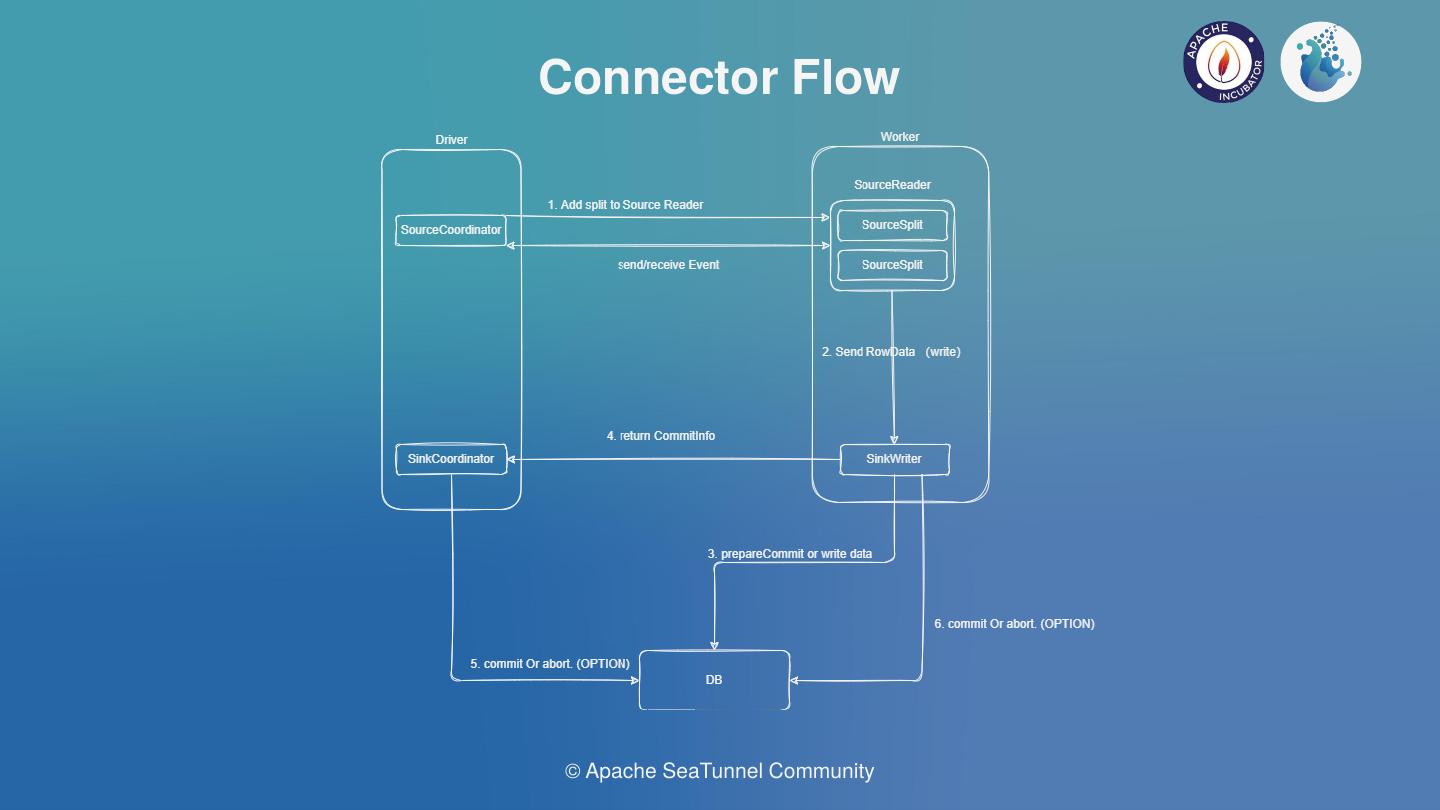
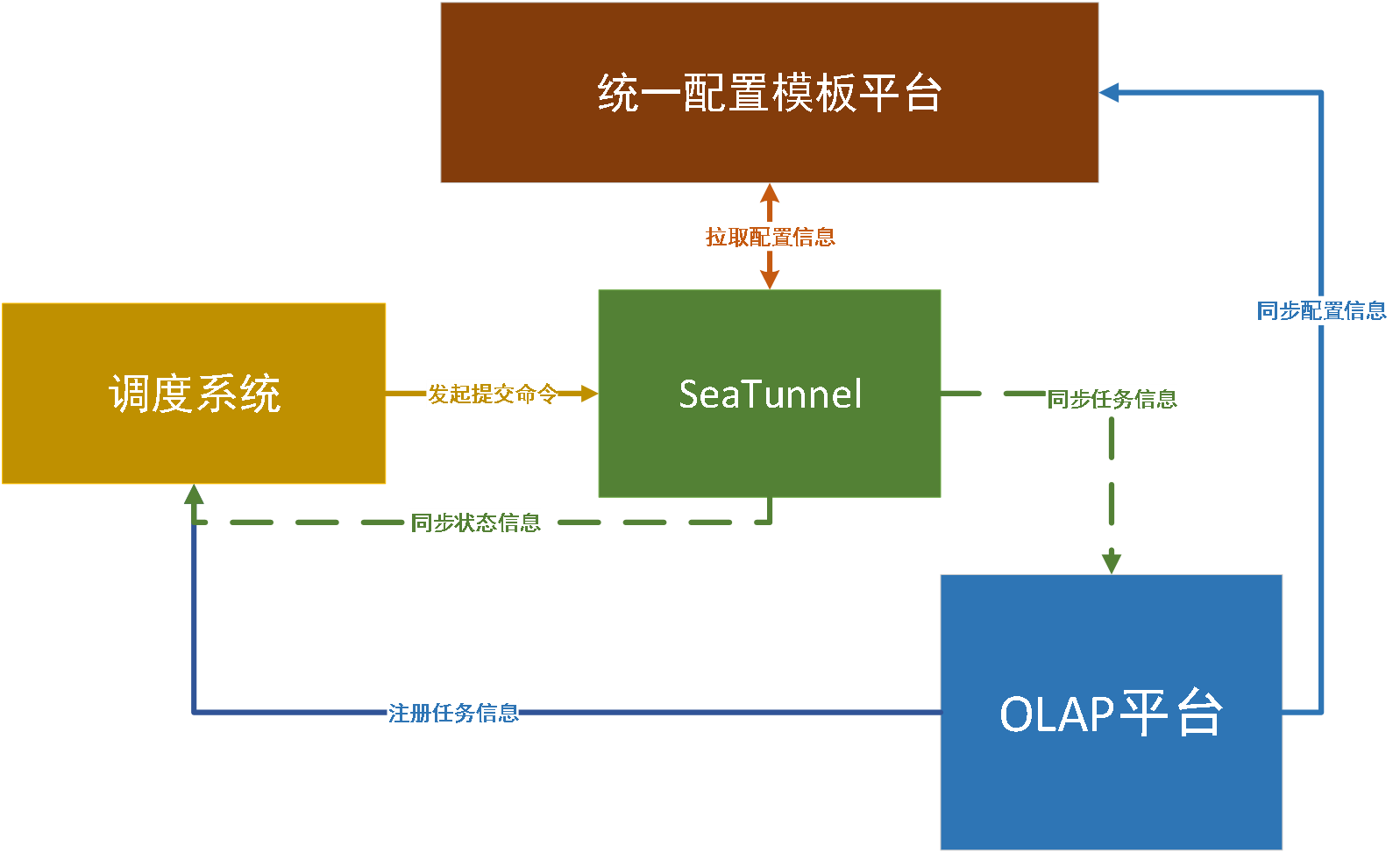
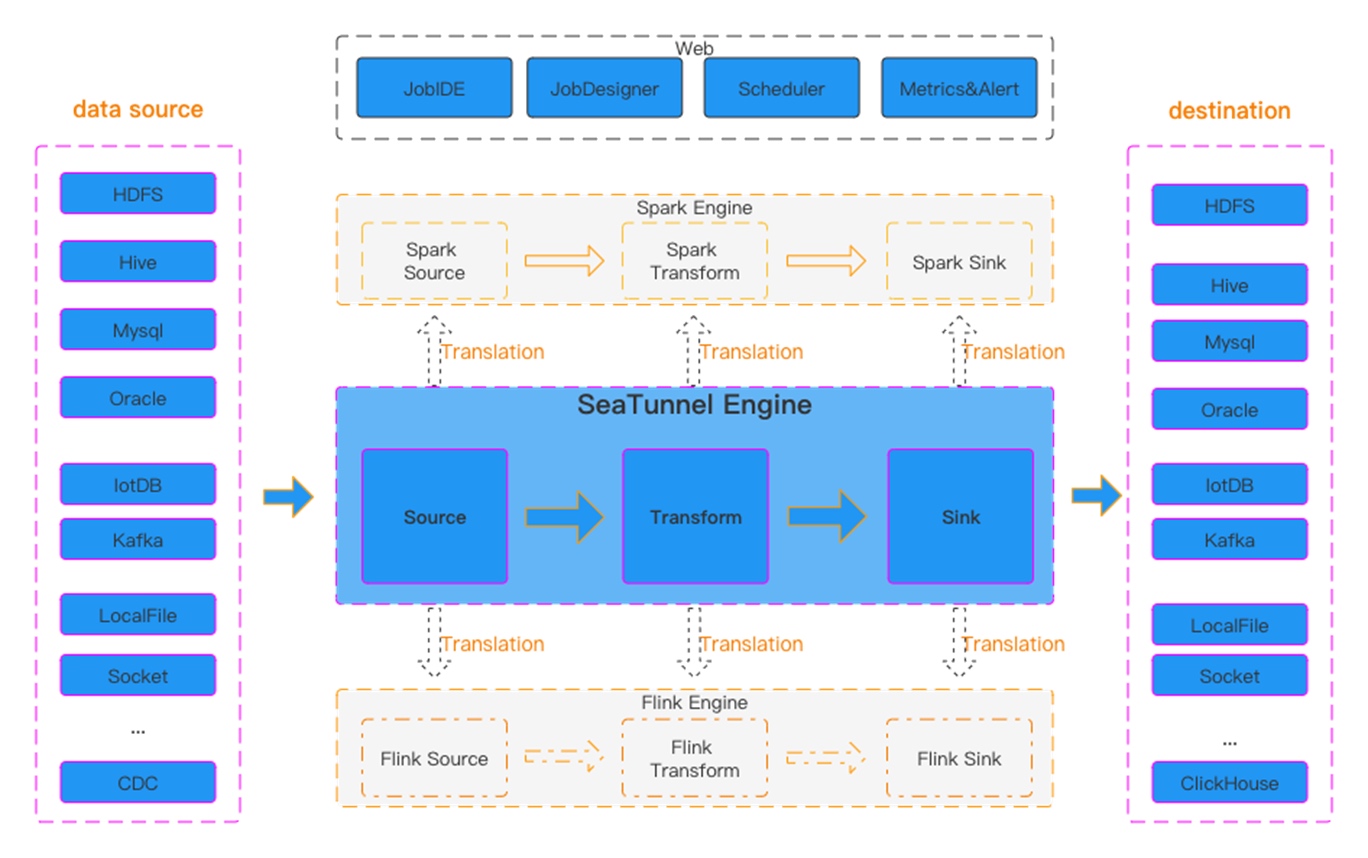 图一 Seatunnel工作流图
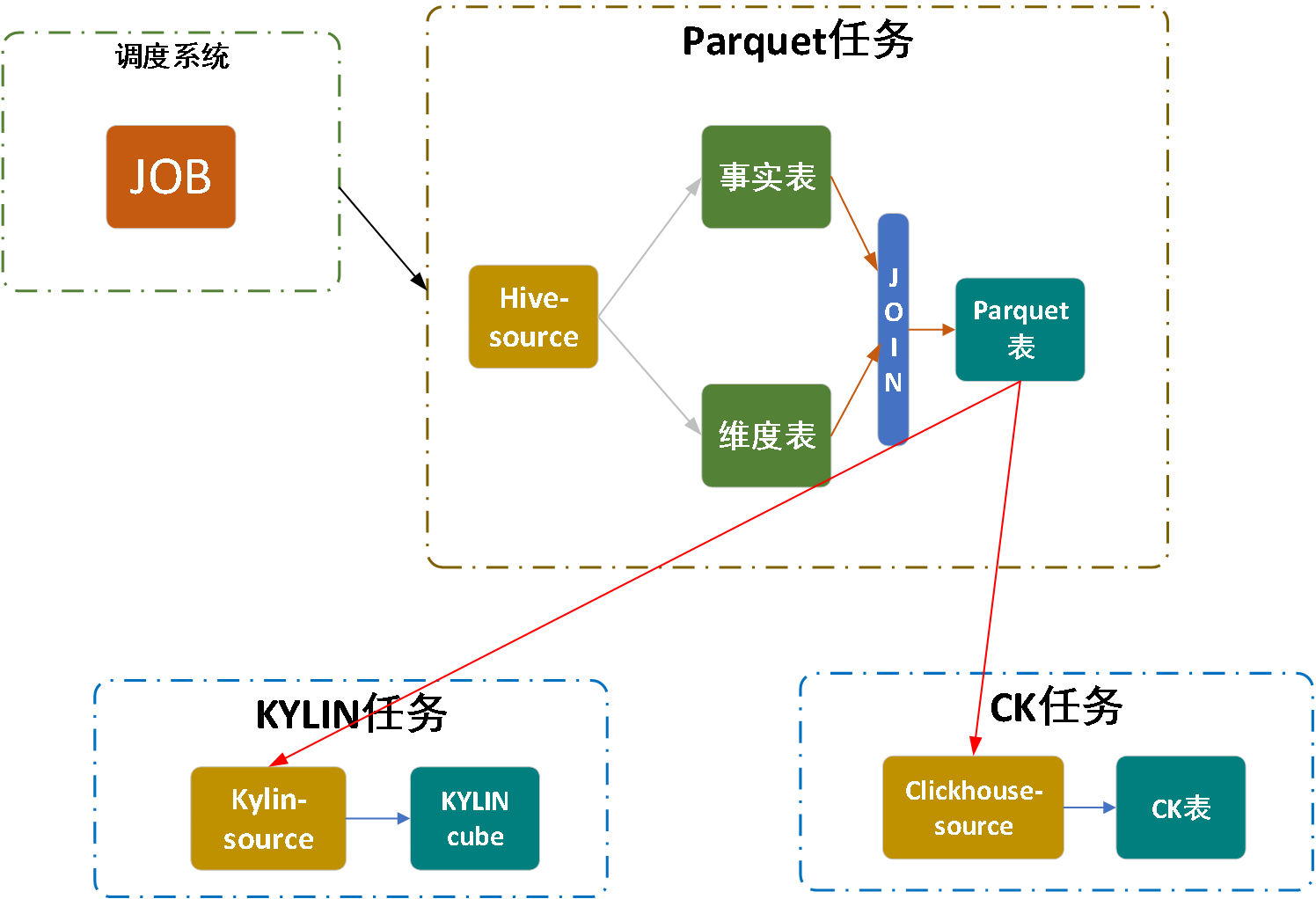
图一 Seatunnel工作流图 图二 数据同步日志信息
图二 数据同步日志信息


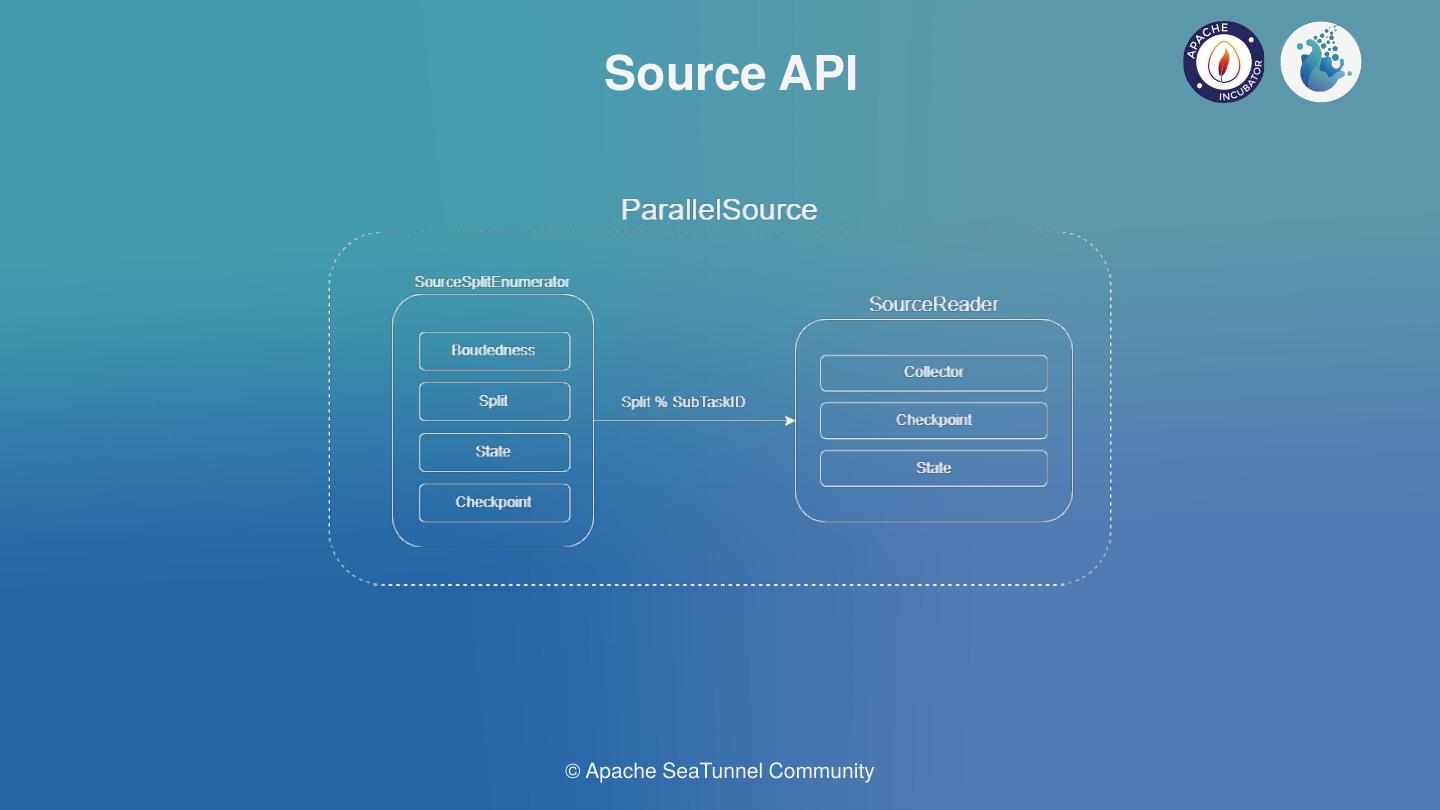
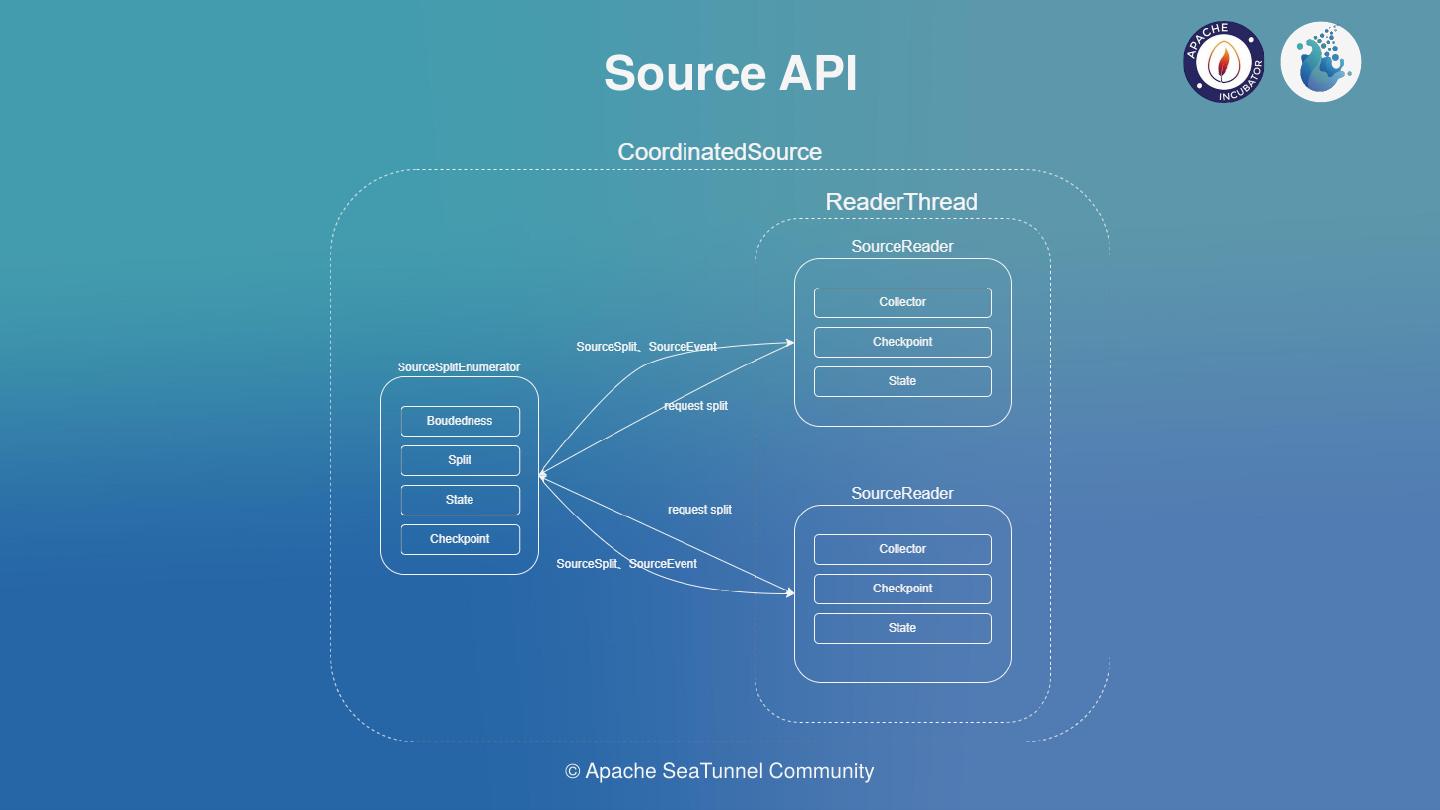
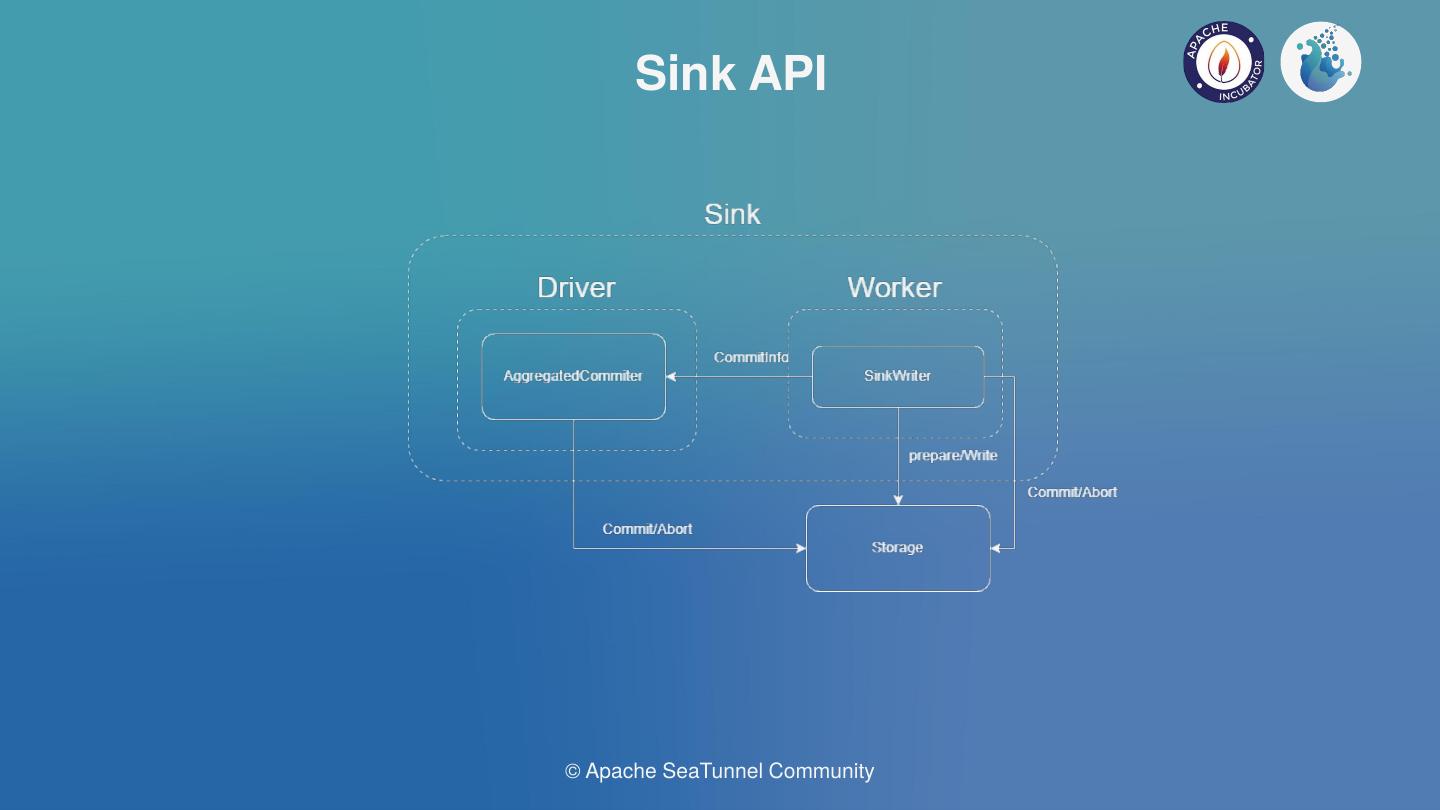


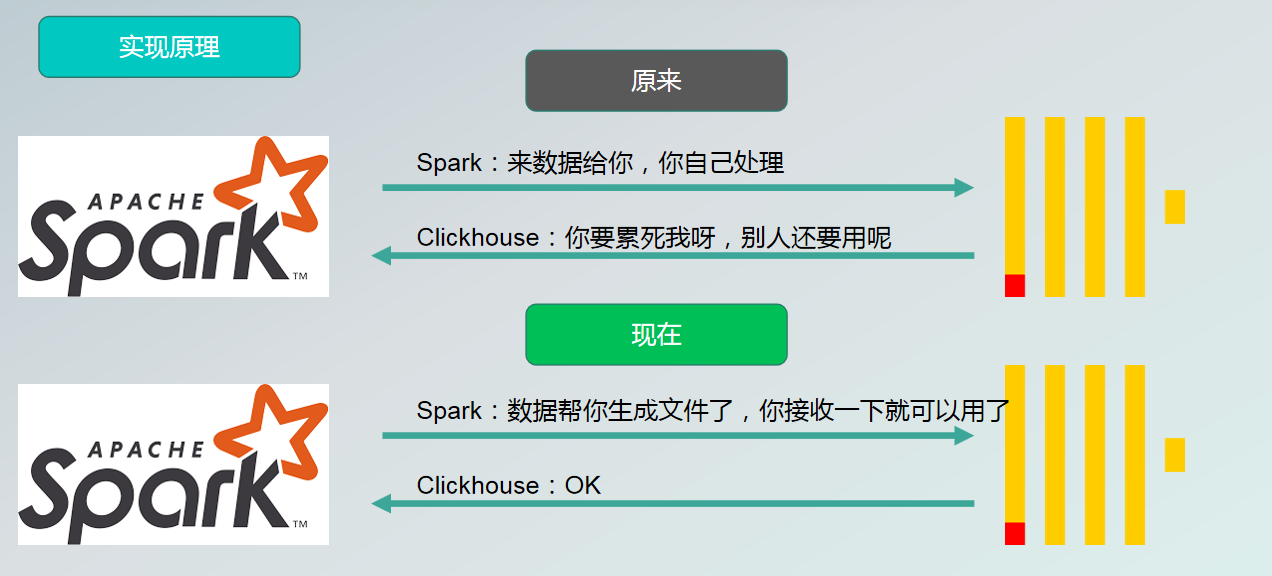
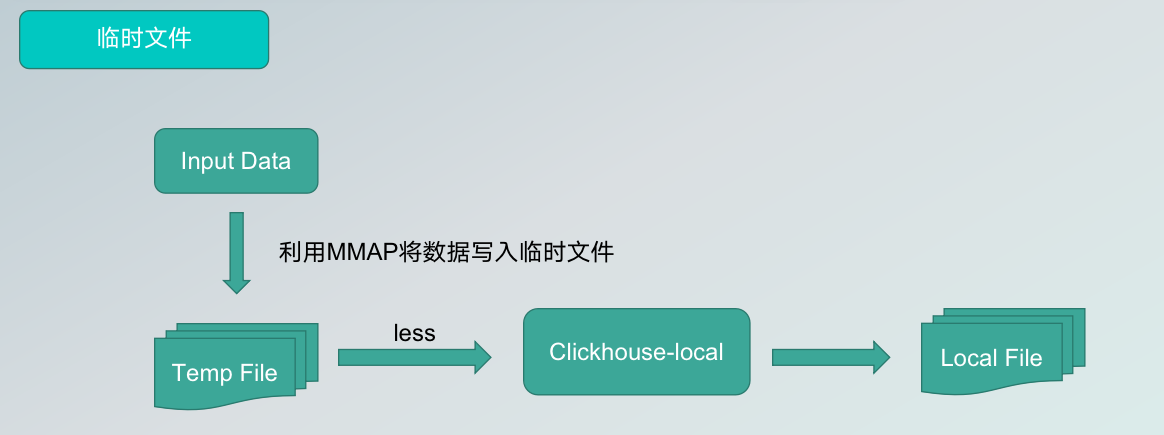
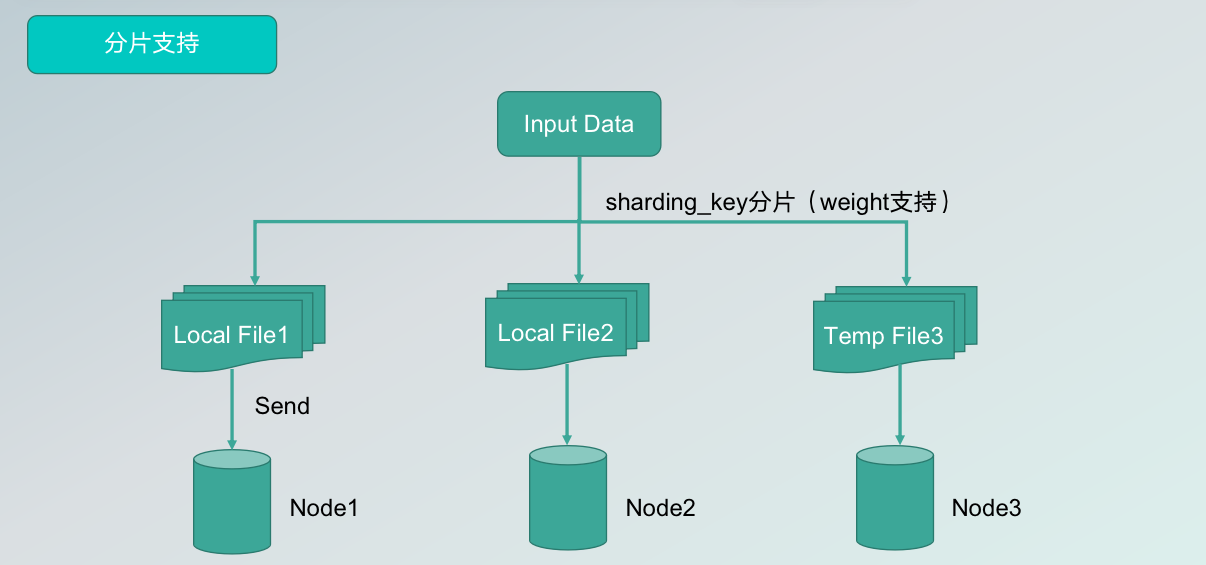

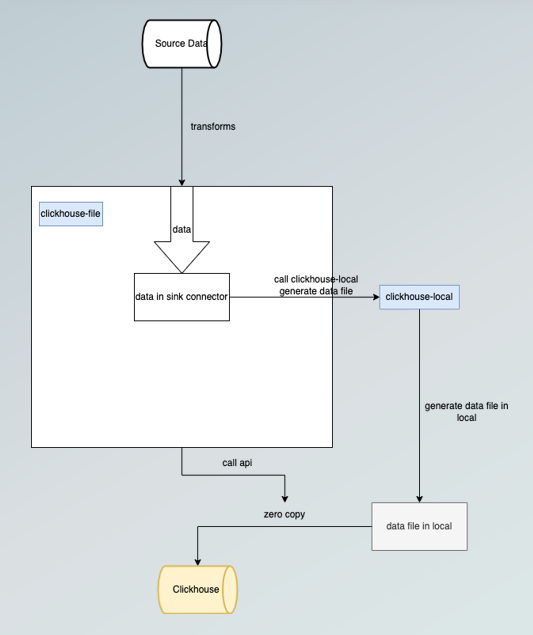
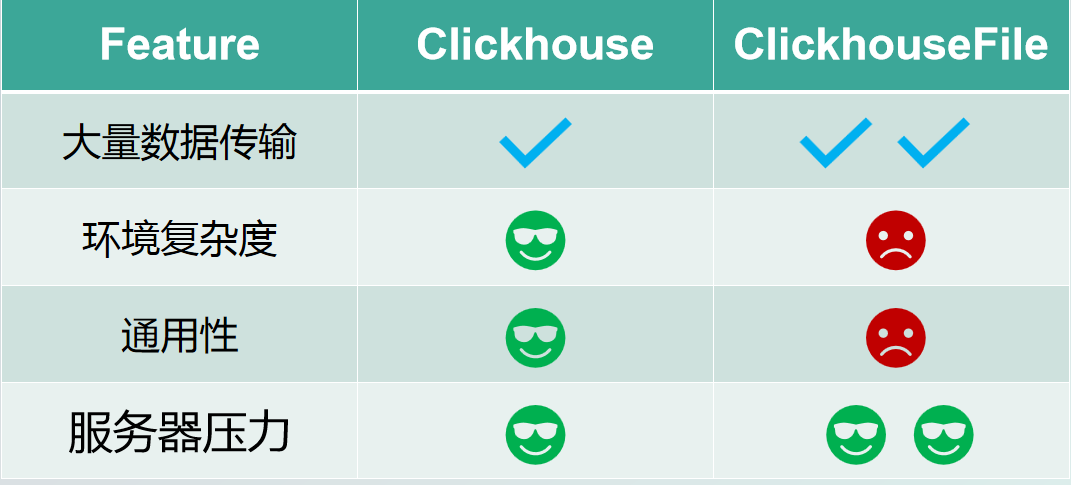


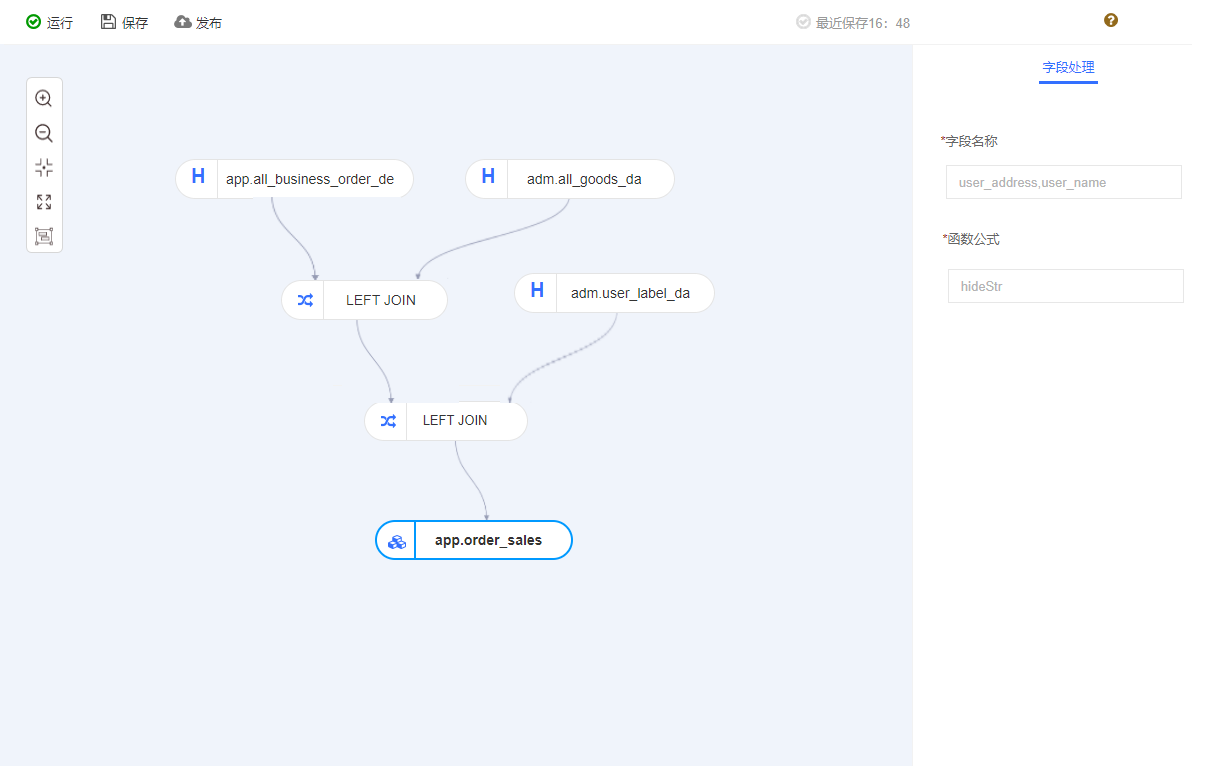
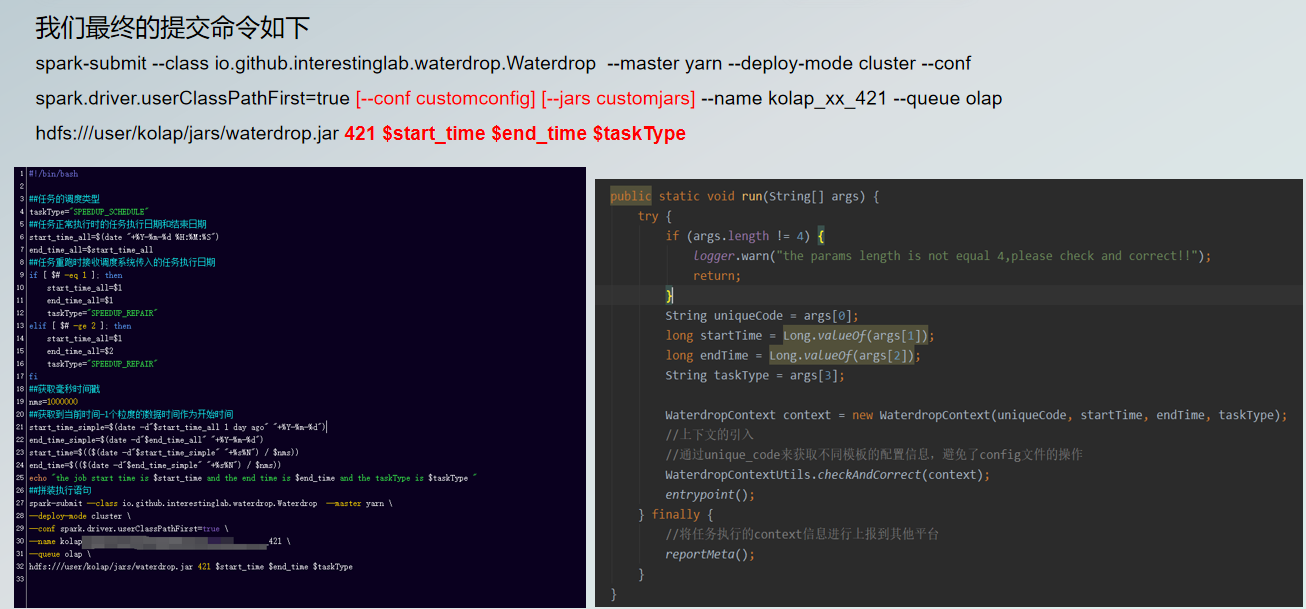










 运行过程中会产生Spark日志,运行成功和运行中错误都可以在日志中查看。
运行过程中会产生Spark日志,运行成功和运行中错误都可以在日志中查看。