In large-scale data integration, the throughput bottleneck is often not the data pipeline itself, but the “metadata path”: loading connector JARs during startup, managing state and recovery during runtime, and fetching schemas/partitions from external systems (databases, Hive Metastore, etc.) while initializing jobs. Once job concurrency reaches thousands (or more), these seemingly small operations can easily turn into cluster-wide pressure.
Apache SeaTunnel Engine (Zeta) caches high-frequency, reusable, and expensive metadata on the engine side, and combines it with distributed storage and lifecycle cleanup. This is a key reason why the engine can run massive numbers of sync jobs concurrently with better stability.
Why metadata becomes the bottleneck
When you start a huge number of small jobs in parallel, the most common metadata bottlenecks usually come from three areas:
- Class loading and dependency isolation: creating a dedicated ClassLoader per job can repeatedly load the same connector dependencies and quickly raise JVM Metaspace pressure.
- State and recoverability: checkpoints, runtime state, and historical job information can become heavy in both memory and IO without tiered storage and automatic cleanup.
- External schema/catalog queries: repeated schema and partition lookups can overload databases or Hive Metastore and lead to instability.
Below is a practical breakdown of SeaTunnel’s approach, together with configuration tips you can apply in production.
1) ClassLoader caching to reduce Metaspace pressure
When many jobs reuse the same set of connectors, frequent creation/destruction of class loaders causes Metaspace churn and can even lead to metaspace-related OOMs. SeaTunnel Engine provides classloader-cache-mode to reuse class loaders across jobs and reduce repeated loads.
Enable it in seatunnel.yaml (it is enabled by default; re-enable it if you previously turned it off):
seatunnel:
engine:
classloader-cache-mode: true
When it helps most:
- High job concurrency and frequent job starts, with a relatively small set of connector types.
- You observe consistent Metaspace growth or class-loading related memory alerts.
Notes:
- If your cluster runs with a highly diverse set of connectors, caching increases the amount of resident metadata in Metaspace. Monitor your Metaspace trend and adjust accordingly.
2) Distributed state and persistence for recoverability
SeaTunnel Engine’s fault tolerance is built on the Chandy–Lamport checkpoint idea. For both performance and reliability, it uses Hazelcast distributed data structures (such as IMap) for certain runtime information, and relies on external storage (shared/distributed storage) for durable recovery.
In practice, you will usually care about three sets of settings:
(1) Checkpoint parameters
seatunnel:
engine:
checkpoint:
interval: 300000
timeout: 10000
If your job config (env) specifies checkpoint.interval/checkpoint.timeout, the job config takes precedence.
(2) IMap backup and persistence (recommended for production)
For multi-node clusters, configure at least backup-count to reduce the risk of losing in-memory information when a node fails. If you want jobs to be automatically recoverable after a full cluster stop/restart, consider enabling external persistence for IMap as well.
For details, see:
/docs/seatunnel-engine/deployment/docs/seatunnel-engine/checkpoint-storage
(3) Automatic cleanup of historical job information
SeaTunnel stores completed job status, counters, and error logs in IMap. As the number of jobs grows, memory usage will grow too. Configure history-job-expire-minutes so expired job information is evicted automatically (default is 1440 minutes, i.e., 1 day).
seatunnel:
engine:
history-job-expire-minutes: 1440
3) Catalog/schema metadata caching to reduce source-side pressure
When many jobs start concurrently, schema/catalog requests (table schema, partitions, constraints, etc.) can turn into a “silent storm”. SeaTunnel applies caching and reuse patterns in connectors/catalogs to reduce repeated network round-trips and metadata parsing overhead.
- JDBC sources: startup typically fetches table schemas, types, and primary keys for validation and split planning. For large fan-out startups, avoid letting every job repeatedly fetch the same metadata (batch job starts or pre-warming can help).
- Hive sources: Hive Metastore is often a shared and sensitive service. Reusing catalog instances and already-loaded database/table/partition metadata helps reduce Metastore pressure, especially for highly partitioned tables.
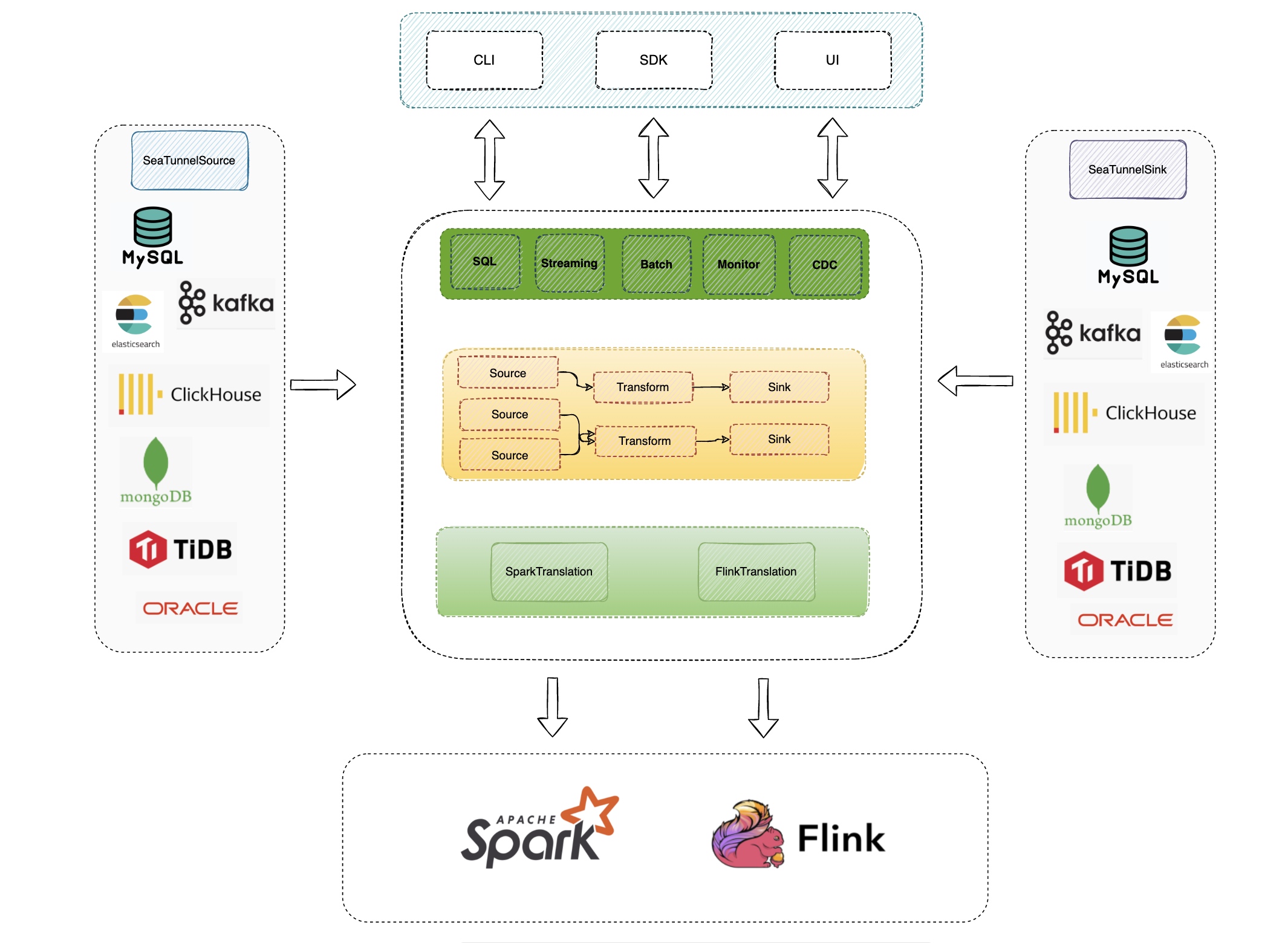
How this differs from Flink/Spark: optimized for “massive small jobs”
Flink is primarily designed for long-running streaming jobs and complex operator state; Spark is job/context oriented for batch processing. For the “tens of thousands of independent small jobs” goal, SeaTunnel Engine focuses on pushing reusable metadata down to the engine layer: minimizing repeated loads, minimizing repeated external queries, and managing the lifecycle of historical job metadata to keep the cluster stable under high concurrency.
Production checklist
- Enable reasonable backups: in production, set
backup-count >= 1and evaluate IMap persistence if you need automatic recovery after full restarts. - Limit connector diversity: keeping connector combinations relatively stable improves the benefit of
classloader-cache-mode. - Monitor metadata-related signals: besides JVM metrics, watch checkpoint latency/failure rate, Hazelcast memory usage, IMap size and growth, and historical job accumulation.
- Set eviction policies: tune
history-job-expire-minutesto balance observability and long-term memory safety.